淘宝的评论归纳是如何做到的?
按投票排序
按时间排序
9 个回答
PS:语义分析的概要过程大家可以去程序员杂志七月刊上阅读
作为这个产品技术团队之一,简单说下这个过程:
1,按类目特征,拉取这个类目下的评论,进行分词,统计词频;
2,对词进行聚类,包含常用的LDA,结合本体库,将词进行归类和分类,建立语料库;(分类是最重要的一步,比如服装类目下学院风、淑女、熟女、休闲等都会归为款式这类)
3,属性情感搭配,建立属性词和情感词的连接关系,判断分句的情感;
4,属性词+情感词转换到属性类的情感,对句子进行位置标记;
5,将属性情感和位置标记结果build到搜索中,便于根据标签反向检索内容。
借用一句话:产品从0到1是很容易的,但是将1做到100确实个不断优化的过程,期待对这方面有兴趣的人给予建议和指导,也大大欢迎加入共建。
作为这个产品技术团队之一,简单说下这个过程:
1,按类目特征,拉取这个类目下的评论,进行分词,统计词频;
2,对词进行聚类,包含常用的LDA,结合本体库,将词进行归类和分类,建立语料库;(分类是最重要的一步,比如服装类目下学院风、淑女、熟女、休闲等都会归为款式这类)
3,属性情感搭配,建立属性词和情感词的连接关系,判断分句的情感;
4,属性词+情感词转换到属性类的情感,对句子进行位置标记;
5,将属性情感和位置标记结果build到搜索中,便于根据标签反向检索内容。
借用一句话:产品从0到1是很容易的,但是将1做到100确实个不断优化的过程,期待对这方面有兴趣的人给予建议和指导,也大大欢迎加入共建。

周颖、知乎用户、enjoy Yang
等人赞同
我是一名大四的学生,在去年暑假的时候我们实验室为一家公司做了一个导购网站,其中用户评论挖掘这部分是一个特点,当时淘宝、京东等各大电商网站还没有或者刚刚开始注意到用户评论的这个点。我做的就是用户评论挖掘这一部分,主要是对每一件商品的每一条评论进行处理,最后得到每件商品的优缺点(以标签的方式呈现,算是短摘要)以及关于该商品的优缺点长摘要(摘要是根据每件商品下的评论得到的,较客观)。主要步骤是:
1、得到每件商品的所有评论。
2、对每条评论进行分词
3、对分词后的词语配合本地的词库进行聚类,形成语料库。这一步说的简单点就是将所有的同义词归为一类。比方说,价格 价位 价钱 售价归为价格这一类。
4、建立情感词,主要是形容词和副词的情感语料库。
5、根据情感词以及情感词位置判断分句的情感取向。
6、标记属性词和情感词的位置,为以后高亮显示做准备。
另外,我们还做了商品推荐、评论质量排序等功能。由于我们只是做了手机、平板电脑两种商品,所以较简单一些,其中一些可能还不够准确。演示地址http://www.daxiashuo.com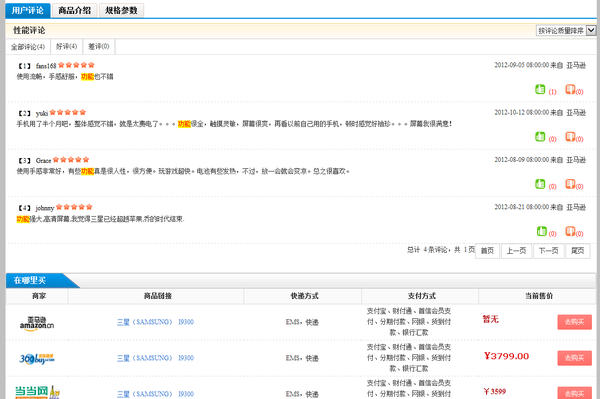
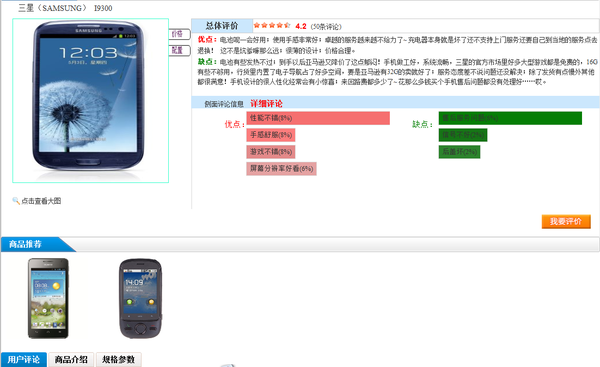
1、得到每件商品的所有评论。
2、对每条评论进行分词
3、对分词后的词语配合本地的词库进行聚类,形成语料库。这一步说的简单点就是将所有的同义词归为一类。比方说,价格 价位 价钱 售价归为价格这一类。
4、建立情感词,主要是形容词和副词的情感语料库。
5、根据情感词以及情感词位置判断分句的情感取向。
6、标记属性词和情感词的位置,为以后高亮显示做准备。
另外,我们还做了商品推荐、评论质量排序等功能。由于我们只是做了手机、平板电脑两种商品,所以较简单一些,其中一些可能还不够准确。演示地址http://www.daxiashuo.com
 知乎用户,手写客论坛:http://shouxieke.net
知乎用户,手写客论坛:http://shouxieke.net
收起
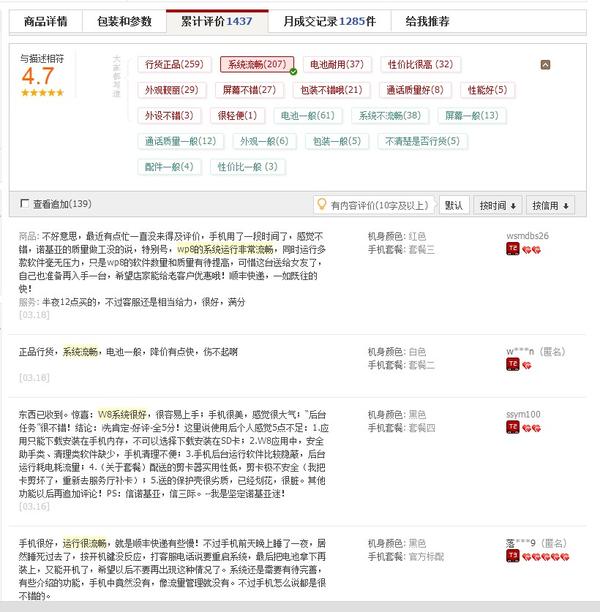
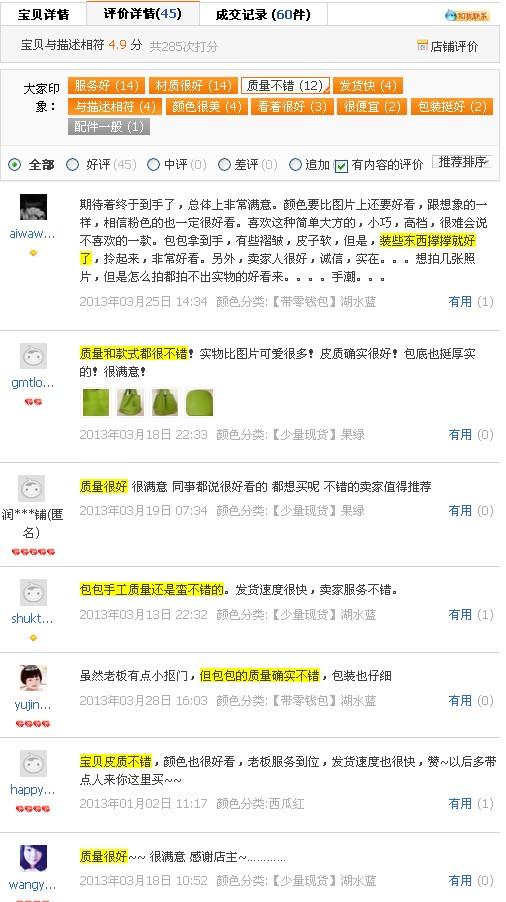
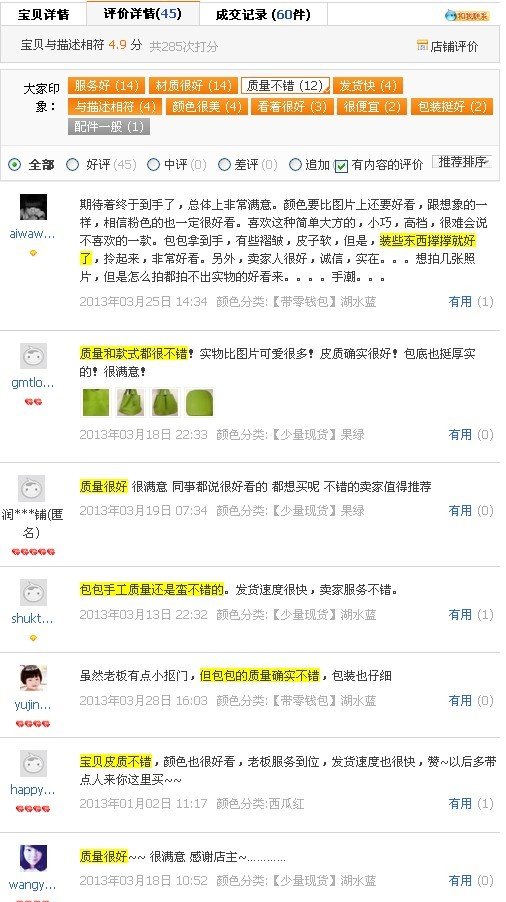
根据电话咨询淘宝客服得知,同一个关键词或者同一个意思的词语达到8个就会出现“大家印象”
还是根据关键词来进行的,不过现在还不够智能,很多时候会误读买家的原意。
还是根据关键词来进行的,不过现在还不够智能,很多时候会误读买家的原意。
收到两天了,包包非常好,因为没里布,所以一看就是真皮的,摸起来都不一样,哈哈!不过我觉得掌柜的图片没拍好,有点显得生硬,实物漂亮可爱很多。很喜欢。。掌柜的祝福贺卡字好漂亮,以后看到喜欢的还来你这买!我这条评价就由于粗体字部分,就被归类为态度不好,不过过了几天就没有这个归类了,系统也在慢慢进化和升级,整体上我觉得这个功能还是很不错的。误读率还是比较小的,能较为全面地归纳买家评价。 显示全部
-
类似隐性的搜索引擎,关键字作为索引字段,高亮显示
分为两大部分,一是索引的创建,二是根据关键字进行搜索
创建索引
1.收集原文档(Document)
即用户添加的评论
2.将原文档传给分词组件(Tokenizer)
将评论分成一个个单独的词,去除标点符号,去除停词
3.将得到的词元(Token)传给语言处理组件(Linguistic Processor)
这里的语言处理组件会对相近词进行判断,比如题目里的“系统流畅”
4.得到的词(Term)传给索引组件(Indexer)
根据步骤3得到的词,由索引组件建立倒排列表
搜索
1.获取关键字
一般我们的搜索根据用户随意输入,这里对索引字段进行统计后排名靠前的展示,用户只要点击即可
2.使用创建索引时候的分词组件和语言处理组件对关键字进行转义
3.使用转义后的关键字从倒排列表中的索引进行匹配
4.匹配到的评论进行解析,和关键字相近词加上高亮标签,返回前端展示
以上,一个非淘宝人士的回答,如有雷同,纯属巧合
-
类似隐性的搜索引擎,关键字作为索引字段,高亮显示
分为两大部分,一是索引的创建,二是根据关键字进行搜索
创建索引
1.收集原文档(Document)
即用户添加的评论
2.将原文档传给分词组件(Tokenizer)
将评论分成一个个单独的词,去除标点符号,去除停词
3.将得到的词元(Token)传给语言处理组件(Linguistic Processor)
这里的语言处理组件会对相近词进行判断,比如题目里的“系统流畅”
4.得到的词(Term)传给索引组件(Indexer)
根据步骤3得到的词,由索引组件建立倒排列表
搜索
1.获取关键字
一般我们的搜索根据用户随意输入,这里对索引字段进行统计后排名靠前的展示,用户只要点击即可
2.使用创建索引时候的分词组件和语言处理组件对关键字进行转义
3.使用转义后的关键字从倒排列表中的索引进行匹配
4.匹配到的评论进行解析,和关键字相近词加上高亮标签,返回前端展示
以上,一个非淘宝人士的回答,如有雷同,纯属巧合
-
不知道具体的细节,怀疑用了共词分析,如果有很多评论都出现了“质量”和“不错” 两个词,则可以生成“质量不错”这个label。 进一步的,还需要建立同义词的网络,比如“不错”和“好”同义,因而某个评论中出现“质量”和“好”,则也可以归入这类。 这个feature的实现其实是一个句子的聚类。


我觉着可能会用到Latent Semantic Analysis。
该算法具体实现细节不是很了解,可是在一个项目中(Latent Semantic Analysis Helps Assess Health Concerns of Military Personnel)发现此算法专门用来归纳不可能结构化的回答,也就是那些open-ended reponses.这正好也符合了买家评论的特性。
该算法具体实现细节不是很了解,可是在一个项目中(Latent Semantic Analysis Helps Assess Health Concerns of Military Personnel)发现此算法专门用来归纳不可能结构化的回答,也就是那些open-ended reponses.这正好也符合了买家评论的特性。