在前面的演示中,我们都是基于一次http查询,每次查询都要建立http的三次握手请求,这样比较耗费性能!因此ES给我们提供了基本的批量查询功能,例如如下的查询,注意里面的index是可以任意指明的,不需要都一致
【01】批量查询之_mget操作,如下查询表示指定同时查询索引testdb下的两个type(job1和job2)里面的数据:注意我们可以在这里指定不同的索引,例如testdb1,testdb2;另外这里要指定doc关键词,表示我查询的是一个文档:
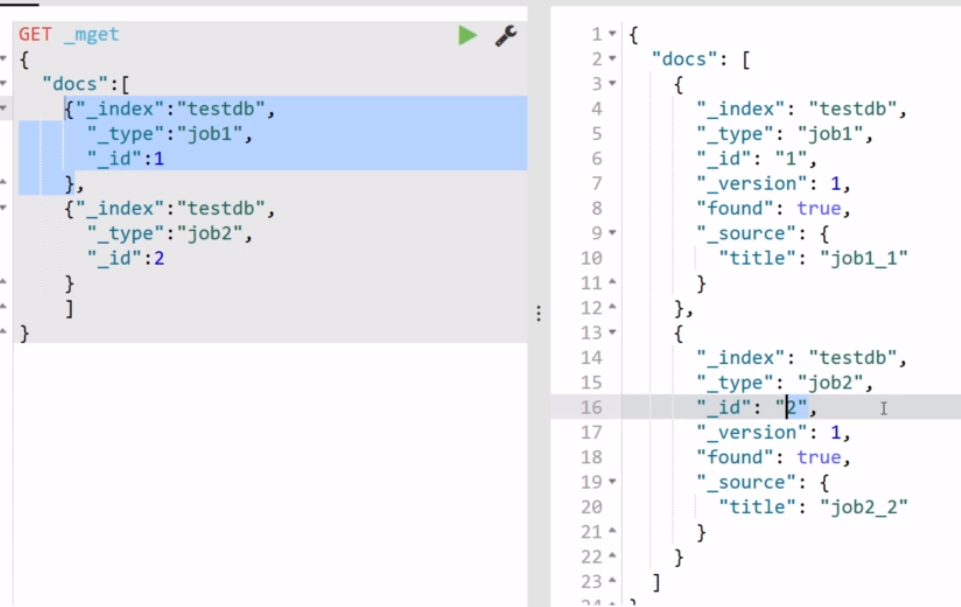
【02】查询同一个index下面不同type的数据,我们直接在url地址中先指明index为testdb,然后在里面就不用指明了:
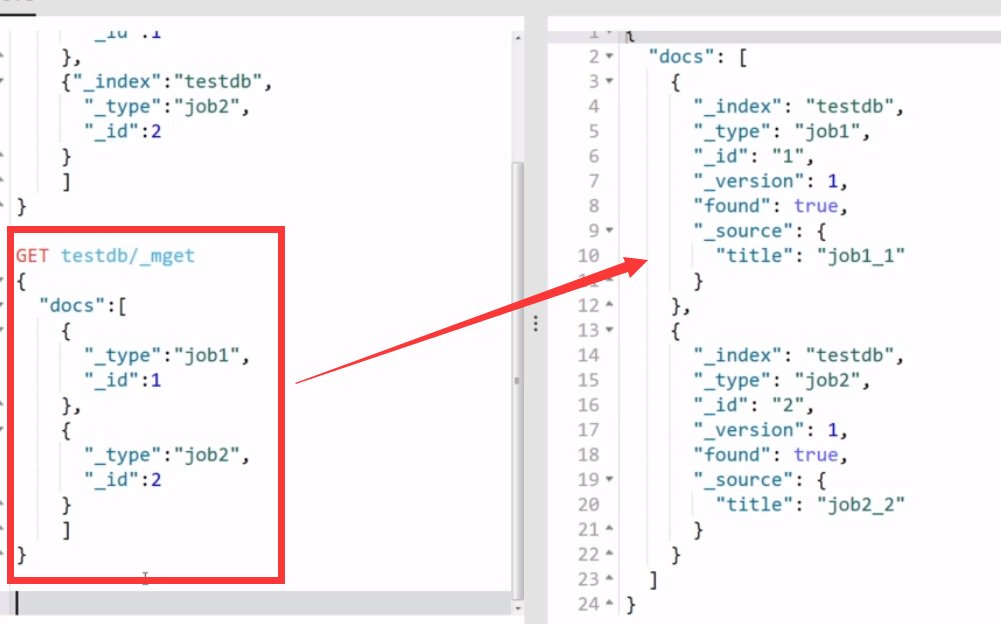
【03】如果连type都是一样的,那就只需要查询id了,依然不要忘记使用doc关键词
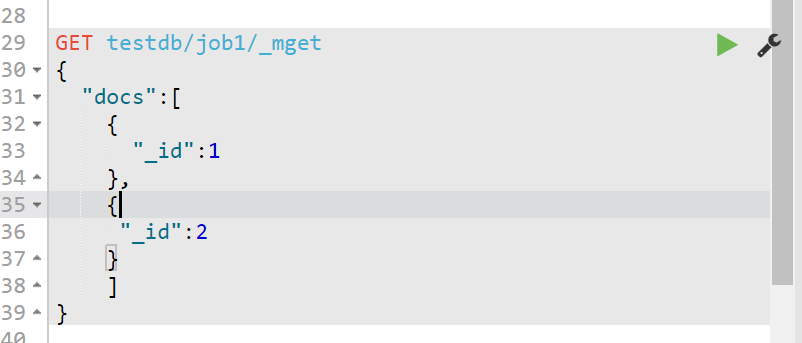
我们还可以基于上面的情形继续简写,下面这种写法就更加简便了

需要注意的是:上面使用docs指定时,它对应的value是一个数组,数组里面的每个元素都是字典。
【04】ES的bulk批量操作 来看看网络上的一张截图:

相当于就是使用了元数据来完成数据的批量导入,每导入一条数据,由两行构成,一条是元信息,另一条是数据行,来看看笔者实际的例子:

注意上面的数据格式一定要做成一行,不要优化成json数据格式
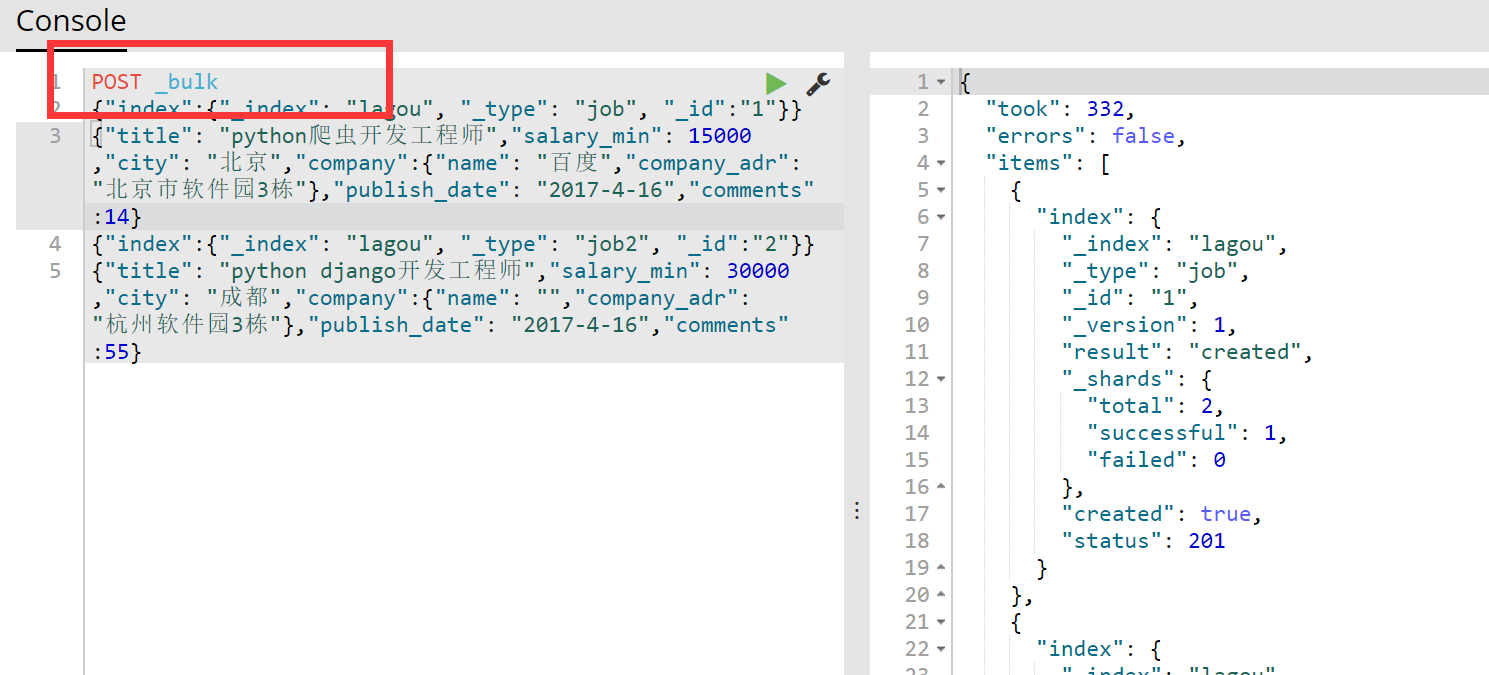
示例1:使用POST来完成bulk操作演示:蓝色的为元数据信息:
{"index":{"_index": "lagou", "_type": "job", "_id":"1"}}
{"title": "python爬虫开发工程师","salary_min": 15000,"city": "北京","company":{"name": "百度","company_adr": "北京市软件园3栋"},"publish_date": "2017-4-16","comments":14}
{"index":{"_index": "lagou", "_type": "job2", "_id":"2"}}
{"title": "python django开发工程师","salary_min": 30000,"city": "成都","company":{"name": "","company_adr": "杭州软件园3栋"},"publish_date": "2017-4-16","comments":55}
运行截图如下所示:记住在上面使用POST _bulk
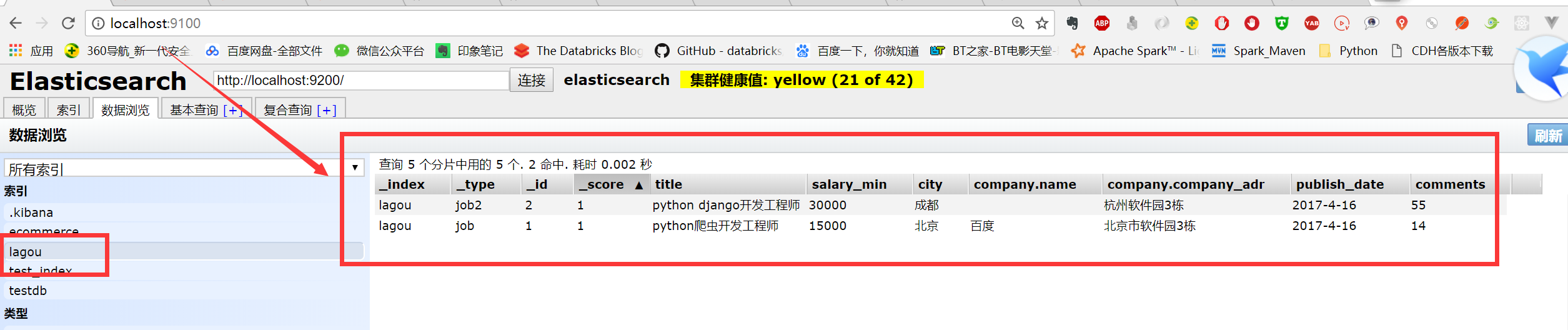
我们去head插件中看看,可以看到它自动为我们创建了所以index,而且还插入了两条数据:
注意事项:
关于bulk操作的解说:
1.第一行是操作,例如index操作,后面的value是元数据,指明index操作是针对哪个索引,哪个type,哪个id进行的;
2.第二行才是数据
但是要注意的是delete操作只有一行数据,因为只需要提供一个id即可
下面的create操作和update操作都是两行数据。
示例如下:
