上次给大家介绍了如何利用scrapy进行图片的抓取及保存,抓一些美女图片可能就遗忘在硬盘里了,实用性不是太强,今天来介绍一下如何使用scrapy进行文件下载。
网页分析
目标网站http://bj.wsbedu.com/php/showz-459-ry51p.html,
这是一个小学课件的网站中的其中一篇课文的ppt,今天就来实战如何通过爬虫把ppt拿下,看一下网页
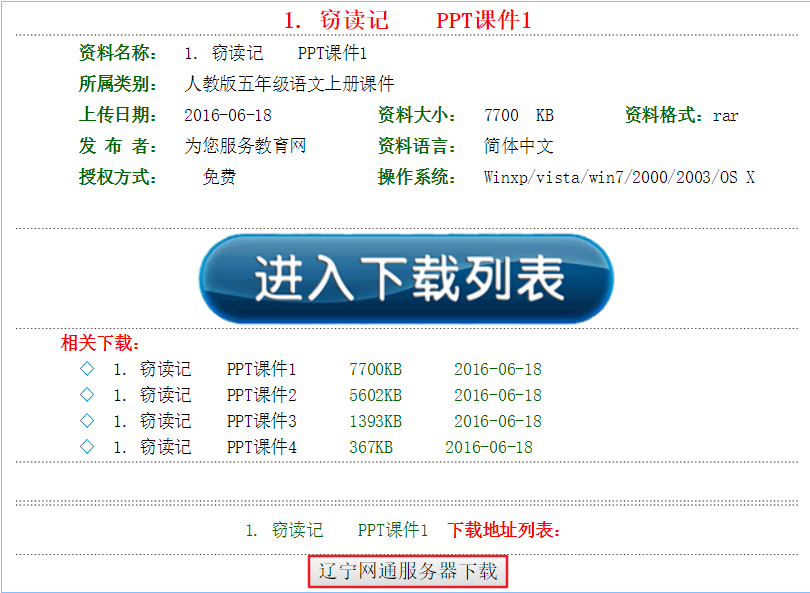
点击红框就可以进行下载,先利用浏览器走一遍,用fiddler抓取一下流程,

可以看出是一个post请求,看一下需要post哪些信息,
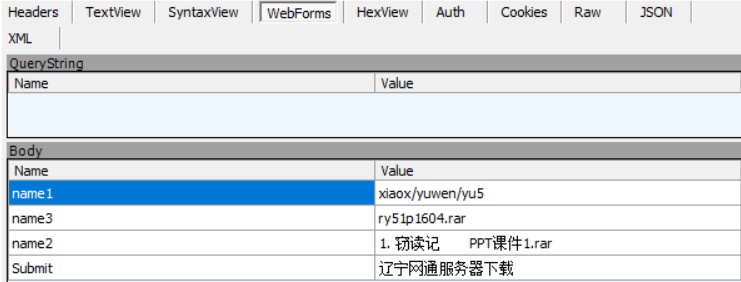
有下面几个值,接下来看一下网页结构,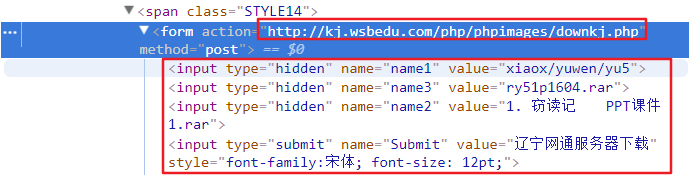
第一个红框中是我们请求的链接,第二个红框里是post的参数,分析到这里就可以着手写代码了。
代码部分
item,spider前面部分定义还是老样子,我只写了抓取一个课件的代码,抓取到的post参数,放在一个字典里作为item传出去。
data1 = response.xpath('//input[@name="name1"]/@value').extract_first()
data2 = response.xpath('//input[@name="name2"]/@value').extract_first()
......
item = KejianItem()
data = {'name1':data1,'name2':data2,'name3':data3,'Submit':data4}
item['data'] = data
item['file_urls'] = file_urls
item['res_url'] = response.url
这里我们不仅把下载文件的链接传出去了,而且还把网页链接传入item中,这将会在下面解释为什么。
之后就可以写pipelines代码了,scrapy为我们打造好了一个FilesPipeline类专门用来下载文件,
from scrapy.pipelines.files import FilesPipeline
import scrapy
class FilePipeline1(FilesPipeline):
def get_media_requests(self, item, info):
yield scrapy.FormRequest(url = item['file_urls'],formdata=item['data'],
headers={'Referer':item['res_url']},meta={'data':item['data']})
def file_path(self, request, response=None, info=None):
data = request.meta['data']
folder_name = data['name2']
filename = '{}'.format(folder_name)
return filename
导入FilesPipeline,写一个类继承它,第一个函数是下载文件的函数,因为是post请求,我们要用FormRequest,将data传入,然后加了headers,这是因为如果不加,网站会提示我们盗链了,就是这个样子,
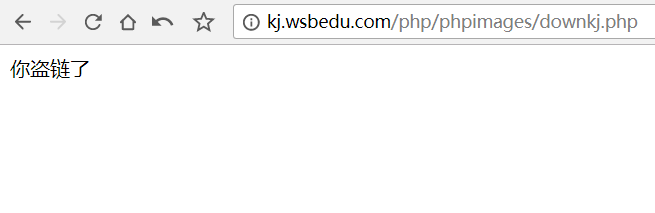
所以在headers中加上Referer参数,告诉网站我们就是从本网页来的,这样就可以正常下载了,也是为什么要把网页的链接也传入item,第二个函数是有关下载到本地的,将获取到的name2作为文件的名称,是这样子的《1. 窃读记 PPT课件1.rar》,在settings里把该pipelines激活,基本大功告成,运行结果:
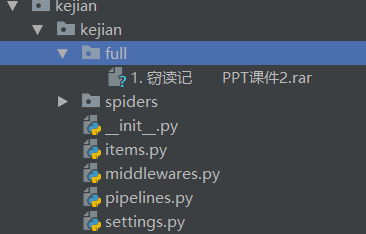
已经下载好了该文件。
我只是演示了一下如何下载一个ppt,若想下载多个只需调整一下代码即可,这样只要我们写个爬虫,文件就会自动进入电脑,比一个一个手动下载要快又省力。
大家也可以关注一下我的公众号噢,有精选的学习资源,和最新的爬虫及数据分析实战。
