python语言以容易入门,适合应用开发,编程简洁,第三方库多等等诸多优点,并吸引广大编程爱好者。但是也存在一个被熟知的性能瓶颈:python解释器引入GIL锁以后,多CPU场景下,也不再是并行方式运行,甚至比串行性能更差。注定这门语言在某些方面是有天花板的,对于一些并行要求高的系统,python可能不再成为首选,甚至是完全不考虑。但是事情也并不是绝对悲观的,我们已经看到有一大批人正在致力优化这个特性,新版本较老版本也有了一定改进,一些核心模块我们也可以选用其它模块开发等等措施。
1、python多线程编程
threading是python实现多线程编程的常用库,有两种方式可以实现多线程:1、调用库接口传入功能函数和参数执行;2、自定义线程类继承threading.Thread,然后重写__init__和run方法。
1、调用库接口传入功能函数和参数执行


import threading import queue import time ''' 实现功能:定义一个FIFO的queue,10个元素,3个线程同时来获取 ''' # 初始化FIFO队列 q = queue.Queue() for i in range(10): q.put(i) print("%s : Init queue,size:%d"%(time.ctime(),q.qsize())) # 线程功能函数,获取队列数据 def run(q,threadid): is_empty = False while not is_empty: if not q.empty(): data = q.get() print("Thread %d get:%d"%(threadid,data)) time.sleep(1) else: is_empty = True # 定义线程列表 thread_handler_lists = [] # 初始化线程 for i in range(3): thread = threading.Thread(target=run,args = (q,i)) thread.start() thread_handler_lists.append(thread) # 等待线程执行完毕 for thread_handler in thread_handler_lists: thread_handler.join() print("%s : End of progress"%(time.ctime()))
2、自定义线程类继承threading.Thread,然后重写__init__和run方法
和其它语言一样,为了保证多线程间数据一致性,threading库自带锁功能,涉及3个接口:
thread_lock = threading.Lock() 创建一个锁对象
thread_lock.acquire() 获取锁
thread_lock.release() 释放锁
注意:由于python模块queue已经实现多线程安全,实际编码中,不再需要进行锁的操作,此处只是进行编程演示。
import threading import queue import time ''' 实现功能:定义一个FIFO的queue,10个元素,3个线程同时来获取 queue线程安全的队列,因此不需要加 thread_lock.acquire() thread_lock.release() ''' # 自定义一个线程类,继承threading.Thread,重写__init__和run方法即可 class MyThread(threading.Thread): def __init__(self,threadid,name,q): threading.Thread.__init__(self) self.threadid = threadid self.name = name self.q =q print("%s : Init %s success."%(time.ctime(),self.name)) def run(self): is_empty = False while not is_empty: thread_lock.acquire() if not q.empty(): data = self.q.get() print("Thread %d get:%d"%(self.threadid,data)) time.sleep(1) thread_lock.release() else: is_empty = True thread_lock.release() # 定义一个锁 thread_lock = threading.Lock() # 定义一个FIFO队列 q = queue.Queue() # 定义线程列表 thread_name_list = ["Thread-1","Thread-2","Thread-3"] thread_handler_lists = [] # 初始化队列 thread_lock.acquire() for i in range(10): q.put(i) thread_lock.release() print("%s : Init queue,size:%d"%(time.ctime(),q.qsize())) # 初始化线程 thread_id = 1 for thread_name in thread_name_list: thread = MyThread(thread_id,thread_name,q) thread.start() thread_handler_lists.append(thread) thread_id += 1 # 等待线程执行完毕 for thread_handler in thread_handler_lists: thread_handler.join() print("%s : End of progress"%(time.ctime()))
另外多线程还涉及事件和信号量,很简单,就不再贴代码了
用threading.Event 实现线程间通信,使用threading.Event可以使一个线程等待其他线程的通知,我们把这个Event传递到线程对象中,
涉及接口:set()、isSet()、Event()、clear()
如果在主机执行IO密集型任务的时候再执行这种类型的程序时,计算机就有很大可能会宕机。
这时候就可以为这段程序添加一个计数器功能,来限制一个时间点内的线程数量。
涉及接口:threading.Semaphore(5)、acquire()、release()
2、python多线程机制分析
讨论前,我们先梳理几个概念:
并行和并发
并发的关键是你有处理多个任务的能力,不一定要同时。而并行的关键是你有同时处理多个任务的能力。我认为它们最关键的点就是:是否是『同时』,或者说并行是并发的子集。
GIL
GIL:全局解释锁,python解释器级别的锁,为了保证程序本身运行正常,例如python的自动垃圾回收机制,在我们程序运行的同时,也在进行垃圾清理工作。
下图试图模拟A进程中3个线程的执行情况:
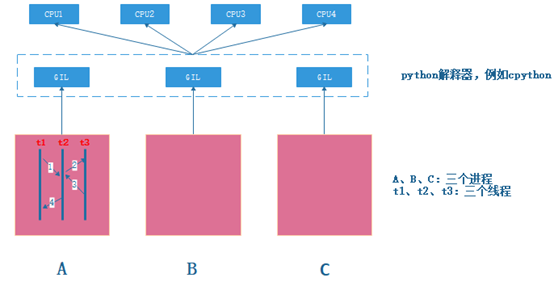
1、 t1、t2、t3线程处于就绪状态,同时向python解释器获取GIL锁
2、 假设t1获取到GIL锁,被python分配给任意CPU执行,处于运行状态
3、 Python基于某种调度方式(例如pcode),会让t1释放GIL锁,重新处于就绪状态
4、 重复1步骤,假设这时t2获取到GIL锁,运行过程同上,被python分配给任意CPU执行,处于运行状态,Python基于某种调度方式(例如pcode),会让t2释放GIL锁,重新处于就绪状态
5、 最后可以推得t1、t2、t3按如下1、2、3、4方式串行运行
因此,尽管t1、t2、t3为三个线程,理论上可以并行运行,但实际上python解释器引入GIL锁以后,多CPU场景下,也不再是并行方式运行,甚至比串行性能更差,下面我们做个测试:
我们写两个计算函数,测试单线程和多线程的时间开销,代码如下:
import threading import time # 定义两个计算量大的函数 def sum(): sum = 0 for i in range(100000000): sum += i def mul(): sum = 0 for i in range(10000000): sum *= i # 单线程时间测试 starttime = time.time() sum() mul() endtime = time.time() period = endtime - starttime print("The single thread cost:%d"%(period)) # 多线程时间测试 starttime = time.time() l = [] t1 = threading.Thread(target = sum) t2 = threading.Thread(target = sum) l.append(t1) l.append(t2) for i in l: i.start() for i in l: i.join() endtime = time.time() period = endtime - starttime print("The mutiple thread cost:%d"%(period)) print("End of program.")
测试发现,多线程的时间开销居然比单线程还要大:

这个结果有点让人不可接受,那有没有办法优化?答案是有的,比如把多线程变成多进程,但是考虑到进程开销问题,实际编程中,不能开过多进程,下面是多进程测试代码:
''' 程序欲实现功能:定义1个CPU占用高函数,测试Python多进程执行效率 ''' import multiprocessing import time def mul(): sum = 0 for i in range(1000000000): sum *= i if __name__ == "__main__": start_time = time.time() # 执行两个函数 mul() mul() end_time = time.time() print("single proccess cost : %d" % (end_time - start_time)) start_time = time.time() #定义两个进程 l = [] p1 = multiprocessing.Process(target = mul) p1.start() l.append(p1) p2 = multiprocessing.Process(target = mul) p2.start() l.append(p2) #等待进程执行完毕 for p_list in l: p_list.join() end_time = time.time() print("Mutiple proccess cost : %d"%(end_time - start_time))
实际测试结果:
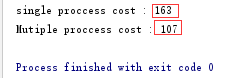
测试结果显示:单进程串行执行需要163秒,而双进程执行只需要107秒,显然执行效率更高。
另外进程+协程也可以提高一定性能,这里暂时不再深入分析。
有兴趣可以继续阅读下链接博客:http://cenalulu.github.io/python/gil-in-python/