# -*- coding:utf-8 -*- #多进程 import time import requests import multiprocessing from multiprocessing import Pool from bs4 import BeautifulSoup def job(url,header): r = requests.get(url,headers = header) content = r.text soup = BeautifulSoup(content,'html.parser') item = soup.select(".item") for i in item: print(i.select('.title')[0].text) if __name__ == "__main__": MAX_WOKER_NUM = multiprocessing.cpu_count() t1 = time.time() urls = ['https://movie.douban.com/top250?start={}&filter='.format(i) for i in range(0, 226, 25)] header = { "user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (" "KHTML, like Gecko) Chrome/79.0.3945.88 Safari/537.36" } p = Pool(MAX_WOKER_NUM) for url in urls: #apply_async是异步非阻塞式,不用等待当前进程执行完毕,随时跟进操作系统调度来进行进程切换, # 即多个进程并行执行,提高程序的执行效率 p.apply_async(job, args=(url,header)) p.close() p.join() print("耗时:", time.time() - t1)
上面的例子是爬取豆瓣Top250的电影名字总的耗时,其中涉及到了多进程的知识,在理解代码的过程中,查看了较多的资料,现在将所查看的一些资料记录下来。
(1)p.apply_async()和p.apply()的区别。
apply()的工作方式:阻塞主线程,并且一个一个按顺序执行子进程,等到全部子进程全部执行完毕后,继续执行apply()后面主进程的代码;
apply_asaync()的工作方式:非阻塞异步的,它不会等待子进程执行完毕,主进程会继续执行,它会根据系统调度来进行进程切换;
可根据代码的执行结果来进行理解,先看下apply().
# -*- coding:utf-8 -*- import time import multiprocessing def doIt(num): print("Process num is : %s" % num) time.sleep(1) print('process %s end' % num) if __name__ == '__main__': print('mainProcess start') #记录一下开始执行的时间 start_time = time.time() #创建三个子进程 pool = multiprocessing.Pool(3) print('Child start') for i in range(3): pool.apply(doIt,[i]) #pool.apply_async(doIt,[i])print('mainProcess done time:%s s' % (time.time() - start_time))
执行结果:
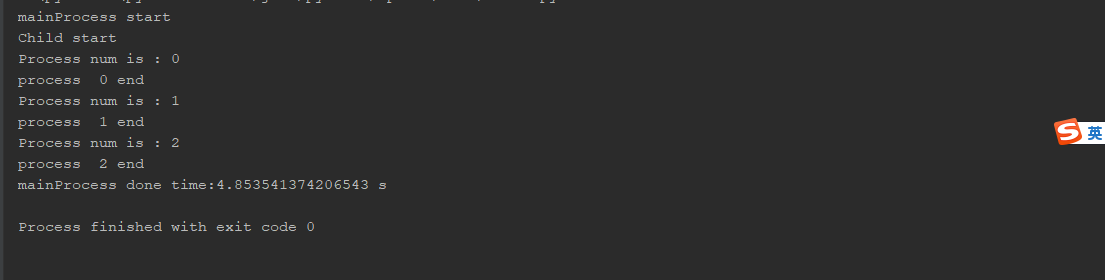
从执行结果可以看出,主进程开始执行后,创建的3个子进程也开始执行,当三个子进程按顺序执行完毕后,,主进程接着执行后续的代码。
当将apply()替换成apply_async()后,执行结果如下:

从结果可以看出,主程序没有被阻塞,但子程序看起来好像没有被执行。这是因为进程的切换是操作系统控制的,首先运行的是主程序,我们都知道,CPU运行的很快,快到还没等系统调度到子线程,主线程就已经执行完毕了,并且推出程序了,所以子程序没有被运行。这样,当然不是我们所希望的,我们在程序中加上join()就可以解决问题了,如下:
# -*- coding:utf-8 -*- import time import multiprocessing def doIt(num): print("Process num is : %s" % num) time.sleep(1) print('process %s end' % num) if __name__ == '__main__': print('mainProcess start') #记录一下开始执行的时间 start_time = time.time() #创建三个子进程 pool = multiprocessing.Pool(3) print('Child start') for i in range(3): # pool.apply(doIt,[i]) pool.apply_async(doIt,[i]) pool.close() pool.join() print('mainProcess done time:%s s' % (time.time() - start_time))
运行结果:

根据结果可以看出,即使使用了非阻塞主进程的apply_async(),子进程也运行了,同时可观察到子进程是按顺序交替执行的。CPU在运行第一个子进程的时候,还没等第一个子进程执行完毕,系统调度按顺序调度到了第二个子进程,以此类推,一直调度运行子进程,一个接一个的结束了子进程的运行,最后运行主进程。
(2)上面join()是什么用作呢?
join()作用:在进程中可以阻塞主进程的执行,直到等待子进程全部完成之后,才继续运行主进程后面的代码。
(3)pool.apply_async(func=test,args=(var,),callback=bar) #将参数var传递给函数test,并将test的返回结果作为参数传递给函数bar。