python11
1、多线程原理
2、怎么写一个多线程?
3、队列
4、生产者消费者模型
5、线程锁
6、缓存
memcache
redis
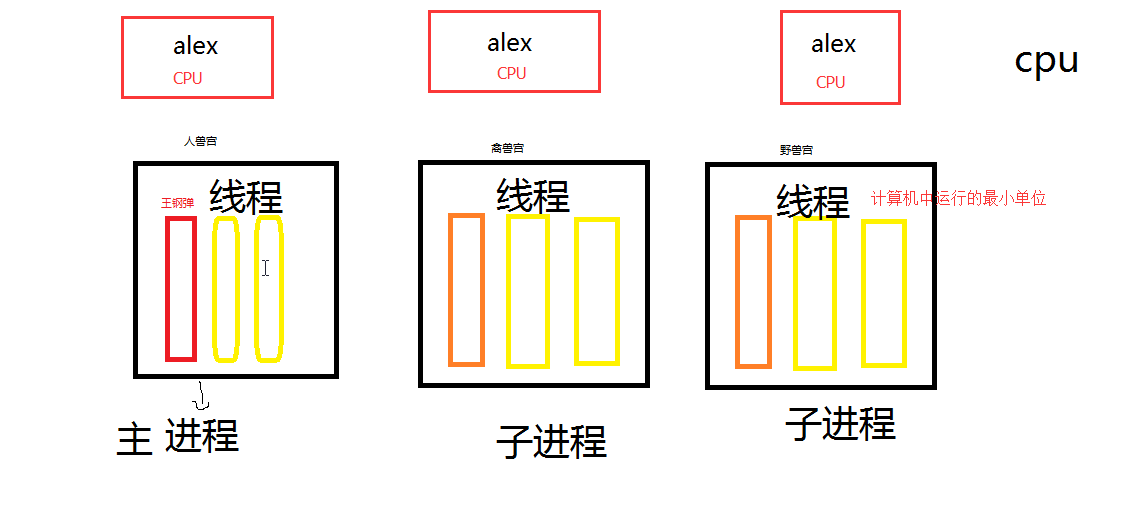
多线程原理
def f1(arg)
print(arg)
#单进程单线程的程序,好比后宫里面就一个慈宁宫 -- 主进程,一个王钢蛋 -- 线程
python中规定一个进程中只能有一个线程被cpu调度
这个的规定是因为python中一把锁:GIL,全局解释器锁
1、一个应用程序可以有多进程,可以有多进程
多进程,多线程目的是并发高,充分利用cpu
2、计算型操作占用cpu,使用多进程
io型操作不占用cpu,使用多线程
二、怎么写一个多线程
import time
def f1(arg):
time.sleep(5)
print(arg)
import threading #创建线程的模块都在这个模块中
t = threading.Thread(target=f1, args=(123,)) #target 让线程去做什么事,args 传递给f1函数的参数
t.start() #创建了一个线程已经准备好开始 ,还没有被cpu调度,什么时候被cpu调度还不知道
print("end") #默认主进程主线程运行到这里会等待,如果设置了t.setDaemon(True)就不等了

1.主线程 不等待子线程
t.setDaemon(True) #默认主线程等待子线程 t.setDaemon(False)
import time
def f1(arg):
time.sleep(5)
print(arg)
import threading #创建线程的模块都在这个模块中
t = threading.Thread(target=f1, args=(123,)) #target 让线程去做什么事,args 传递给f1函数的参数
t.setDaemon(True) #主线程不等子线程执行完就结束了,导致子线程没有执行就结束了
t.start() #创建了一个线程已经准备好开始 ,还没有被cpu调度,什么时候被cpu调度还不知道
print("end") #默认主进程主线程运行到这里会等待,如果设置了t.setDaemon(True)就不等了
2.主线程还可以选择 等待子线程的位置
t.join()
import time
def f1(arg):
time.sleep(5)
print(arg)
import threading #创建线程的模块都在这个模块中
t = threading.Thread(target=f1, args=(123,)) #target 让线程去做什么事,args 传递给f1函数的参数
t.start() #创建了一个线程已经准备好开始 ,还没有被cpu调度,什么时候被cpu调度还不知道
print("end1")
print("end2")
print("end3")
t.join(4) #主线程运行到此等待子线程执行完毕后再执行下面的4,5,6 join中的参数是最多等几秒, 这样执行到最后end6后主线程再等待子线程执行结果
print("end4")
print("end5")
print("end6")
3、如果我就是彻彻底底的不等了怎么办?
那我们就要将 join 和 setDaemon 一起使用了
import time
def f1(arg):
time.sleep(5)
print(arg)
import threading #创建线程的模块都在这个模块中
t = threading.Thread(target=f1, args=(123,)) #target 让线程去做什么事,args 传递给f1函数的参数
t.setDaemon(True)
t.start() #创建了一个线程已经准备好开始 ,还没有被cpu调度,什么时候被cpu调度还不知道 print("end1") print("end2") print("end3") t.join(4) #主线程运行到此等待子线程执行完毕后再执行下面的4,5,6 join中的参数是最多等几秒, 这样执行到最后end6后由于上面使用了t.setDaemon(True) 这时主线程也就不等子线程,直接结束了。 print("end4") print("end5") print("end6")
4、cpu是什么时候执行run方法的哪?
import time
import threading #创建线程的模块都在这个模块中
def f1(arg):
time.sleep(5)
print(arg)
t = threading.Thread(target=f1, args=(123,)) #target 让线程去做什么事,args 传递给f1函数的参数
t.start() #创建了一个线程已经准备好开始 ,还没有被cpu调度,什么时候被cpu调度还不知道
#当t.start()的时候我们定义好的这个线程只是准备好了,等待cpu调度,cpu是怎么调度的哪?
#就是cpu执行Thread类中的run()方法
def run(self):
try:
if self._target:
self._target(*self._args, **self._kwargs)
finally:
del self._target, self._args, self._kwargs
5、所以看到上面的。我们就可以衍生出另外一个创建线程的写法
class MyThread(threading.Thread): #1、我们自己写一个类,继承多线程的类
def __init__(self,taget,args): # 3、写一个构造方法,获取传入的tager和args,
self.tager = taget
self.args = args
super(MyThread, self).__init__() #4、并且为了不影响我们父类的构造方法,主动执行以下父类的构造方法
def run(self): #2、重新写一个run方法,让cpu主动执行我们定义的run方法,这个run方法执行我们传进去的参数
self.tager(self.args)
def f1(arg):
print(arg)
t = MyThread(f1,123)
t.start()
三、线程锁机制
线程中共同使用资源,就会发生资源争抢。同时修改相同的资源
实例
import threading import time NUM = 10 def f1(): global NUM NUM -= 1 #每个进程都减1 time.sleep(2) #然后统一停在这里 print(NUM) #在停止的时候别的线程也都陆陆续续的减完1了。所以此时NUM就为0了 for i in range(10): t = threading.Thread(target=f1) t.start()
操作后全部都输出为0
这时我们就需要给他加锁了
a、互斥锁
import threading
import time
NUM = 10
def f1(l):
global NUM
l.acquire() #加锁,同时只能一个线程进入
NUM -= 1 #每个进程都减1
l.acquire() #使用RLock就可以嵌套加锁
time.sleep(2) #然后统一停在这里
l.release() #解锁
print(NUM) #在停止的时候别的线程也都陆陆续续的减完1了。所以此时NUM就为0了
l.release() #解锁
lock = threading.Lock() #上锁不能嵌套
lock= threading.RLock() #上锁可以嵌套
for i in range(10):
t = threading.Thread(target=f1, args=(lock,))
t.start()
b、信号量锁,可自定义批量放行
import threading
import time
NUM = 10
def f1(i,l):
global NUM
l.acquire() #加锁,同时能进入多个,下面定义好的
NUM -= 1
time.sleep(2)
print(NUM,i)
l.release() #解锁
lock = threading.BoundedSemaphore(5)
for i in range(30):
t = threading.Thread(target=f1, args=(i,lock,))
t.start()
c、 event锁,一起锁一起放
import threading
def f1(i,e):
print(i)
e.wait() #查看传过来的灯,如果是绿灯放行,红灯不放行
print(i+100)
event = threading.Event()
for i in range(10):
t = threading.Thread(target=f1, args=(i,event))
t.start()
event.clear() #设置成红灯
inp = input(">>>")
if inp == "1":
event.set() #设置成绿灯
d、 Condition 条件
第一种写法,自己传值
def f1(i,con):
print(i)
con.acquire() #加锁
con.wait() #等待传过来的值
print(i+100)
con.release() #解锁
lock = threading.Condition() #创建锁
for i in range(10):
t = threading.Thread(target=f1,args=(i,lock,))
t.start()
while True:
inp = input(">>>")
if inp == "q":
break
lock.acquire() #这三步必须要一起用
lock.notify(int(inp)) #传递输入的值
lock.release() #必须要一起用
第二种写法 : wait_for
def f2():
ret = False
while True:
inp = input(">>>")
if inp == "yes":
ret = True
else:
ret = False
return ret
def f1(i, con, fun):
print(i)
con.acquire()
con.wait_for(fun) #这里需要传入一个函数,wait_for接受这个函数的返回值 如果为真则放一个线程,如果为False就不成立
print(i+100)
con.release()
q = threading.Condition()
for i in range(10):
t = threading.Thread(target=f1, args=(i, q, f2))
t.start()
e、Timer
写监控,或者客户端时可能会用到这个
from threading import Timer def f1(arg): print(arg) t = Timer(1,f1,args=(1,)) #1秒钟以后生成一个线程去执行f1函数 t.start()
四、队列
1、基本存取参数
import queue
q = queue.Queue(2) #先进先出队列,2 参数表示队列中最多接收2个数据
#没有位置默认处理方式,等待和报错
q.put(123) #放数据 1个
q.put(234) #放数据 2个
print(q.qsize()) #查看队列中的数量 q.put(345) #因为上面设置了2,所以到这里就卡了,下面就不执行了 <--------------只运行到了这里
q.put(234) #放数据 3个
print(q.get()) #取数据
print(q.get())
2 #只运行到 print(q.qsize())
2、存取的参数
import queue
q = queue.Queue(2) #先进先出队列,10参数表示队列中最多接收10个数据,如果不写参数就是添加任意多的数据
#没有位置2种处理方式,等待和报错
q.put(123) #放数据
q.put(234)
print(q.qsize()) #查看队列中的数量
q.put(345,timeout=2) #阻塞2秒,超时后报错
q.put(345,block=False) #不阻塞
q.put(345,timeout=2) #到这里就卡了 timeout=2 等2秒,如果有位置就加进去,如果没加进去就报错
# q.put(345,block=False) #block=False 阻塞时的超时时间,False是不阻塞,如果插不进去就直接报错。
print(q.get()) #取数据1,有数据直接取走,没有数据
print(q.get()) #取数据2
print(q.get(timeout=2)) #第三次,没有数据,默认阻塞,timeout=2最多阻塞2秒,超时后报错
print(q.get(block=False)) #第三次,没有数据,默认阻塞,block=False 设置为不阻塞
3、其他的参数
1、q.get_nowait == get(block=False)
2、q.empty() 检查队列中是否为空
import queue
q = queue.Queue()
q.put(123) #放数据
q.put(234) #放数据
print(q.empty()) #检查
q.get() #取数据
q.get() #取数据
print(q.empty()) #检查
False #满的
True #空了
3、q.full () 检查是否满了
import queue
q = queue.Queue(2) #最多放2个
q.put(123) #放数据
print("1,full", q.full())
q.put(234) #放数据
print("2,full", q.full())
1,full False
2,full True
4、 q.maxsize() 获取到最大个数
这个数就是我们创建对象时传递的参数产生的
import queue
q = queue.Queue(2)
#源码
class Queue:
def __init__(self, maxsize=0):
self.maxsize = maxsize
self._init(maxsize)
5、join
import queue
q = queue.Queue(2) #最多放2个
q.put(123) #放数据
q.put(234) #放数据
q.get()
q.task_done()
q.get() #就算你把2个数据都取出来了,join还是不终止,这个时候就需要 q.task_done()这个,每取出个数值来告诉队列
q.task_done() #这个时候就需要 q.task_done()这个,每取出个数值来告诉队列
q.join() #表示如果队列中的任务没有完成我就在这等待着,不终止这个线程,等待着 task_done()
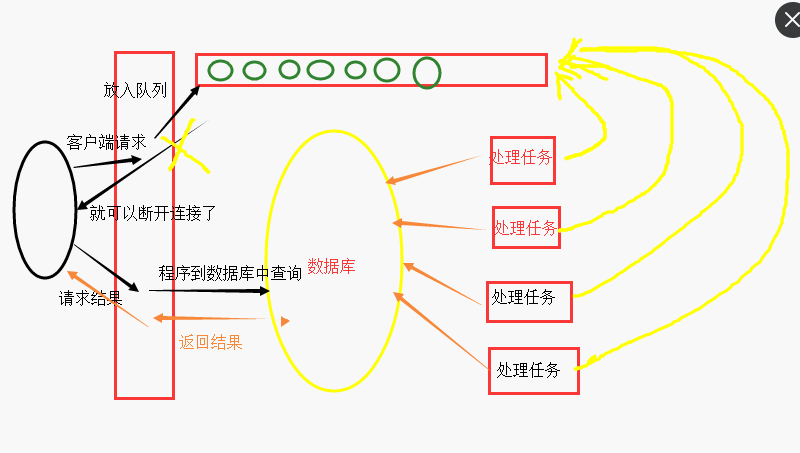
五、生产者消费者模型
为什么要有生产者消费者模型
#1、用户太多,后面处理的能力低,处理不过来。所以需要用户稍微等待一下,使用队列缓解服务器的压力。
#2、解决socket链接的长时间等待挂起状态,有了队列就可以把这个链接需要做的请求交给队列,然后客户端就可以断开了,客户端需要查询一些想要的到的消息时就向服务器再发出一个查询请求,服务器处理完就返回,没有处理完就让客户一会再查。
#3、支持瞬时并发非常大
#4、完成解耦,本来客户端和服务器是1对1的,有了队列,客户端不直接对应服务器,服务器是讲请求给队列,然后想查看状态,再查看另一个状态的页面
实例1, 包子店:
import queue, time, threading
q = queue.Queue()
生产者人手不够,所以需要后面的消费者在队列里等待
def productor(arg): #生产者,厨师
while q.qsize()<5: #判断队列中小于5个包子开始包
print("++++",q.qsize())
q.put(str(arg)+" - 包子") #往队列中加包子
time.sleep(1) #每包一个包子需要1秒
def consumer(arg): #消费者,吃包子
while True:
print(arg,q.get())
time.sleep(5) #没吃一个包子需要5秒钟
for i in range(3): #有3个厨师一起包包子
t = threading.Thread(target=productor,args=(i,))
t.start()
for j in range(20): #有20个客户买包子吃包子
t = threading.Thread(target=consumer,args=(j,))
t.start()
实例2:12306
import queue ,time ,threading
q = queue.Queue()
def goupiao(arg):
q.put(arg,"买票")
def maipiao(arg):
while True:
a = q.get()
print(str(arg),a)
print("队列中还有多少人在等",q.qsize())
time.sleep(2) #买票的过程需要2秒钟
for i in range(10):
t = threading.Thread(target=maipiao,args=(i,))
t.start()
for j in range(300):
t = threading.Thread(target=goupiao,args=(j,))
t.start()
这样做结果就是队列中有很多人再等待,出票就10张10张出。
生产者消费者模型
六、 缓存
1、服务器上安装缓存软件
2、客户端安装缓存模块
a、memcache
memcache 只支持一种数据类型
key ---> value (字符串)
1、连接方式:
import memcache
mc = memcache.Client(['10.211.55.4:12000'], debug=True)
mc.set("foo", "bar")
ret = mc.get('foo')
print ret
debug = True 表示运行出现错误时,现实错误信息,上线后移除该参数。
2,memcache 支持集群
mc = memcache.Client([('10.211.55.4:11211',1),('10.211.56.4:11211',2),('10.211.56.4:11211',3)], debug=True)
(主机名,端口号,权重)
原理:
b、redis
redis支持的数据类型非常丰富
redis是一个key-value存储系统。和Memcached类似,它支持存储的value类型相对更多,包括string(字符串)、list(链表)、set(集合)、zset(sorted set --有序集合)和hash(哈希类型)。redis是一个key-value存储系统。和Memcached类似,它支持存储的value类型相对更多,包括string(字符串)、list(链表)、set(集合)、zset(sorted set --有序集合)和hash(哈希类型)。
1、连接方式:
创建单独连接
创建连接处
"""
1、创建单独连接
"""
r = redis.Redis(host='192.168.109.129',port=6379)
r.set('foo','bar')
print(r.get('foo'))
"""
2、创建连接池
"""
因为创建一个连接非常耗时,所以我们可以先创建好个连接池,从里面取链接使用
pool = redis.ConnectionPool(host='192.168.109.129',port=6379) #创建一个线程池
p = redis.Redis(connection_pool=pool) #去连接池中拿一个链接
p.set('FOO',"BOO")
print(p.get('FOO'))
2、操作:
set(name, value, ex=None, px=None, nx=False, xx=False)
在Redis中设置值,默认,不存在则创建,存在则修改
参数:
ex,过期时间(秒)
px,过期时间(毫秒)
nx,如果设置为True,则只有name不存在时,当前set操作才执行
xx,如果设置为True,则只有name存在时,岗前set操作才执行
SET 设置数据 nx p.set('FOO',"BOO") #字符串操作 p.set("FOO","BOO1",nx=True) print(p.get('FOO')) BOO 因为nx为True 所以不生效 p.setnx("FOO","BOO1") print(p.get('FOO')) ex 秒级别的设置时间 p.setex("FOO","BOO1",3) print(p.get('FOO')) FOO 毫秒级别的设置时间 p.psetex("FOO",1,'POO') print(p.get('FOO')) mset 批量设置的2中方法 p.mset(k1="v1", k2='v2', k3='v3') p.mset ( {"k1":"v1", "k2":"v2", "k3":'v3'} )
GET 获取数据 获取单个数据 print(p.get("k1")) 获取批量数据 print(p.mget("k1","k2","k3")) 获取到原来的值后再设置新的值 print(p.getset("k1","V1")) 获取到数据并获取其子序列 a = p.getrange('k4',0,1) #(key,start,end) p.setrange('k4',1,5) # 修改字符串内容,从指定字符串索引开始向后替换(新值太长时,则向后添加) # 参数: # offset,字符串的索引,字节,其实位置向后 (一个汉字三个字节) # value,要设置的值 # 对name对应值的二进制表示的位进行操作 p.setbit('k4',7,1) 将第7个位置本来是 0改成 1 # 参数: # name,redis的name # offset,位的索引(将值变换成二进制后再进行索引) # value,值只能是 1 或 0 # 注:如果在Redis中有一个对应: n1 = "foo", 那么字符串foo的二进制表示为:01100110 01101111 01101111 所以,如果执行 setbit('n1', 7, 1),则就会将第7位设置为1, 那么最终二进制则变成 01100111 01101111 01101111,即:"goo" p.getbit('k4',2) #参数 # k4 key # offset 获取第2个位置的值 p.bitop('AND','k5','k1','k2') # 获取多个值,并将值做位运算,将最后的结果保存至新的name对应的值 # 参数: # operation,AND(并) 、 OR(或) 、 NOT(非) 、 XOR(异或) # dest, 新的Redis的name # *keys,要查找的Redis的name # 如: bitop("AND", 'new_name', 'n1', 'n2', 'n3') # 获取Redis中n1,n2,n3对应的值,然后讲所有的值做位运算(求并集),然后将结果保存 new_name 对应的值中 print(p.mget('k1','k2')) p.bitop('AND','k5','k1','k2') print(p.get('k5')) [b'V1', b'v2'] b'V0' p.incr('k6',1) # 自增 name对应的值,当name不存在时,则创建name=amount,否则,则自增。 # 参数: # name, Redis的 name # amount, 自增数(必须是整数) p.set("k6",1) p.incr('k6',1) print(p.get('k6')) p.dect('k6',2) # 自减 name对应的值,当name不存在时,则创建name=amount,否则,则自减。 # 参数: # name,Redis的name # amount,自减数(整数) print(p.get('k6')) p.decr('k6',2) print(p.get('k6')) b'0' b'-2' p.append("k6",1) # 在redis name对应的值后面追加内容 # 参数: key, redis的name value, 要追加的字符串 print(p.get('k6')) p.append("k6",1) print(p.get('k6')) b'-2' b'-21'