scrapy数据的持久化(将数据保存到数据库)
一、建立项目
1、scrapy startproject dushu
2、进入项目
cd dushu
执行:scrapy genspider -t crawl read www.dushu.com
查看:read.py
class ReadSpider(CrawlSpider):
name = 'read'
allowed_domains = ['www.dushu.com']
start_urls = ['https://www.dushu.com/book/1175.html']

注:项目更改了默认模板,使其具有递归性

3、模板CrawlSpider具有以下优点:
1)继承自scrapy.Spider;
2)CrawlSpider可以定义规则
在解析html内容的时候,可以根据链接规则提取出指定的链接,然后再向这些链接发送请求;
所以,如果有需要跟进链接的需求,意思就是爬取了网页之后,需要提取链接再次爬取,使用CrawlSpider是非常合适的;
3)模拟使用:
a: 正则用法:links1 = LinkExtractor(allow=r'list_23_d+.html')
b: xpath用法:links2 = LinkExtractor(restrict_xpaths=r'//div[@class="x"]')
c:css用法:links3 = LinkExtractor(restrict_css='.x')
4、更改模板后rules参数解释:
a:参数一 (allow=r'/book/1175_d+.html') 匹配规则;
b: 参数二 callback='parse_item' ,数据回来之后调用多方法
c: 参数三,True,从新的页面中继续提取链接
注:False,当前页面中提取链接,当前页面start_urls
5、 修改start_urls
start_urls = ['https://www.dushu.com/book/1175.html']
写 def parse_item(self, response)

6、items.py
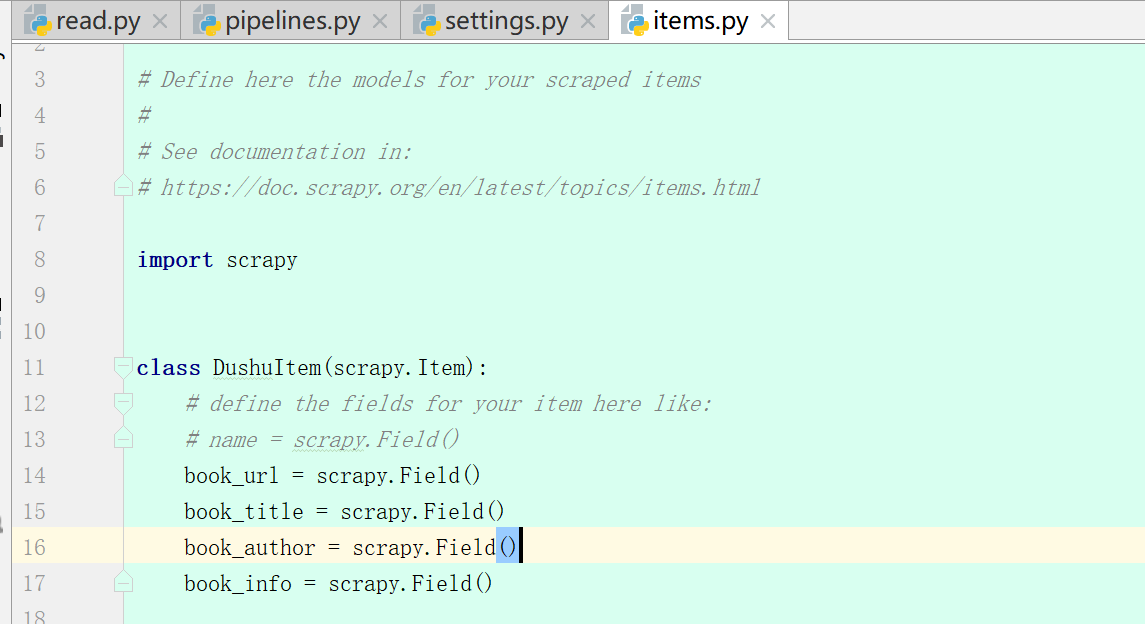
7、pipelines.py(yield后会回到pipelines.py)
1)写def __init__(self): 和 def close_spider(self,spider):
2)连接mysql,保存数据
3)启动mysql (Navicat)

4) 连接数据库def process_item(self, item, spider)

5)setting(robots、USER_AGENT、ITEM_PIPELINES)
6)read.py(修改rules)

8、执行scrapy crawl read,将数据写入数据库
欢迎关注小婷儿的博客:
csdn:https://blog.csdn.net/u010986753
博客园:http://www.cnblogs.com/xxtalhr/
有问题请在博客下留言或加QQ群:483766429 或联系作者本人 QQ :87605025
OCP培训说明连接:https://mp.weixin.qq.com/s/2cymJ4xiBPtTaHu16HkiuA
OCM培训说明连接:https://mp.weixin.qq.com/s/7-R6Cz8RcJKduVv6YlAxJA
小婷儿的python正在成长中,其中还有很多不足之处,随着学习和工作的深入,会对以往的博客内容逐步改进和完善哒。
小婷儿的python正在成长中,其中还有很多不足之处,随着学习和工作的深入,会对以往的博客内容逐步改进和完善哒。
小婷儿的python正在成长中,其中还有很多不足之处,随着学习和工作的深入,会对以往的博客内容逐步改进和完善哒。
重要的事说三遍。。。。。。

