第一个程序


#include <stdio.h> int main() { printf("I love FishC.com! "); return 0; }
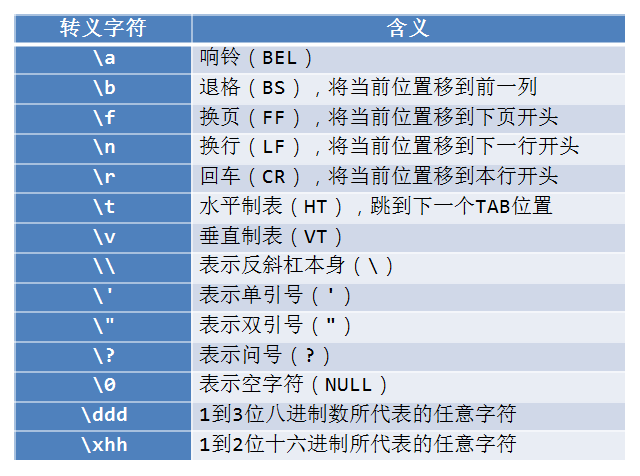






数据类型
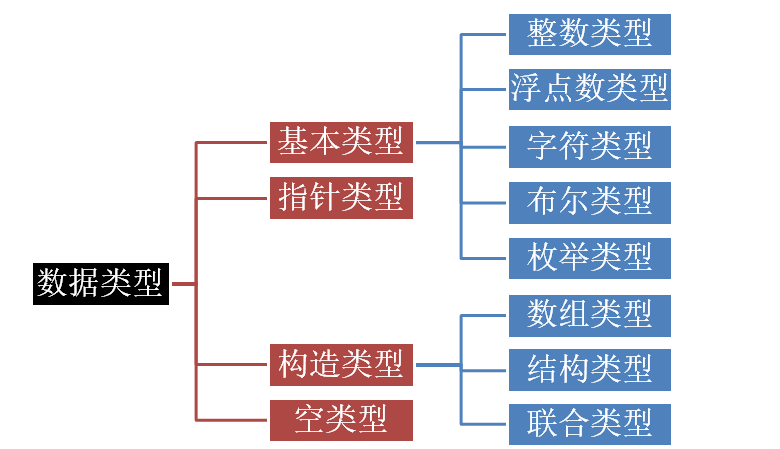

声明变量语法



printf()函数
printf()函数用于输出。 它将给定的语句打印到控制台。
printf()函数的语法如下:
printf("format string",argument_list);
格式字符串("format string")可以是%d(整数),%c(字符),%s(字符串),%f(float)等)。
scanf()函数
scanf()函数用于输入,它从控制台读取输入的数据。语法如下 -
scanf("format string",argument_list);
无符号与有符号数据的操作区别在于当最高位,当最高位为0时都一样;
当最高位为1时,进行数据类型间的转换操作就会产生问题,详情如下:
在C中,默认的基础数据类型均为signed,现在我们以char为例,说明(signed) char与unsigned char之间的区别
首先在内存中,char与unsigned char没有什么不同,都是一个字节,唯一的区别是,char的最高位为符号位,因此char能表示-128~127, unsigned char没有符号位,因此能表示0~255,这个好理解,8个bit,最多256种情况,因此无论如何都能表示256个数字。
在实际使用过程种有什么区别呢?
主要是符号位,但是在普通的赋值,读写文件和网络字节流都没什么区别,反正就是一个字节,不管最高位是什么,最终的读取结果都一样,只是你怎么理解最高位而已,在屏幕上面的显示可能不一样。
但是我们却发现在表示byte时,都用unsigned char,这是为什么呢?
首先我们通常意义上理解,byte没有什么符号位之说,更重要的是如果将byte的值赋给int,long等数据类型时,系统会做一些额外的工作。
如果是char,那么系统认为最高位是符号位,而int可能是16或者32位,那么会对最高位进行扩展(注意,赋给unsigned int也会扩展)
而如果是unsigned char,那么不会扩展。
这就是二者的最大区别。
同理可以推导到其它的类型,比如short, unsigned short。等等
具体可以通过下面的小例子看看其区别
include <stdio.h>
void f(unsigned char v)
{
char c = v;
unsigned char uc = v;
unsigned int a = c, b = uc;
int i = c, j = uc;
printf("---------------- ");
printf("%%c: %c, %c ", c, uc);
printf("%%X: %X, %X ", c, uc);
printf("%%u: %u, %u ", a, b);
printf("%%d: %d, %d ", i, j);
}
int main(int argc, char *argv[])
{
f(0x80);
f(0x7F);
return 0;
}
输出结果:
----------------
%c: ?, ?
%X: FFFFFF80, 80
%u: 4294967168, 128
%d: -128, 128
----------------
%c: ,
%X: 7F, 7F
%u: 127, 127
%d: 127, 127
由此可见,最高位若为0时,二者没有区别,若为1时,则有区别了

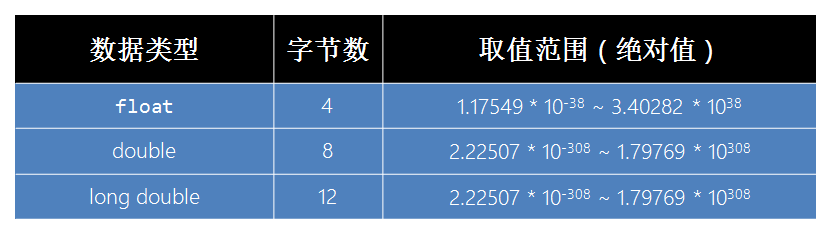
取值范围


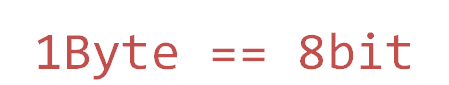







您还可以通过字符串文字定义字符串。 例如:
char ch[]="yiibai.com";
在这种情况下,'�'将由编译器自动在字符串末尾附加。
char数组和字符串文字之间的区别
唯一的区别是字符串字面值不能改变,而由char数组声明的字符串可以更改。