前期博文提到管道(pipeline)在机器学习实践中的重要性以及必要性,本文则递进一步,探讨实际操作中管道的创建与访问。
已经了解到,管道本质上是一定数量的估计器连接而成的数据处理流,所以成功创建管道的唯一要求就是:管道中所有估计器必须具有fit()和transform()方法,但管道中最后一个估计器只需具有fit()方法足矣;
这个约束条件的目的是保证,管道中后一个估计器能够接受前一个估计器的transform输出。
pipeline创建
创建管道一般有两种途径:
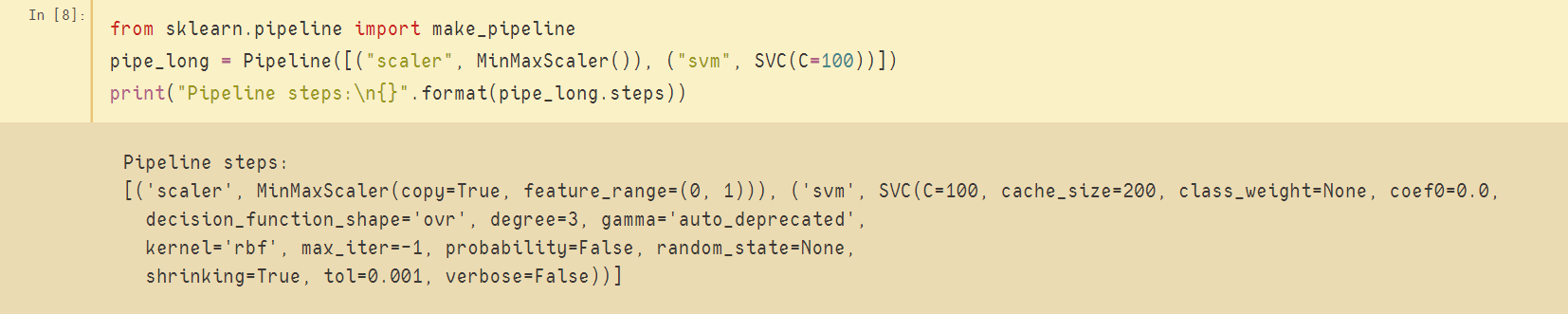
如上图,利用Pipeline创建两个估计器构成的管道,并且指明每个步骤的名称;利用pipe_long.steps()方法可以得到管道的每个估计器的细节信息。

对比这两个创建方法,可以发现不指定处理步骤名称时,系统会自动给估计器命名(见图中圆圈部分)。
访问pipeline中估计器信息
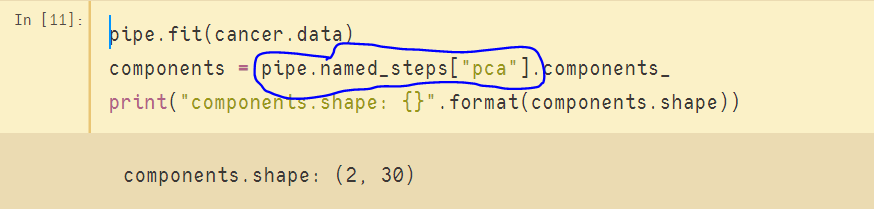
如下图所示,圆圈部分利用管道的named_steps属性和特定估计器的名称指定访问目标,而后访问目标的components_信息。
下面是一个较为完整的实例:
第一步,先创建由数据标准化函数和逻辑回归分类器构成的管道,并在网格搜索的框架下进行训练数据的拟合:

第二步:类似地,利用管道的named_steps属性指定逻辑回归估计器的步骤名称,得到估计器的大体信息和系数属性。
