Transformer架构记录(二)中提到,整个Encoder-block的结构如下图所示:
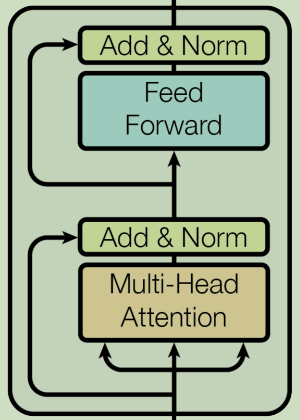
本文聚焦上图中的Multi-Head Attention模块,即下图所示:

1. self-Attention
self-Attention是理解Multi-Head Attention模块的基础,因此需要理解自注意力机制在Transformer中的具体原理。
1.1 Q、K、V计算
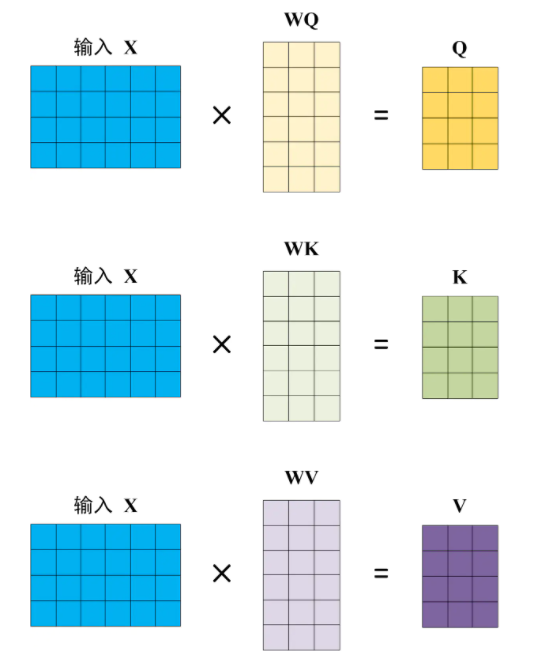
对于Transformer架构记录(二)中提到的输入 X (X的行数表示一句话中的Token数目,列数表示每个Token的embedding维数,与词向量维数、位置向量维数一致),将 X 与3个矩阵(WQ、WK、WV)做乘法得到 Q、K、V 3个矩阵;
显然,WQ、WK、WV的行数必需与 X 的列数保持相同(确保矩阵乘法得以实施);至于WQ、WK、WV的列数,一般要求WQ、WK的列数相同,WV的列数并不强制要求与WQ、WK的列数相同。
WQ、WK、WV作为模型参数,其具体数值可在模型训练过程中得以更新。
1.2 attention计算
在得到的Q、K、V 上施以函数Attention(),具体如下:
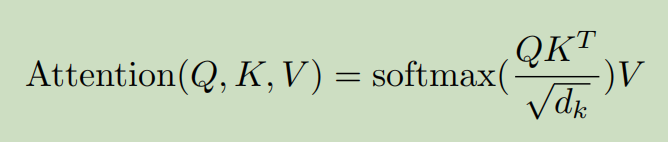
-
即Q乘以K的转置,得到的矩阵QK^T的size为NxN(N为一句话中的Token数目);
-
将QK^T的每个元素除以d_k(d_k即前述矩阵Q、K的列数,也是WK、WV的列数)的算术平方根;
-
对2所得矩阵的每一行进行 Softmax,即使得矩阵每一行的和都变为 1;
-
对3所得矩阵与先前的矩阵 V 作矩阵乘法,所得矩阵记为 Z, Z的size为(N, d_v) d_v表示矩阵 V 的列数。
可以看到,self-attention利用一组矩阵(WQ、WK、WV),将输入 X(N, E)转换为 Z (N, d_v),N为一句话中的Token数目,E词向量维数,d_v表示矩阵 V 的列数。
2. Multi-Head Attention
Multi-Head Attention即为输入 X 配置多组(WQ_i、WK_i、WV_i),从而得到多个Z (N, d_vi),d_vi为对于矩阵 WV_i 的列数,一般设置所有的 WV_i 列数相同。
如下图所示:
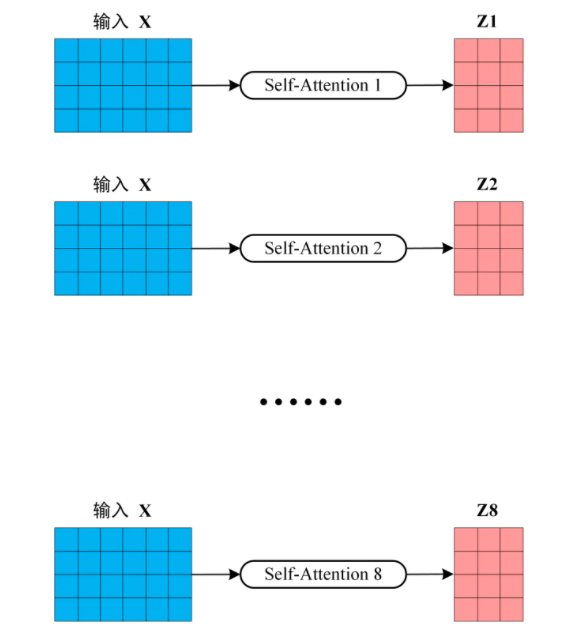
得到 8 个输出矩阵 Z1 到 Z8 之后,将它们拼接在一起 (Concat),再次乘以矩阵(该矩阵的列数与输入 X 的列数相同),得到 Multi-Head Attention 最终的输出 Z。
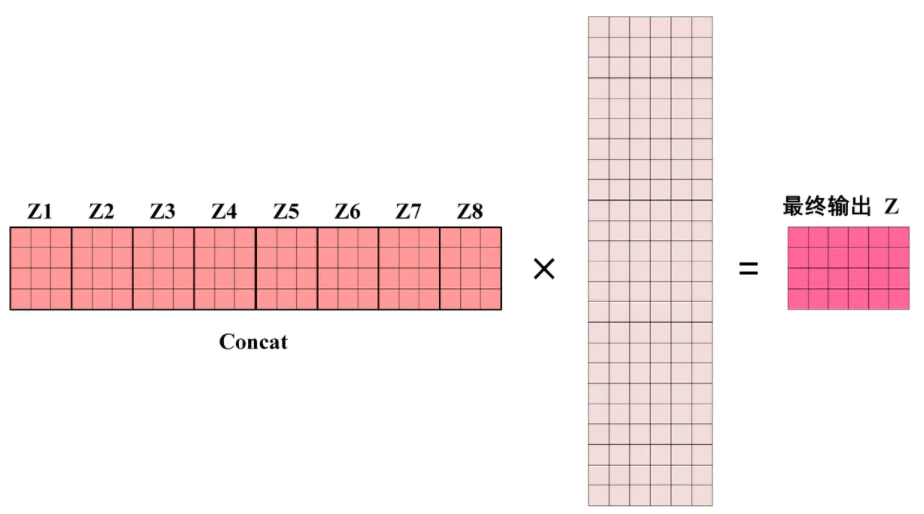
输出的矩阵 Z 与其输入的矩阵 X 的维度是一样的
上述输出矩阵 Z 对应到“ Transformer架构记录(二)”中的 X_mha .
下期预告:Decoder-block理解
参考资源
链接:https://www.jianshu.com/p/9b87b945151e
《Attention Is All You Need》