背景介绍
JSF(京东服务框架,类似dubbo)默认配置了可伸缩的最大到200的工作线程池,每一个向外提供的服务都在其中运行(这里我们是服务端),这些服务内部调用外部依赖时(这里我们是客户端)一般是同步调用,不单独限制调用并发量,因为同步调用时会阻塞原服务线程,因此实际上所有外部调用共享了JSF的200工作线程池。
Hystrix框架为了隔离依赖相互影响,默认使用了线程隔离机制,为每个依赖提供一个小的线程池,如果该线程池已满新的调用将被立即拒绝,默认不排队加快失败返回。这与JSF原来的机制非常不一样,我们的问题是:
-
额外的线程池是否有太大的性能开销?
-
线程池大小设置多少合理?
希望通过本次测试调研得到答案。
用例介绍
构造两个接口,分别调用原生mock方法和调用经过hystrix包装的mock方法,两个mock方法内部都是一个Thread.sleep,根据不同参数模拟不同性能的外部依赖调用。其中JSF线程池为默认值最大200,hystrix单个线程池大小为默认值10,默认超时1000ms,为了排除干扰禁用断路器。根据两个接口、不同mock参数和不同压测线程数组合构造出共11个测试用例。
部署单台只包括这两个接口的生产机器,使用分布式压测平台(多台Jmeter)对其进行压测,主要通过接口内部的UMP进行性能和JVM状态监控,JVM使用JDK8并且开启G1收集器(压测中无full gc)。
@Service
public class MockJsfServiceRef {
@HystrixCommand(commandProperties = {
@HystrixProperty(name = "circuitBreaker.enabled", value = "false")
})
public String doHystrix(Integer param) throws Exception {
Thread.sleep(param);
return "1";
}
public String doNative(Integer param) throws Exception {
Thread.sleep(param);
return "1";
}
}
压测数据及解析
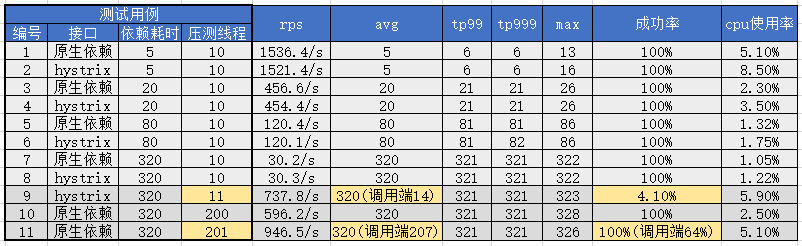
首先前8个用例和结果数据体现了在相同的正常压力下(10线程)不同调用方式和不同性能依赖的吞吐量和性能指标,可以看出:
-
同样耗时依赖条件下,hystrix会占用更多的cpu资源,但是并不显著,并且当耗时增加时该影响持续减小(由于压测接口无任何计算逻辑因此整体cpu使用很低,推测实际服务逻辑耗费CPU较多时hystrix的性能影响更不明显,有待生产环境验证)。
-
相同的压测线程(hystrix处理线程也是10)下依赖耗时以及与之对应的平均耗时avg直接影响了接口的吞吐量(rps,每秒请求数)。观察该规律可以得到公式:threads / avg(s) = rps,下面举例:
-
avg=320时,10 / 0.32 = 31.25,观察用例7,8分别得到原生30.2和hystrix的30.3,基本吻合。
-
avg=80时,10 / 0.08 = 125,观察用例5,6分别得到原生120.4和hystrix的120.1,有所损耗后吻合。
-
avg=20时,10 / 0.02 = 500,观察用例3,4分别得到原生456.6和hystrix的454.4,损耗增加。
-
avg=5时,10 / 0.005 = 2000,观察用例1,2分别得到原生1536.4和hystrix的1521.4,损耗较大。
-
-
其他信息:从上面数据也可以看出当rps增加到较高时线程调度本身带来的损耗增加显著,CPU使用率也显著上升,即线程调度压力开始显著增加,无论是否使用hystrix这都是无法避免。hystrix在相同耗时对比中增加部分cpu使用率,对max指标有所影响,个别数据下对tp999也有所影响,但是影响都比较小。
后面三组测试用例则继续提高压测线程,由于hystrix默认配置10个线程,因此当压测超过10个线程时,多出来的请求则会处理不过来,体现为线程池满后直接拒绝,快速返回失败,同时快速返回后压测端又会立刻请求,结果就是rps迅速上升同时成功率急速下降,线程池正常处理的请求则未受影响,用例9体现了这一现象(服务端监控avg=320而客户端由于大量1ms的快速失败返回使avg=14)。
用例10和11是原生调用,我们继续提高压测线程到200和201,以期测试JSF的200线程池,得到结果符合预期,即JSF线程被打满后无法处理额外的请求,与用例9表现相似,但是临界值从10线程到200线程,更多的线程带来了更多吞吐量。还有一点不同的细节在于,hystrix线程满后返回异常时可以触发我们的UMP监控,捕捉到成功率下降,但是JSF线程池满后,直接拒绝请求,服务端无法监控到这些失败,只有调用端能得到成功率下降的信息。
结论
通过上面压测数据解析,我们可以对开始的问题进行解答。
-
额外的线程池是否有太大的性能开销?
上述测试中hystrix对性能损耗并不大,不管是CPU使用率的增加已经性能指标的影响都不明显,但是由于测试用例的局限性,不能说明所有情况,但我认为达到了到生产环境小范围使用的条件,可以通过继续积累使用经验解答该问题。
The Netflix API processes 10+ billion HystrixCommand executions per day using thread isolation.
Each API instance has 40+ thread-pools with 5-20 threads in each (most are set to 10).
-
线程池大小设置多少合理?
我们在测试中得到了公式:threads / avg(s) = rps,实际上hystrix的文档中也有一段类似的描述:
requests per second at peak when healthy × 99th percentile latency in seconds + some breathing room
30 rps * 0.2 second = 6 + breaking room = 10 threads
初看这段描述时难以理解,但是通过我们上面的压测数据和公式可以明了,它将avg替换为了tp99,同时再增加了更多余量,以期尽量避免正常流量增长和依赖波动导致线程池被打满的情况。
举一个实际例子,小金库当前并发量最大的接口A,在去年双十一压测中达到了22.6W的RPS(是平时峰值10倍),一共有201台实例,单实例RPS=1124,tp99=6ms(avg=2ms),以此计算 1124 * 0.006 = 6.7,因此增加余量到10(或15)即可满足需求。
-
新问题,线程池满了怎么办?
在上面测试数据解析中,我们发现由于hystrix为每个依赖严格限制了一个小的线程池,当线程池满了后拒绝服务似乎影响很大。根据我们的公式threads = rps * avg(s),当流量过高时或依赖耗时增加过多时都会触发线程池打满。首先针对流量过高我们可以通过监控报警(主动增加线程数,可以动态配置生效) + 提前预设足够的余量解决。其次针对依赖耗时增加过多的问题,前面的做法也能部分解决该问题,但是回归起点来说,某个依赖突然变得非常慢,以至于打满JSF线程池造成应用整体不可用,这本来就是我们要用hystrix解决的问题,使用hystrix后故障依赖的调用快速失败,同时失败率积累到阈值后断路器熔断降级,在该依赖恢复后自动关闭断路器,恢复对其调用 。