上文提到构建平台需要实现一个更好的提交流程,具体目标是将 SQL 任务相关内容,如 SQL 、DDL、UDF、配置内容等信息作为参数,调用提交API就能在目标集群创建任务。
一、分析提交作业流程
首先借由官方文档中的整体角色流程图,可以看出左侧一部分 Flink Program 其中包括用户程序代码和一个 Client,是由该 Client 将用户代码生成的作业图 - JobGraph 提交到远程的 JobManager 中,但是我们前面说提交任务要自己直接上传 Jar 包到 JobManager,这种情况怎么解释呢?
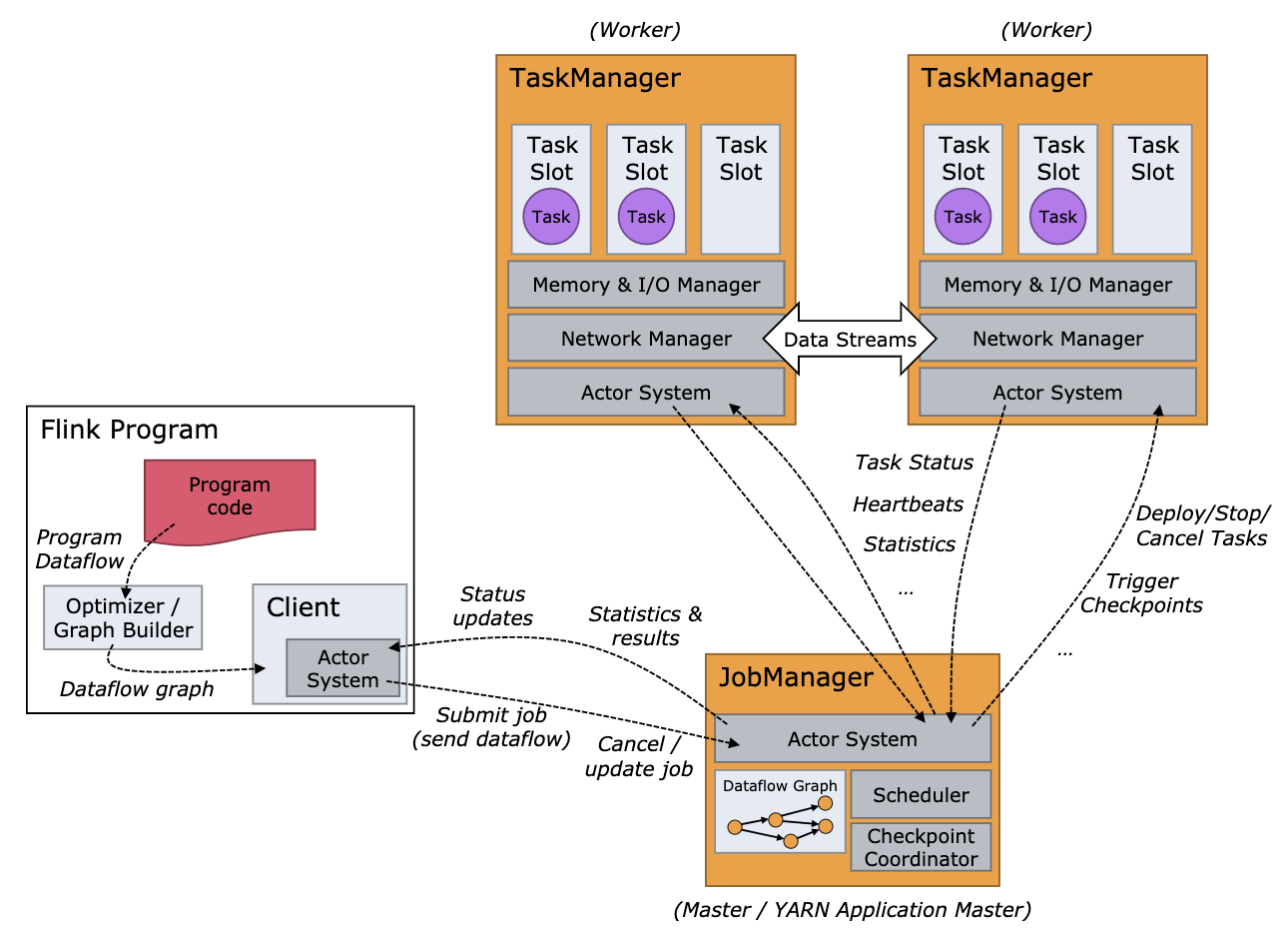
其实,这个 client 是指 flink-clients 模块中提供的 ClusterClient 抽象类,它有两个实现 MiniClusterClient 和 RestClusterClient ,分别对应向用户本地内嵌环境和远程集群提交任务。当我们使用 Main 方法在本地启动Flink任务时,模版代码中 getExecutionEnvironment 会创建 LocalStreamEnvironment ,后面它会使用 MiniClusterClient 向自己程序启动的 MiniCluster 中提交任务(JobGraph和依赖包)。当任务打成 Fat jar 后,提交到 JobManager 的 web 端或集群中任意实例的命令行入口: bin/flink run -d xxx.jar,都会通过 callMainMethod(mainClass, args) 去执行 getExecutionEnvironment进而创建别的 XXXEvironment,最终使用 RestClusterClient 向真正的 JobManager 提交任务(JobGraph和依赖包)。总体上说 client 是指运行 flink-clients 模块中的 RestClusterClient 的角色。
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
//StreamExecutionEnvironment env = StreamExecutionEnvironment.createRemoteEnvironment(……);
TableEnvironment tableEnv = StreamTableEnvironment.create(env);
// ……
tableEnv.execute("jobName");
了解到这里,我们就有了第一个实现作业提交的思路,可以主动指定 createRemoteEnvironment(host, port, configs, jarFiles) ,这样在 execute() 时就会通过上面的 RestClusterClient 向远程 JobManager 提交任务。
二、复用 SQL Client 的提交过程
虽然我们解决了如何向远程集群提交任务的问题,但是这只是低层次的提交API,我们依然要考虑如何封装 SQL 任务,此外还有如何实现调试功能。先不要闭门造车,我们可以先看看 Flink SQL Client 是怎么实现的。
Flink SQL Client 是官方提供的一个命令行界面的针对Flink的SQL客户端工具,除了命令解析和配置管理外,它封装了 Table Api 功能和提交任务的流程,对外暴露一系列功能,如 useDatabase,createTable,listTables,listFunctions,explainStatement,executeQuery,executeUpdate 等,深入源码可以看到每个功能都对应了一系列 Table Api 操作,最终 execute 时会通过 RestClusterClient 向远程 JobManager 提交任务。
看的这里,我们有了第二个实现方案,就是通过借(改)鉴(造) Flink SQL Client 的 LocalExecutor 和 提交流程,把该部分扩展为 Web 平台的服务层。这里还有个意外之喜是有了调试功能,LocalExecutor 中实现的 executeQueryInternal 就是一个调试功能,即提交 select 语句,结果输出持续异步返回给用户。与之对应的 executeUpdateInternal 是包括 insert 的带有 Sink 的真正的提交执行,也就是 detached mode,只返回任务 ID。
我们一个完成的SQL任务流程为例,入口参数是源表和结果表 DDL、任务 SQL、UDF 定义 和 jar 包地址 (HDFS 或 本地路径)、并行度配置、Checkpoint配置、启动 Savepoint 地址 等信息,其中在创建 ExecutionContext 以及 Environment 的 ExecutionConfig 进行UDF和各类参数配置,通过 Table Api 的 sqlUpdate 执行 DDL,最后复用原来的任务提交代码。
此外,在最新的 Flink 1.10 版本中,任务提交的 API 有所变化,主要是新增加了抽象层,将原来的 StreamGraph 定义为 PipeLine,增加了 PipelineExecutorFactory,PipelineExecutor,ClusterClientProvider 等中间层,最终还是去调用 RestClusterClient 进行任务提交,其中设计模式和层次较多我们暂不关心,可以直接复用 SQL Client 中封装的 ProgramDeployer 进行调用。