数据库: 就是一个文件系统,但只能通过标准的sql访问,结构化查询语言,非过程性语言 一条语句会有一个运行的结果 不受其他语句的影响
SQL语言分类:
DDL:数据定义语言
create,alter,drop
DML:数据操纵语言
update,insert,delete
DCL:数据控制语言
grant,if
DQL:数据查询语言
select
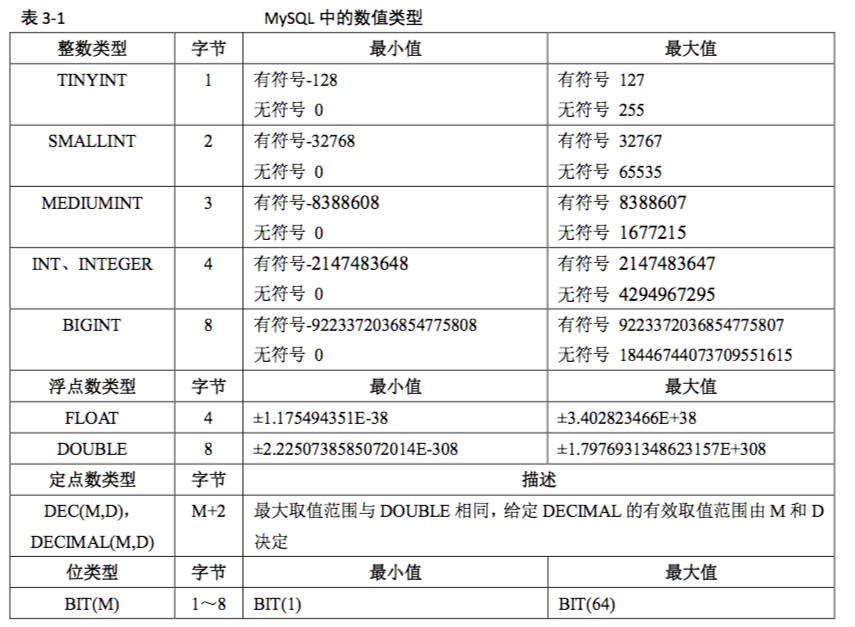
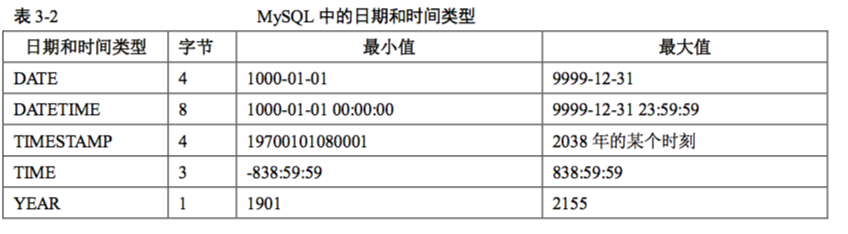
MySql数据类型:
整数:
tinyint、smallint、mediumint、int、bigint
浮点数:
float、double、real、decimal
日期和时间:
data time datatime timestamp year
注:timestamp有时间范围的限制,目前1970年之前月2037年之后的时间都不能使用timestamp,
而dateTime 支持的范围是'1000-01-01 00:00:00'到'9999-12-31 23:59:59'
字符串:
char varchar
文本:
tinytext text mediumtext longtext
二进制(可用来存储图片 音乐等):
tinyblob blob mediumblob longblob
注意: 如果超出类型范围的操作,会发生“Out of range”错误提示。

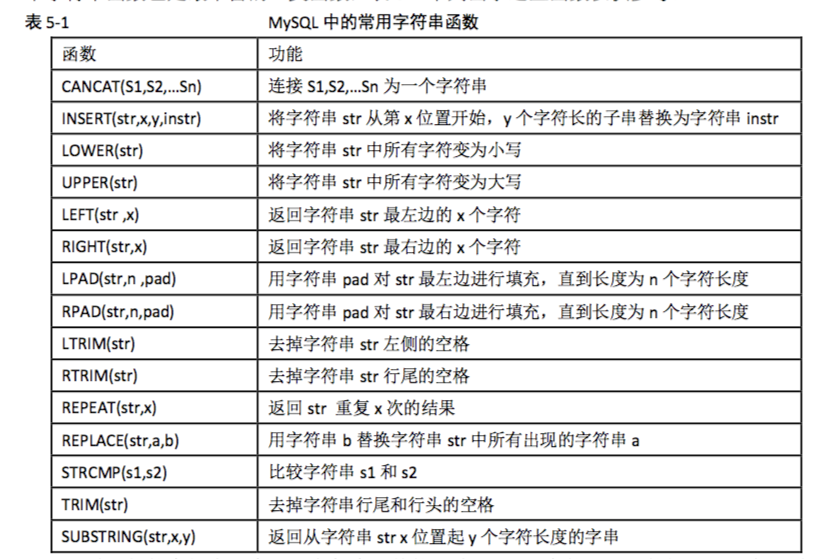
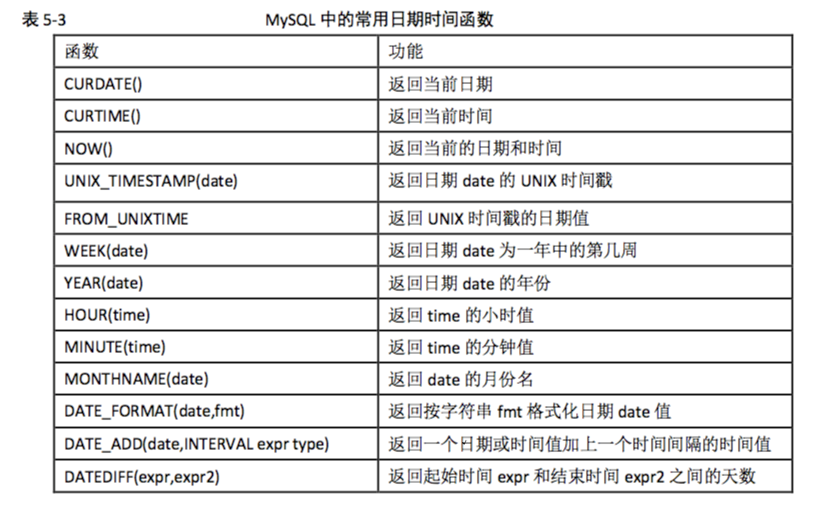
常用函数:
存储引擎:
查看引擎:
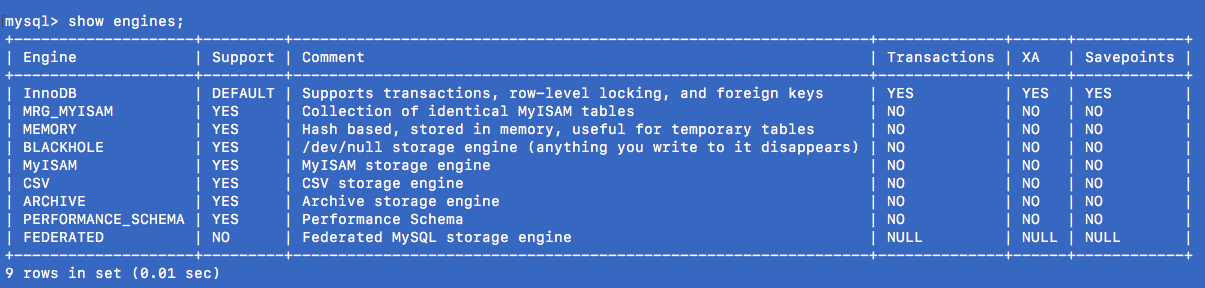
各种引擎的特性:
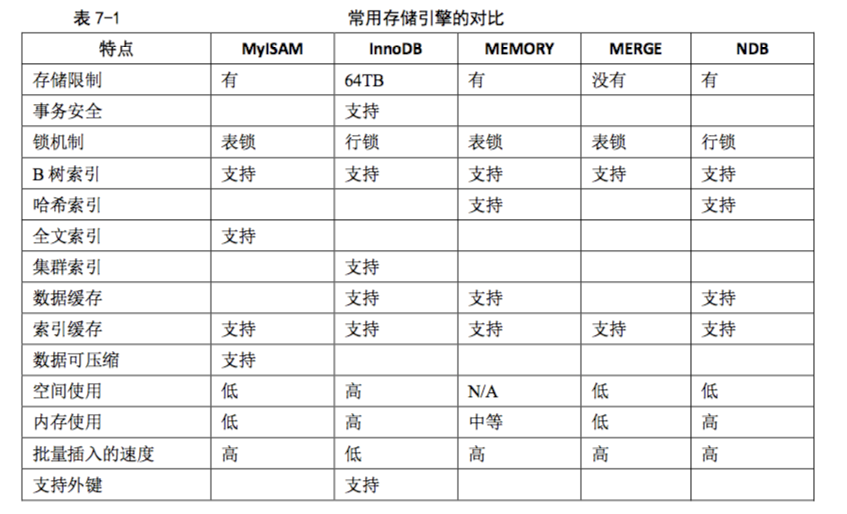
约束:
主键约束:primary key
唯一约束:unique
非空约束:not null
修改表:
alter table xxx add/drop motify 列名 (类型约束);
rename table xxx to yyy;
alter table xxx character set gbk;
多表查询:
交叉连接:
就是普通的查询 笛卡尔积
内连接:
(inner) join
显示内连接:
select * from a inner join b where 条件;
隐式内连接:
select * from a ,b where 条件;
外连接:
(outer) join
左外连接:
left out join
select * from a left out join b on 条件;
右外连接:
right out join
select * from a right out join b on 条件;
truncate和delete 删除记录的区别:
相同点:
1.truncate和不带where子句的delete、以及drop都会删除表内的数据。
2.drop、truncate都是DDL语句(数据定义语言),执行后会自动提交。
不同点:
1.truncate 和 delete 只删除数据不删除表的结构(定义)
drop 语句将删除表的结构被依赖的约束(constrain)、触发器(trigger)、索引(index);依赖于该表的存储过程/函数将保留,但是变为 invalid 状态。
2.delete 语句是数据库操作语言(dml),这个操作会放到 rollback segement 中,事务提交之后才生效;如果有相应的 trigger,执行的时候将被触发。
truncate、drop 是数据库定义语言(ddl),操作立即生效,原数据不放到 rollback segment 中,不能回滚,操作不触发 trigger。
3.delete 语句不影响表所占用的 extent,高水线(high watermark)保持原位置不动
drop 语句将表所占用的空间全部释放。
truncate 语句缺省情况下见空间释放到 minextents个 extent,除非使用reuse storage;truncate 会将高水线复位(回到最开始)。
4.速度,一般来说: drop> truncate > delete
5.安全性:小心使用 drop 和 truncate,尤其没有备份的时候.否则哭都来不及
使用上,想删除部分数据行用 delete,注意带上where子句. 回滚段要足够大.
想删除表,当然用 drop
想保留表而将所有数据删除,如果和事务无关,用truncate即可。如果和事务有关,或者想触发trigger,还是用delete。
如果是整理表内部的碎片,可以用truncate跟上reuse stroage,再重新导入/插入数据。
SQL书写顺序及执行顺序
4: select [distinct] 字段数据
1: from
inner join
left join
right join
2: where
3: group by having
5: order by
6. limit a,b a从哪开始 b查询的记录数
执行顺序
1-2-3-4-5-6
视图的特点
视图只是一种逻辑对象,是一种虚拟表,它并不是物理对象,因为视图不占物理存储空间,在视图中被查询的表称为视图的基表,大多数的select语句都可以用在创建视图中
优点:集中用户使用的数据,掩码数据的复杂性,简化权限管理以及为向其他应用程序输出而重新组织数据等等
语法: create view view_name [(column[,...n])]
with encryption
as select_statement
with check option
存储过程的特点
存储过程是存储在服务器上的一组预编译的Transact-SQL语句,存储过程是一种封装重复任务操作的一种方法,支持用户提供的变量,具有强大的编程功能
优点:与其他应用程序共享应用程序的逻辑,因此确保一致的数据访问和操纵
提供一种安全机制
加速存储过程的执行,提高系统的性能
减少网络交通
存储过程的类型:系统存储过程、本地存储过程、临时存储过程、远程存储过程和扩展存储过程。不同类型的存储过程具有不同的作用
语法: create procedure procedure_name
@parameter data_type
with{recompile|encryption|recompile,encryption}
as sql_statement
执行存储过程有两种方法:
方法一:直接执行存储过程,就是调用execute语句来执行存储过程
方法二:在insert语句中执行存储过程
触发器的特点
当有操作影响到触发器保护的数据时,触发器就自动发生,因此,触发器是在特定表上进行定义的,该表也称为触发器表,也是一种特殊类型的存储过程,与存储过程的区别:存储过程可以由用户直接调用执行,但是触发器不能被直接调用执行
触发器的类型:insert类型,update类型,delete类型
语法: create trigger trigger_name
on {table |view}
with encryprion
{for|after|instead of}{[delete][,][insert][,][update]}
as sql _statement
工作原理:
(insert)当向表中插入数据时,insert触发器触发执行,当insert触发器触发时,新的记录增加到触发器表中和inserted表中。触发器可以检查inserted表,来确定该触发器的操作是否应该执行和如何执行,在inserted表中的那些记录,总是触发器表中一行或多行记录的冗余;
(delete)当触发一个delete触发器时,被删除的记录房子一个特殊的deleted表中。deleted表是一个逻辑表,用来保存已经从表中删除的记录;
(update)修改一条记录就等于插入一条新记录和删除一条旧记录,当在某一个update触发器表的上面修改一条记录时,表中原来的记录移动到deleted表中,修改过的记录插入到了inserted表中,触发器可以检查deleted表和inserted表以及被修改的表。
索引:
设计索引原则:
(1) 搜索的索引列
(2) 使用唯一索引
(3) 使用短索引
(4) 利用最左前缀
(5) 不要过度索引
(6) 对于InnoDB存储引擎的表,按照一定的顺序保存,可以使用主键倒序查询
Explain用法:

1、id
语句的执行顺序标识,如果在语句中没有子查询或联合,说明只有一个SELECT,于是这个列显示为1,否则内层的SELECT会顺序编号.
2、select_type
显示了对应的查询是简单还是复杂SELECT
1) SIMPLE(简单SELECT,不使用UNION或子查询等)
2) PRIMARY(查询中若包含任何复杂的子部分,最外层的select被标记为PRIMARY)
3) UNION(UNION中的第二个或后面的SELECT语句)
4) DEPENDENT UNION(UNION中的第二个或后面的SELECT语句,取决于外面的查询)
5) UNION RESULT(UNION的结果)
6) SUBQUERY(子查询中的第一个SELECT)
7) DEPENDENT SUBQUERY(子查询中的第一个SELECT,取决于外面的查询)
8) DERIVED(派生表的SELECT, FROM子句的子查询)
9) UNCACHEABLE SUBQUERY(一个子查询的结果不能被缓存,必须重新评估外链接的第一行)
3、table
1)、显示对应行正在访问哪个表
2)、当FROM子句中有子查询或UNION时,table列是<derivedN>,其中N是id列对应的值
4、type
联合查询所使用的类型,type显示的是访问类型,是较为重要的一个指标,结果值从好到坏依次是:
system > const > eq_ref > ref >fulltext > ref_or_null > index_merge > unique_subquery >index_subquery > range > index > ALL
1)、system
系统表,表中只有一行数据;
2)、const
const是在where条件以常量作为查询条件,最多只会有一条记录匹配,由于是常量,实际上只须要读一次。
3)、eq_ref
最多只会有一条匹配结果,一般是通过主键或唯一键索引来访问。一般会出现在连接查询的语句中。
4)、ref
也叫索引查找,他返回所有匹配某单个值的行,它可能会找到多个符合条件行。
5)、fulltext
进行全文索引检索。
6)、ref_or_null
与ref的唯一区别就是在使用索引引用的查询之外再增加一个空值的查询。
7)、index_merge
查询中同时使用两个(或更多)索引,然后对索引结果进行合并(merge),再读取表数据。
8)、unique_subquery
子查询中的返回结果字段组合是主键或唯一约束。
9)、index_subquery
子查询中的返回结果字段组合是一个索引(或索引组合),但不是一个主键或唯一索引。
10)、range
索引范围扫描。一个有限制的索引扫描,它开始于索引里的某一点,返回匹配这个值域的行(显而易见的范围扫描.即带有BETWEEN或在WHERE子句中带有>的查询,当MySQL使用索引去查找一系列值的时候,如IN()和OR列表,也为显示的范围扫描)
11)、index
全索引扫描。MySQL在扫描表时按索引次序进行而不是行。
12)、all
全表扫描,效果是最不理想的。
5、possible_keys
这一列显示了查询可以使用哪些索引,是基于查询访问的列和使用的比较操作符来判断的.
如果没有任何索引可以使用,就会显示成null
6、key
显示了MySQL决定采用哪个索引来优化对该表的访问
1)、key_len列显示mysql决定使用的键长度,如果键是null,则长度为null。
2)、显示MySQL在索引里使用的字节数.举个例子就是在查询中使用到了主键,而主键的数据类型为INT,则为4,SMALLINT则为2
3)、使用的索引长度,一般越短越好。
8、Ref
显示了之前的表在key列记录的索引中查询值所用到的列或常量
9、rows
显示的是MySQL为了找到所需的值而要读取的行数.
10、extra
在此显示的是在其他列不适合显示的额外信息
Mysql优化:
a: 表的设计合理化(符合3NF,表的范式,是首先符合1NF, 才能满足2NF , 进一步满足3NF)
1NF: 即表的列的具有原子性,不可再分解,关系型数据库自动满足1NF.
2NF:表中的记录是唯一的, 就满足2NF, 通常我们设计一个主键来实现
3NF: 即表中不要有冗余数据,即能被推导出来的,就不应该单独设计一个字段来存放.
b: 添加适当索引(index) [四种: 普通索引、主键索引、唯一索引unique、全文索引]
c: 更小的数据类型
d: 尽量避免null
事务:
查看当前数据库的事务提交方式 1或者ON表示启用,0或OFF表示禁用。
show variables like 'autocommit';
set autocommit = 1;
mysql默认事务型引擎是Innodb,默认隔离级别是可重复读,当重复操作一条语句时可能产生幻行。
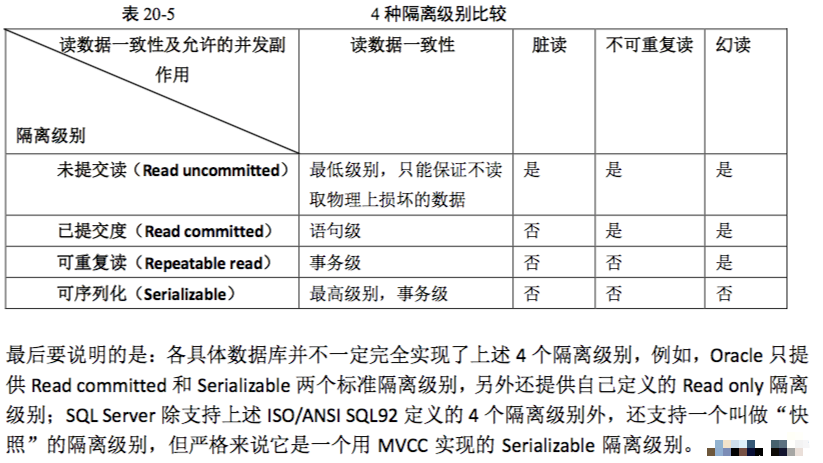
时间查询:
1、几个小时内的数据
DATE_SUB(NOW(), INTERVAL 5 HOUR)
2、今天
select * from 表名 where to_days(时间字段名) = to_days(now());
3、昨天
select * from 表名 WHERE TO_DAYS( NOW( ) ) - TO_DAYS( 时间字段名) <= 1;
4、7天
select * from 表名 where DATE_SUB(CURDATE(), INTERVAL 7 DAY) <= date(时间字段名);
5、近30天
select * from 表名 where DATE_SUB(CURDATE(), INTERVAL 30 DAY) <= date(时间字段名);
6、本月
select * from 表名 WHERE DATE_FORMAT( 时间字段名, '%Y%m' ) = DATE_FORMAT( CURDATE( ) , '%Y%m' );
7、上一月
select * from 表名 WHERE PERIOD_DIFF( date_format( now( ) , '%Y%m' ) , date_format( 时间字段名, '%Y%m' ) ) =1;