这篇文章 主要是 讲述 网易云音乐 歌词、歌曲的爬取,网易云音乐API的使用
参考文章:
网易云音乐API获取分析
网易云音乐的基本特点
首先想要爬取 网易云音乐的数据,首先 需要知道 他的歌曲结构、歌单结构、URL等
1. 网易云歌单页面分析
主要了解 歌单的结构 和 歌曲
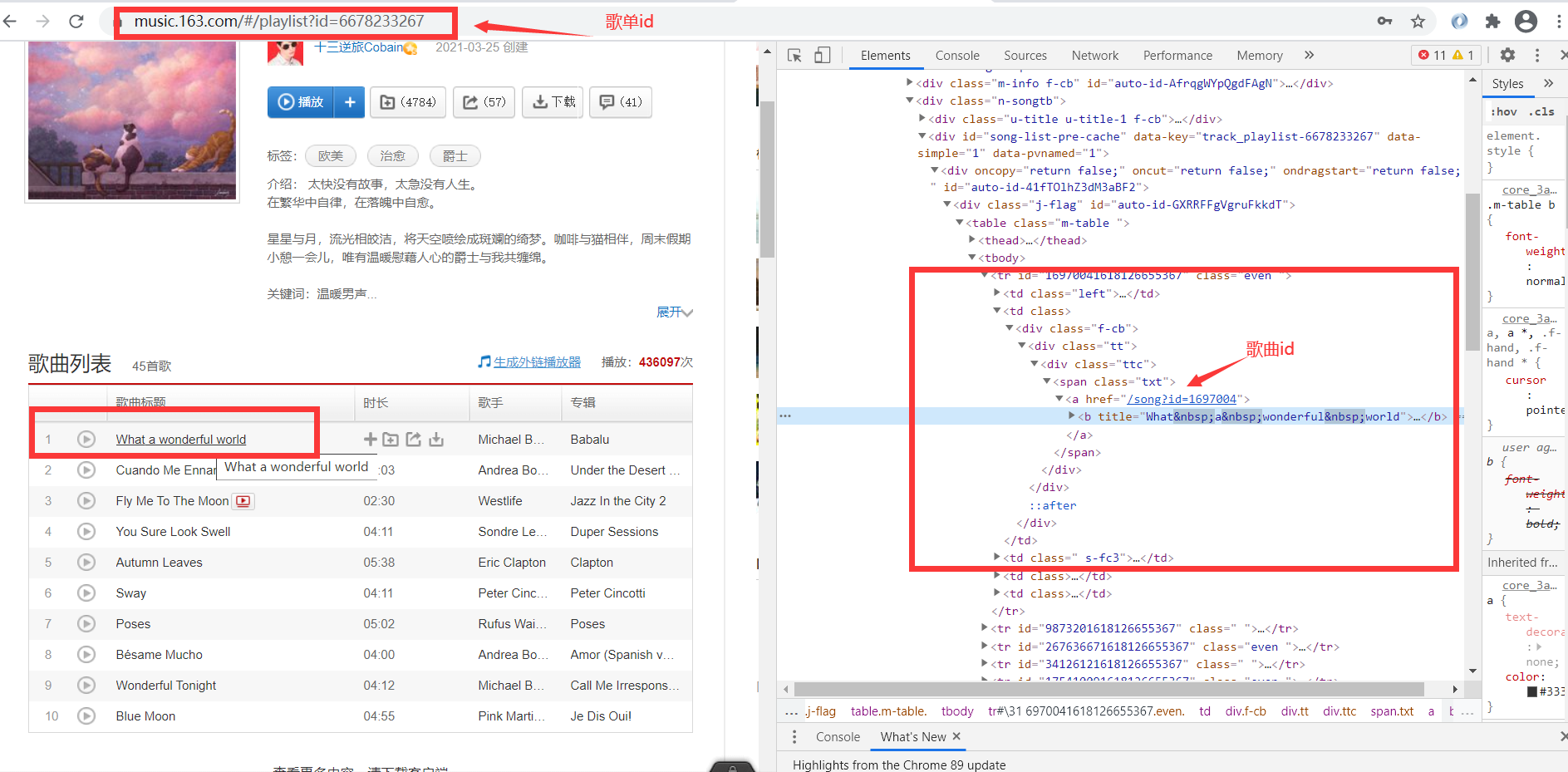
(印象中,url上的 #`` 是官方用于迷惑爬虫的,如果想 爬取官方网址,可以将 #` 去掉)
我们可以 记一下歌单id:6678233267、 歌曲id:1697004
然后 查看网易云api文档可以发现:
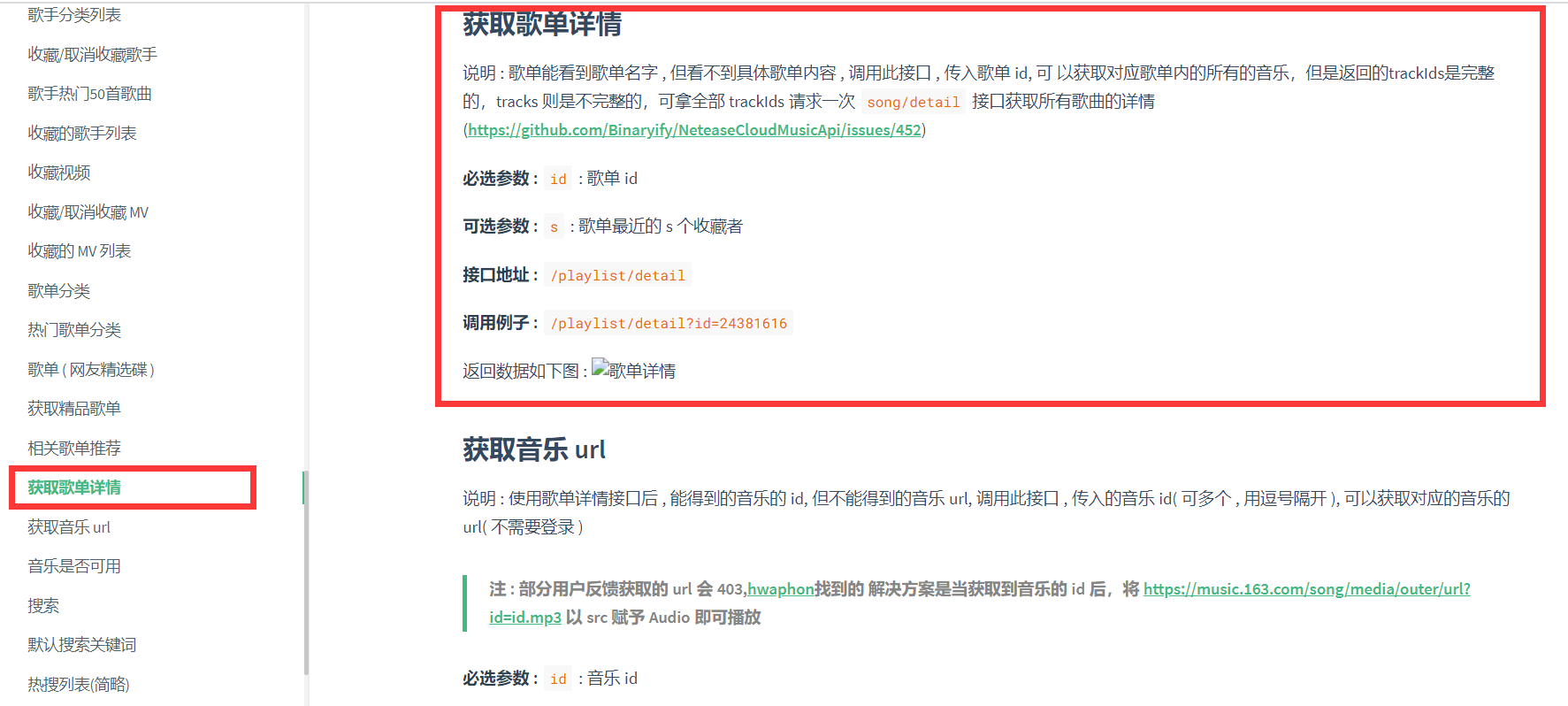
根据上面那个歌单id 调用接口可以得到结果:
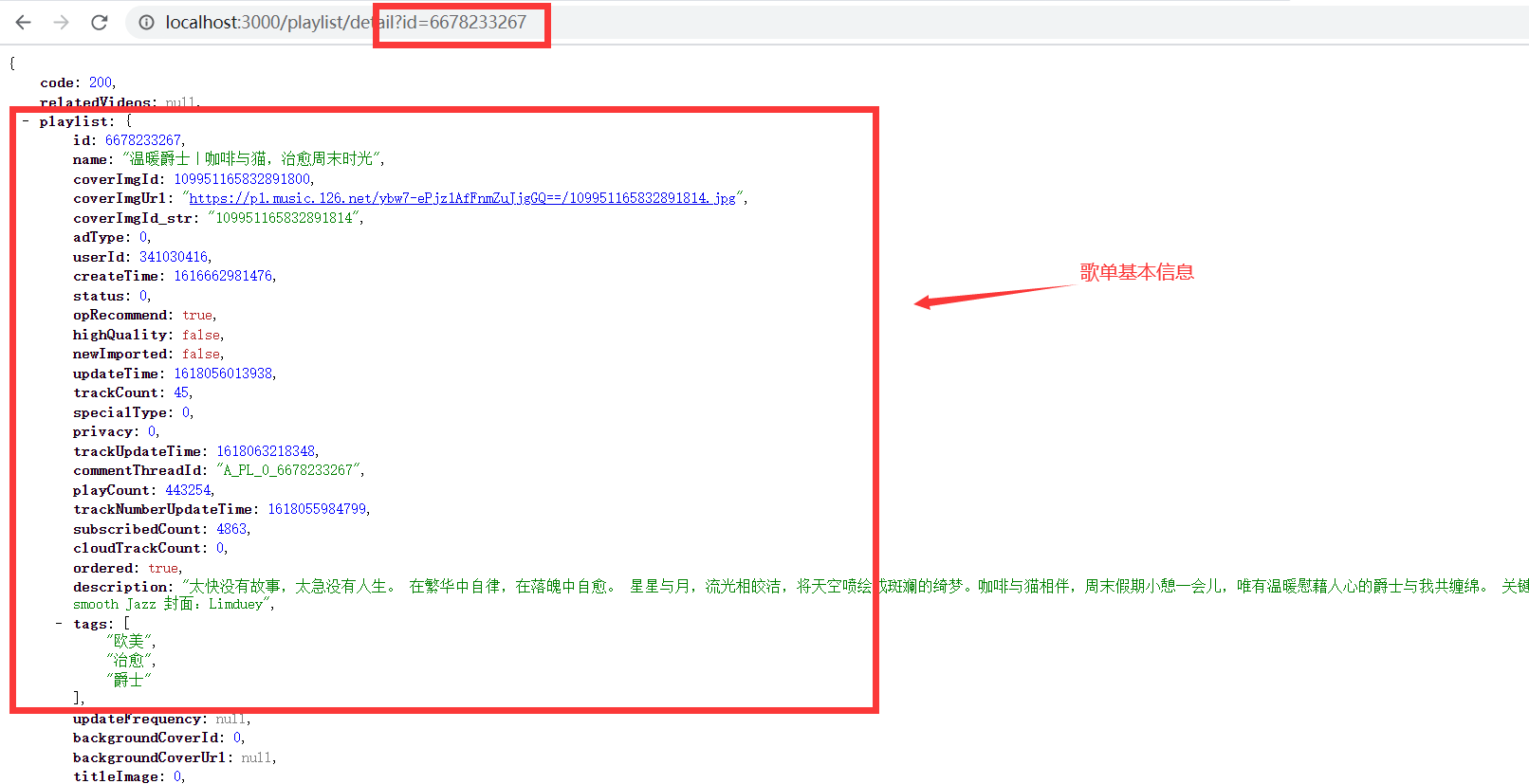
顺便说一句,浏览器 可以 使用一些json的插件,格式化后 比较好分析。
看到上面的数据结果,可以发现和官方的是一样的(毕竟这个api就是来自于官方 →_→)
但是这样的数据格式就比较分析 爬取,我们简单得到歌单信息
观察这个json信息可以发现:

通过这基本信息,我们可以得到 歌曲的id列表,之后可以通过歌曲id列表 爬取歌曲信息
2. 网易云歌曲具体信息分析
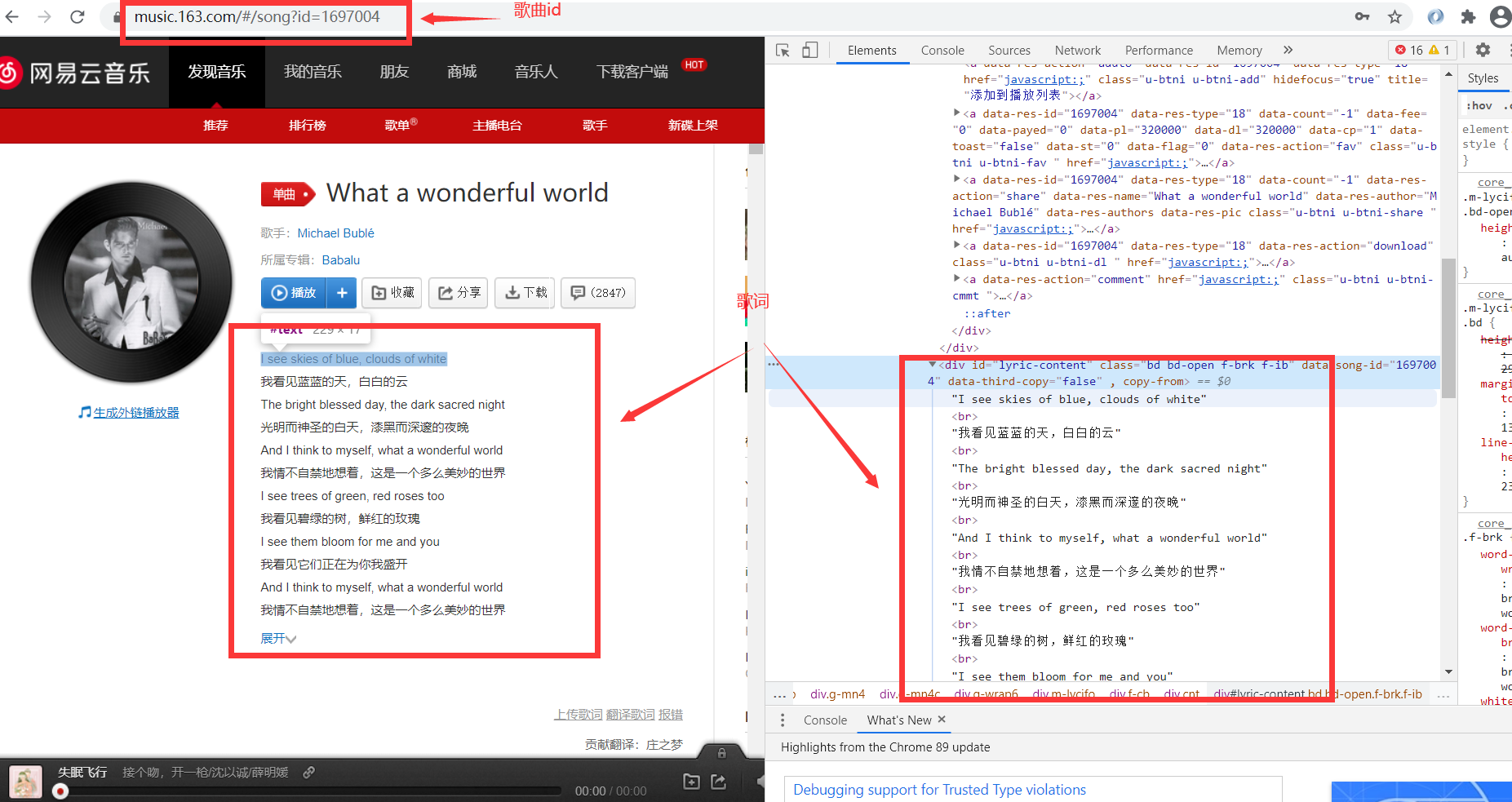
根据 网易云音乐api 查找 歌曲id 为1697004的信息
这以下几个接口就能 获取到 歌曲的基本信息了
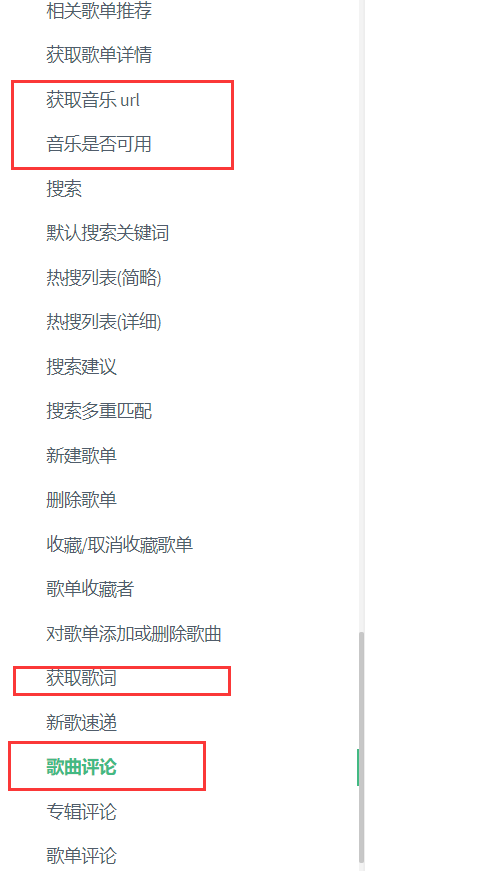
- 歌曲下载

可以尝试网上查找关于新的api使用方式
如笔者之前尝试访问的:
http://music.163.com/api/playlist/detail?id=6678233267获取歌单信息 和api文档上的结果 大部分相同 但 更加详细,如歌曲的作者、专辑等等
http://music.163.com/song/media/outer/url?id=1697004.mp3MP3资源下载,在下载前可以 通过上面截图的 查看该音乐是否可用,因为有些音乐已经下架,没有资源了 - 歌词获取
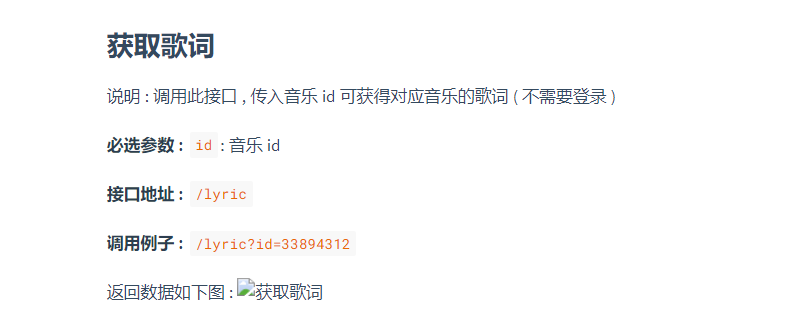

可以看到,歌词的结构,是每一段都为[xx:xx.xx] 为开头。可以通过一些字符串处理将其 裁剪得到数据。 - 歌曲评论

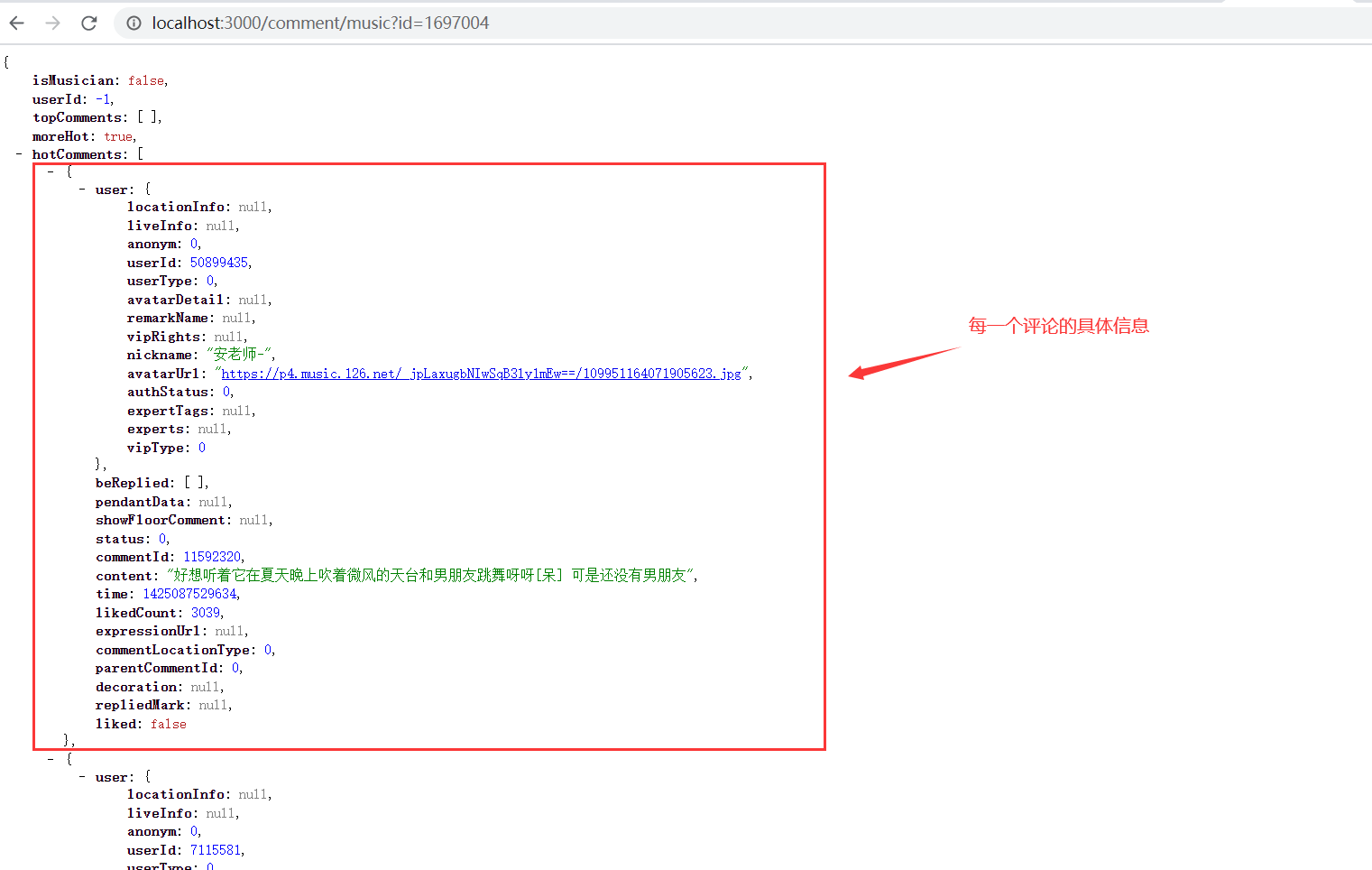
通过这些接口,歌曲的基本信息都可以获取到。
python 爬取音乐数据
前期基本知识
- 所需python库
requests、json、os - 基础信息设置
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/76.0.3809.132 Safari/537.36'}
true = True # json 关键字的转义
false = False # json 关键字的转义
null = None # json关键字的转义
1.获取歌单 歌曲列表信息
# 判断是否拥有mp3版权
def judge_song_url(song_id):
"""
判断音乐是否存在
:param song_id:
:return:
"""
url = "http://localhost:3000/check/music?id="+str(song_id)
html = requests.get(url).text
dict=eval(html)
return dict["success"]
# 转义 部分字符串存在 ' 和 " 的转义问题
def change(s):
"""
符号转义
:param s: 带有 " ' 字符
:return:
"""
s=s.replace("'", "\'")
s=s.replace('"', '\"')
return s
# 得到歌单
def get_songlist(listid,n):
"""
根据歌单id得到歌曲列表
:param listid:
:param n: 歌单中歌曲个数
:return:
"""
url = 'http://music.163.com/api/playlist/detail?id='+str(listid)
html = requests.get(url,headers=headers).text # 获取列表
dits = eval(html) # 转成字典数据类型
dits = dits["result"]
dits = dits["tracks"]
songs=[]
cnt = 0
for songmess in dits: # 遍历歌曲列表
song_id = str(songmess["id"])
if judge_song_url(song_id) == False: # 判断歌曲是否有用
continue;
song_name = songmess["name"]
song_name = change(song_name) # 转义
song_author = songmess["artists"]
song_author = song_author[0]
song_author = song_author["name"]
song_url = "http://music.163.com/song/media/outer/url?id=" + song_id + ".mp3"
song_lrc = get_lrc(song_id)
songs.append({
"song_id":song_id,
"song_name":song_name,
"song_author":song_author,
"song_lrc":song_lrc,
"song_url":song_url
})
cnt+=1
if cnt >= n:
break
print(cnt)
return songs
2.歌曲下载
通过 1. 得到歌曲列表后,就可以下载歌曲信息了
# 下载歌曲
def download_song(save_name,song_id):
"""
下载单曲
:param save_name:保存路径
:param song_id:歌曲id
:return:
"""
if judge_song_url(song_id)==False:
print("无歌曲版权")
return False
else:
song_url="http://music.163.com/song/media/outer/url?id="+str(song_id)+".mp3"
res = requests.get(song_url, headers=headers)
music = res.content
with open(save_name, 'wb') as file:
file.write(music)
file.flush()
file.close()
return True
3.歌词下载
# 获取单首歌歌词
def get_lrc(song_id):
"""
根据id得到时间轴的歌词
:param song_id:歌曲id
:return:
"""
url = 'http://localhost:3000/lyric?id='+str(song_id)
html = requests.get(url).text
dits = eval(html)
if 'lrc' in dits.keys():
tmp = dits["lrc"]
lrc = tmp["lyric"]
else:
lrc=" "
return lrc
def download_lrc(file_name,song_id):
"""
下载歌词
:param song_id:
:return:
"""
lrc = get_lrc(song_id)
with open(file_name,'w',encoding='utf-8') as file:
file.write(lrc)
file.close()