post 新增
get 查询
put更新
post http://127.0.0.1:9200/index4/type1
{"node":0}
{
"_index": "index4",
"_type": "type1",
"_id": "W_WMOHYBA6aNNN1EWEI0",
"_version": 1,
"result": "created",
"_shards": {
"total": 2,
"successful": 1,
"failed": 0
},
"_seq_no": 0,
"_primary_term": 1
}
查询:
http://127.0.0.1:9200/index4/type1/_search
{
"took": 2,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 2,
"relation": "eq"
},
"max_score": 1.0,
"hits": [
{
"_index": "index4",
"_type": "type1",
"_id": "W_WMOHYBA6aNNN1EWEI0",
"_score": 1.0,
"_source": {
"node": 0
}
},
{
"_index": "index4",
"_type": "type1",
"_id": "XPWROHYBA6aNNN1EL0Ig",
"_score": 1.0,
"_source": {
"node": 0,
"age": 3
}
}
]
}
}
刚学有点懵懵的....
之前安装了es的ik分词器,继续试试...
IK分词效果有两种,一种是ik_max_word(最大分词)和ik_smart(最小分词)
post http://127.0.0.1:9200/_analyze
请求参数
{
"analyzer":"ik_smart",
"text":"中国abc"
}
返回
{
"tokens": [
{
"token": "中国abc",
"start_offset": 0,
"end_offset": 5,
"type": "CN_WORD",
"position": 0
}
]
}
如果是最细力度划分:
请求
{
"analyzer":"ik_max_word",
"text":"中国abc"
}
返回:
{
"tokens": [
{
"token": "中国",
"start_offset": 0,
"end_offset": 2,
"type": "CN_WORD",
"position": 0
},
{
"token": "abc",
"start_offset": 2,
"end_offset": 5,
"type": "ENGLISH",
"position": 1
}
]
}
如果有些词我们不想拆看怎么办,配置自己的分词配置:
打开ik/config/IKAnalyzer.cfg.xml
<?xml version="1.0" encoding="UTF-8"?> <!DOCTYPE properties SYSTEM "http://java.sun.com/dtd/properties.dtd"> <properties> <comment>IK Analyzer 扩展配置</comment> <!--用户可以在这里配置自己的扩展字典 --> <entry key="ext_dict">player3.dic</entry> <!--用户可以在这里配置自己的扩展停止词字典--> <entry key="ext_stopwords"></entry> <!--用户可以在这里配置远程扩展字典 --> <!-- <entry key="remote_ext_dict">words_location</entry> --> <!--用户可以在这里配置远程扩展停止词字典--> <!-- <entry key="remote_ext_stopwords">words_location</entry> --> </properties>
新建player3.dic文件,写入自己的分词配置
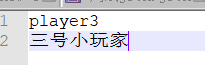
重启es项目
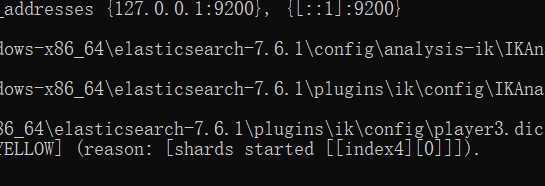
加载自己的配置文件
{
"analyzer":"ik_smart",
"text":"我非常喜欢三号小玩家他的网民player3是我喜欢的类型"
}
{
"tokens": [
{
"token": "我",
"start_offset": 0,
"end_offset": 1,
"type": "CN_CHAR",
"position": 0
},
{
"token": "非常",
"start_offset": 1,
"end_offset": 3,
"type": "CN_WORD",
"position": 1
},
{
"token": "喜欢",
"start_offset": 3,
"end_offset": 5,
"type": "CN_WORD",
"position": 2
},
{
"token": "三号小玩家",
"start_offset": 5,
"end_offset": 10,
"type": "CN_WORD",
"position": 3
},
{
"token": "他",
"start_offset": 10,
"end_offset": 11,
"type": "CN_CHAR",
"position": 4
},
{
"token": "的",
"start_offset": 11,
"end_offset": 12,
"type": "CN_CHAR",
"position": 5
},
{
"token": "网民",
"start_offset": 12,
"end_offset": 14,
"type": "CN_WORD",
"position": 6
},
{
"token": "player3",
"start_offset": 14,
"end_offset": 21,
"type": "CN_WORD",
"position": 7
},
{
"token": "是",
"start_offset": 21,
"end_offset": 22,
"type": "CN_CHAR",
"position": 8
},
{
"token": "我",
"start_offset": 22,
"end_offset": 23,
"type": "CN_CHAR",
"position": 9
},
{
"token": "喜欢",
"start_offset": 23,
"end_offset": 25,
"type": "CN_WORD",
"position": 10
},
{
"token": "的",
"start_offset": 25,
"end_offset": 26,
"type": "CN_CHAR",
"position": 11
},
{
"token": "类型",
"start_offset": 26,
"end_offset": 28,
"type": "CN_WORD",
"position": 12
}
]
}
ok啦