a.数字类型
int(整型)
在32位机器上,整数的位数为32位,取值范围位-2**31~2**31-1
在64位系统上,整数的位数为64位,取值范围为-2**63~2**63-1
long(长整形):python没有限制长整数数值的大小(py3不再有long类型)
float(浮点型):python默认17位精度,小数点后16位
complex(复数):(1-2j),(-2+3j)
b.字符串 (一个有序的字符的集合,用于存储和表示基本的文本信息,一对单、双 或 三引号之间包含的内容)
有序、不可变
name = 'q1ang'
name2 = "q1ang"
name = '''q1ang'''
字符串的拼接:
name='q1ang'
name2="q2ang"
print(name+name2+'='*10)
q1angq2ang==========
首字母大写,其他字母变小写: a.capitalize()
大写变小写: a.casefold()
补位: a.center(20,'-') → '-----hello word-----'
统计数量: a.count('l') 、 a.count('l',开始,结束)
判断结尾: a.endswith('1') 、 a.startswith('l')
更改tab默认长度:
b = 'q q' print(b) print(b.expandtabs(10))
q q
q q
查找: a.find('a') 找到输出位置,没找到输出-1 a.find('a',开始,结束)
格式化输出(format):
print('My name is {0},i am {1} years old'.format('q1ang',26)) print('My name is {name},i am {age} years old'.format(name='q1ang',age=26)) >>> My name is q1ang,i am 26 years old
返回索引值: a.index('l',开始,结束)
是否含有数字和字母: a.isalnum()
是否只有字母: a.isalpha()
是否只包含十进制字符: a.isdecimal()
是否只由数字组成: a.isdigit()
是否是合法的变量名: a.isidentifier()
包含的英文是否小写: a.islower()
是否只由数字组成: a.isnumeric()
所有单词首字母是否为大写: a.istitle()
拼接列表为字符串:
b=['aa','bb','cc'] print('='.join(b)) >>> aa=bb=cc
字符串左对齐,并使用空格或字符填充至指定长度: a.ljust(15,'-') → Hello world----
转小写: a.lower() 、转大写: a.upper()
去除两边制定的字符: a.strip('d') 默认为空格、去除左边: a.lstrip() 、去除右边: a.rstrip()
c.布尔型
TrueFalse(真假),逻辑判断
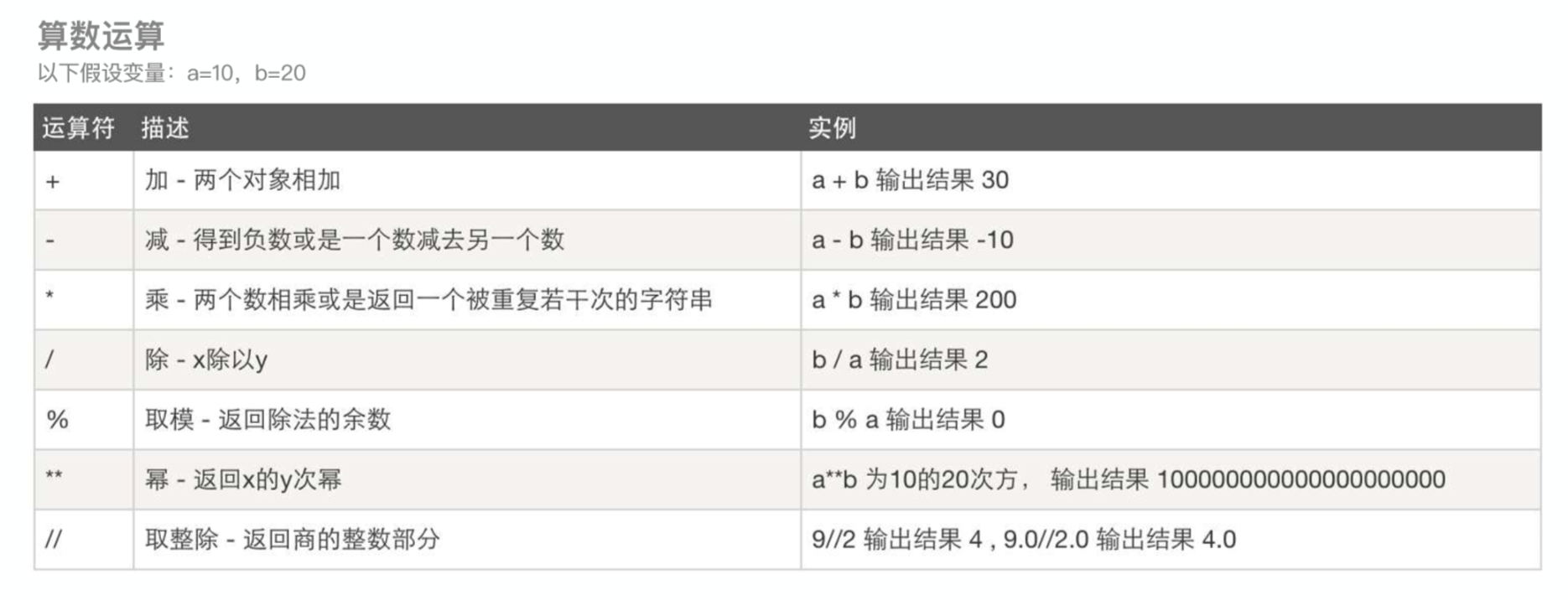
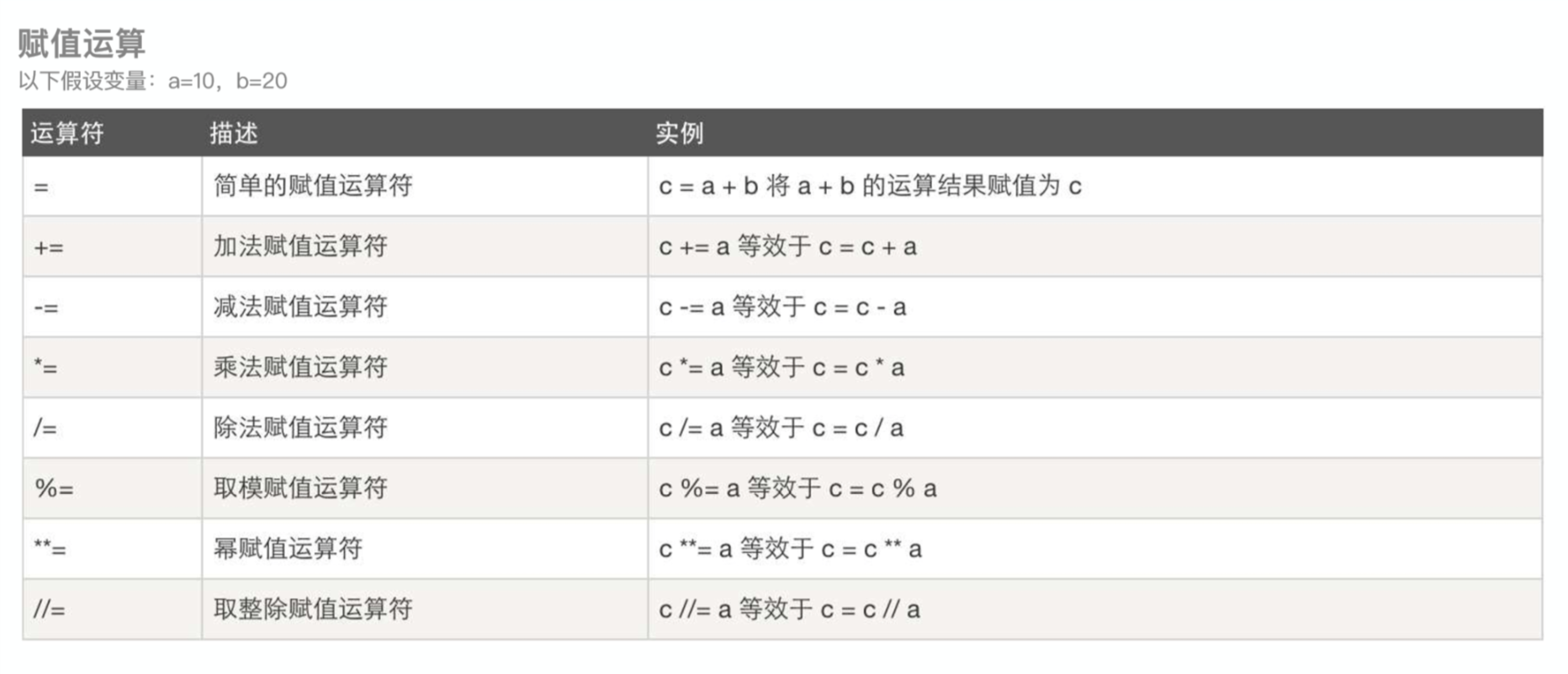
- 运算符


d.列表list a = ['b','c','d']或a = list(['b','c','d'])
索引: a.index('d') -> 2
切片:
a[::] #列出所有元素,a[起始:终止:步长] a[-1] #列出最后以一个元素 a2[len(a)/2] #从中间开始,列出后面的元素 ???
追加:
a.append('e') -> ['b','c','d','e']
插入:
a.insert(2,'f') -> ['b','c','f','d']
删除:
a.pop() -> ['b','c',] #删除最后一个 a.pop(1) -> ['b','d'] #删除第n个元素 a.remove('c') -> ['b','d'] #删掉制定的某个值,默认删除第一个 del a[1] -> ['b','d'] #删除第n个元素
清空: a.clear() -> []
统计元素出现的次数: acount('b')
反转: a.reverse() -> ['d','c',‘b']
按ascii码排序: a.sort()不能排序同时有str,int类型的列表
扩展: a.extend(a2)
拼接: a+b
长度: len(a) -> 3
循环:
a=[1,2,3,4,5] for i in a: print(i)
a=[1,2,3,4,5] for index,iter in enumerate(a): print(index,iter) >>> 0 1 1 2 2 3 3 4 4 5
copy:
e.tuple(元组) a = ('b','c','d') #不可变列表
f.hash(哈希)
散列,把任意长度的输入通过散列算法,变换成固定长度的输出,该输出就是散列值。这种转换是一种压缩映射,不同的输入可能会散列成相同的输出,所以不可能从散列来唯一的确定输入值(不能反解)。
用于文件签名、MD5加密、密码验证
不可变类型才可被hash,数字、字符串、元组, hash('q1ang')
g.dict(字典):a = {'b':1,'c':2,'d':3} #字典是无序的,键必须独一无二,键不能使用列表,查找速度快
索引: a['b'] 、 ‘b' in a 、 a.get('b')
新增/新增: a['e'] = 4
删除: del a['e'] 、 a.clear() 、 del a 、 a.pop('b')
长度: len(a)
比较: cmp(a,a1) 输出字典可打印的字符串:str(a)
打印key: a.keys() 、打印value: a.values()
将key和value转换为一个列表,列表每个元素为一个元组: a.items()
合并: a.update(b) 有相同key就使用b中的key
如果有指定key,则返回值为value,如果没有指定key,则设定key和value: a.setdefault('a','aa')
a.fromkeys(['a','b','c'],'d')
h.set(集合) a = {1,2,3} b = {3,4,5}
交集: a.intersection(b) 、 a & b
差集: a.difference(b) 、 a - b or b.difference(a) 、 b - a
并集: b.union(a) 、 b | a
对称差集: a.symmetric_difference(b) = (a | b)-(a & b) → {1, 2, 4, 5}
超集: a.issuperset(b) 、 a >= b
子集: a.issubset(b) 、 a <= b
是否不交集: a.isdisjoint(b)