作为一个测试人员,需要做性能测试时候,如果没有实际数据,或者实际数据不适合做压测,就要自己着手造数据了。
以下面的接口测试为例,简单介绍下需要的数据:
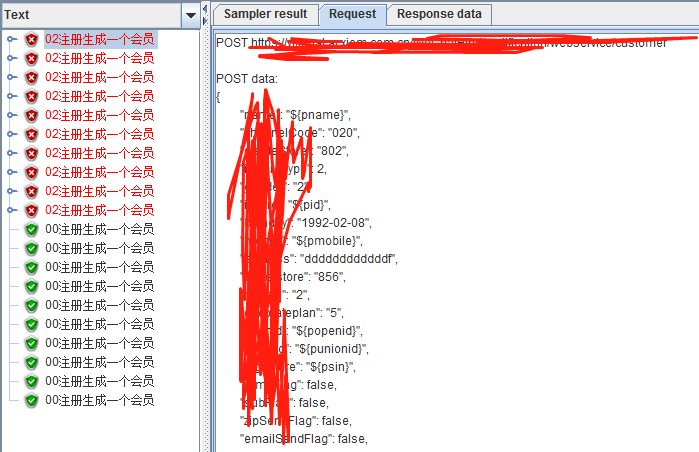
这是一个会员注册接口,入参比较多,你可以选用全部必填字段,忽略非必填字段,你也可以选用所有入参来进行测试; 我这里就选用了下面的入参
一般注册接口中,邮箱,手机号,身份证号,openid,unionid都是必须唯一的,不能与已经存在的会员重复。
这个时候造数据就需要造一些唯一的邮箱,手机号,身份证号和openid,unionid。
CREATE TABLE LoadTestTable
(
ID INT IDENTITY(1,1),
NAME VARCHAR(50),
GENDER INT,
HEIGHT INT,
MOBILE BIGINT,
IDnum VARCHAR(50),
singautre VARCHAR(50),
OPENID VARCHAR(50),
UNIONID VARCHAR(50),
MEMO VARCHAR(50)
);
如上先创建了一张表,你可以创建临时表 #LoadTestTable,但是这边我最近可能要用2-3天,而且在一个单独的QA数据库,我可以任性一点,创建一个物理表。^_^
DECLARE @NAME VARCHAR(50)
DECLARE @GENDER INT
DECLARE @HEIGHT INT
DECLARE @MOBILE BIGINT
DECLARE @IDNUM VARCHAR(50)
DECLARE @OPENID VARCHAR(50)
DECLARE @UNIONID VARCHAR(50)
DECLARE @SINGAUTRE VARCHAR(50)
DECLARE @VAR INT
SET @VAR=1000
SET @MOBILE = 21111173440
WHILE @VAR<10000
BEGIN
SET @NAME = '微信小程序' +CONVERT(VARCHAR(50),@VAR);
SET @GENDER=1;
SET @HEIGHT=160;
SET @MOBILE = @MOBILE+1;
SET @IDNUM = 'ABCD12341QAZ12' + CONVERT(VARCHAR(50),@VAR);-----18位身份证
SET @OPENID = 'OPENID1234'+ CONVERT(VARCHAR(50),@VAR);
SET @UNIONID = 'UNIONID1111'+ CONVERT(VARCHAR(50),@VAR);
INSERT LOADTESTTABLE(NAME,GENDER,HEIGHT,MOBILE,IDNUM,SINGAUTRE,OPENID,UNIONID)
VALUES(@NAME,@GENDER,@HEIGHT,@MOBILE,@IDNUM,NULL,@OPENID,@UNIONID)
SET @VAR=@VAR+1
END
先用while循环生成了9000个会员,这些会员姓名不一样,手机号不一样,等等。
身份证这边主要用了18位,并没有完全遵守国家规定的身份证格式。
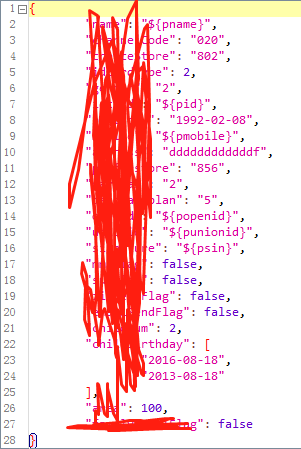
大概看一下测试数据:

报文中加密字段,签名需要注意下,这边我没有一步计算出来,放在了第二步
UPDATE A
SET A.SINGAUTRE = SUBSTRING(SYS.FN_VARBINTOHEXSTR(HASHBYTES('MD5', CONVERT(VARCHAR(50),B.GENDER)+'XXX')),3,32)
FROM LOADTESTTABLE B
JOIN LOADTESTTABLE A ON A.ID = B.ID
这边根据性别随意计算了一下对应的MD5 32位加密后的值,由于性别是int类型,这边转换了一下,否则会有报错 Argument data type int is invalid for argument 2 of hashbytes function.

因为性别一样,计算出的签名也是一样的,实际应用中当然不会选择这个字段,这选择别的字段,或者多个字段
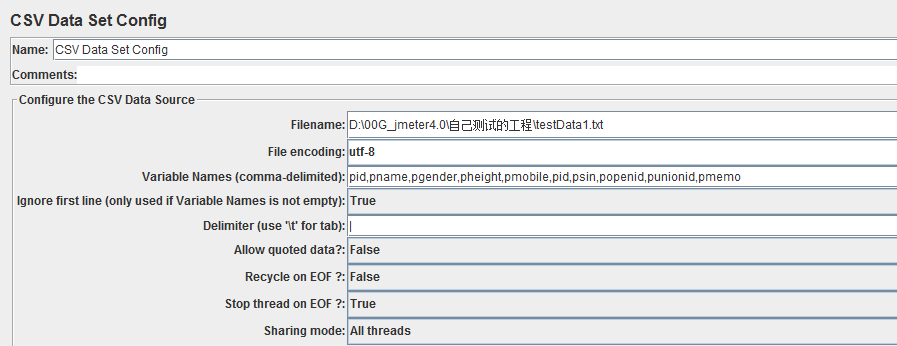
得到希望的数据到,SELECT * FROM LOADTESTTABLE,将数据复制到一个excel或者txt文档中,添加Jmeter的元件CSV Data Set Config进行配置即可
以下是CSV Data Set Config各个参数的简要说明:
FileName:即同目录下csv文件的名称,如果不是同目录,请给出绝对路径
File Encoding: 默认为ANSI,你看一下你保存文件的格式,一般都用utf-8
Varible Names: 定义文本文件中的参数名,参数之间逗号分隔.定义后可在脚本在以Shell变量的同样的方式引用,必须要一一对应,不能写漏了,否则会出错哦
Ignore first line(Only used if Variable Name is not set):我的数据文件中第一行是字段名不是测试数据,要忽略
Delimiter:数据文件的分隔符,我这边是|
Allow Quoated data: 双引号相关
Recycle on EOF: 设置为True后,允许循环取值 EOF 是end of file,数据文件中数据都用完了,要不要从头再来,我这边不需要,设置False
Stop Thread on EOF: 当Recycle on EOF为false并且Stop Thread on EOF为true,则读完csv文件中的记录后,停止运行
Sharing Mode: 设置是否线程共享
我的数据文件如下:

我的设置如下
Recycle on EOF和Stop Thread on EOF
我以前一直忽略这两个参数的使用,一般做性能测试,我准备的数据比最终要使用的都多很多(造测试数据反正不要钱么^_^)
Until one time,第三方没有能将粉丝券同步给我们,希望将数据以文件形式导给我们,让我们手工插入数据库;
support担心在生产数据库上直接插入会影响效率,毕竟当时还有很多人在不停地领取粉丝券,我们以前也出现过某张表效率低下,不记录一些类似log记录到表中的情况
于是,我自告奋勇地说,让我来用接口插入数据吧,我加上思考时间,这个接口我以前在QA上压测过,巴拉巴拉·······不会有问题的,于是PM就同意了,于是我留下来加班哈哈哈哈哈 ^_^
当时没有更改Recycle on EOF和Stop Thread on EOF,最终的结果是发现一些券同步的时候有失败,一看是数据用完了,我查看了请求的总数大于文件的总数

顺便测了一下Jmeter 4.0中的共享模式:
放置位置如图:


还有发现的接口问题: 同一条数据发出多个请求,因为手机号身份证等未入库,或者说同时入库,一条数据分成的多个请求,最终会生成多个数据。【已解决】
如果放置的位置在当前线程下,那么只能是当前线程组的,不会共享给别的线程组,这个位置关系和查看结果树不同。