一、处理缺失数据
pandas对象的所有描述性统计默认都不包括缺失数据。
缺失数据在pandas中呈现的⽅式有些不完美,但对于⼤多数⽤户可以保证功能正常。
对于数值数据,pandas使⽤浮点值NaN(Not a Number)表示缺失数据。我们称其为哨兵值,可以⽅便的检测出来。
在pandas中,我们采⽤了R语⾔中的惯⽤法,即将缺失值表示为NA,它表示不可⽤not available。
在统计应⽤中,NA数据可能是不存在的数据或者虽然存在,但是没有观察到(例如,数据采集中发⽣了问题)。
当进⾏数据清洗以进⾏分析时,最好直接对缺失数据进⾏分析,以判断数据采集的问题或缺失数据可能导致的偏差。
Python内置的None值在对象数组中也可以作为NA。

二、滤除缺失数据
2.1 Series
import pandas as pd from numpy import nan as NA series_1 = pd.Series([1,2,3,4,NA]) series_1[1] = None series_2 = series_1.dropna() series_3 = series_1[series_1.notnull()] #等同于 series_1.dropna() print('series_1 ', series_1) print(' series_2 ', series_2) print(' series_3 ', series_3)

2.1 DataFrame
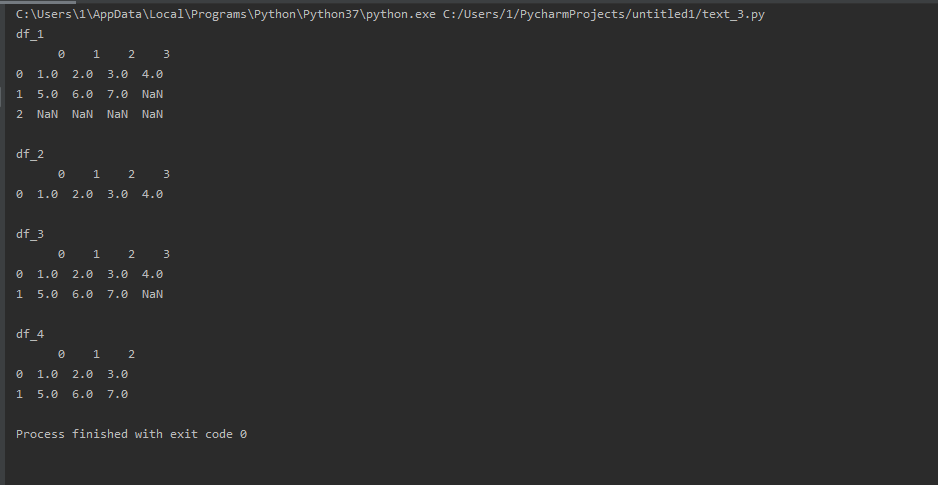
import pandas as pd from numpy import nan as NA df_1 = pd.DataFrame([[1, 2, 3, 4], [5, 6, 7, NA], [NA, NA, NA, NA]]) df_2 = df_1.dropna() # 丢弃带NA的行 df_3 = df_1.dropna(how='all') # 丢弃全部为NA的行 df_4 = df_3.dropna(axis=1) # 丢弃带NA的列 print('df_1 ', df_1) print(' df_2 ', df_2) print(' df_3 ', df_3) print(' df_4 ', df_4)
三、填充缺失值
可能不想滤除缺失数据(有可能会丢弃跟它有关的其他数据),⽽是希望通过其他⽅式填补那些“空洞”。对于⼤多数情况⽽⾔,fillna⽅法是最主要的函数。
通过⼀个常数调⽤fillna就会将缺失值替换为那个常数值:
import pandas as pd import numpy as np from numpy import nan as NA df_1 = pd.DataFrame(np.random.randn(4, 3)) df_1.iloc[2:, 1] = NA df_1.iloc[4:, 2] = NA df_2 = df_1.fillna(0) df_3 = df_1.fillna({1: 1, 2: 2}) # 对reindexing有效的那些插值⽅法也可⽤于fillna df_4 = df_1.fillna(method='ffill', limit= 2) #method='ffill' 向上取值;limit= 2 只操作2行 df_5 = df_1.fillna(df_1.mean()) # 填充平均值 print('df_1 ', df_1) print(' df_2 ', df_2) print(' df_3 ', df_3) print(' df_4 ', df_4) print(' df_5 ', df_5)

