背景
软件版本:python3.7
pyhton IDE Pycharm。
需求说明:
每天有人给我微信发excel表格,然后我需要上传到数据库。
发送的excel表格,名称有规律,都是名称+日期格式。
比如:“测试_2020-01-01.xlsx”,“测试_2020-01-02.xlsx”。
有时会出现一些问题:
excel的文件格式:主要分为csv、xls、xlsx。
excel的字段和数据库字段不一致:主要是字段数不一致,字段名称不一致(代表的含义可能一致)
excel中的一些行数据是不需要的。
一、数据库配置
# encoding:utf-8 import pymysql.cursors class MysqlOperation(object): def __init__(self, config): self.connection = pymysql.connect(host=config['mysql_host'], port=config['mysql_port'], user=config['mysql_user'], # pymysql直接连接是passwd,用连接池连接是password passwd=config['mysql_passwd'], db=config['mysql_db'], charset='utf8', cursorclass=pymysql.cursors.DictCursor ) def read_sql(self, sql): with self.connection.cursor() as cursor: try: cursor.execute(sql) result = cursor.fetchall() return result except Exception as e: self.connection.rollback() # 回滚 print('事务失败', e) def insert_sql(self, sql): with self.connection.cursor() as cursor: try: cursor.execute(sql) self.connection.commit() except Exception as e: self.connection.rollback() print('事务失败', e) def update_sql(self, sql): # sql_update ="update user set username = '%s' where id = %d" with self.connection.cursor() as cursor: try: cursor.execute(sql) # 像sql语句传递参数 # 提交 self.connection.commit() except Exception as e: # 错误回滚 self.connection.rollback() def delect_sql(self, sql_delete): with self.connection.cursor() as cursor: try: cursor.execute(sql_delete) # 像sql语句传递参数 # 提交 self.connection.commit() except Exception as e: # 错误回滚 self.connection.rollback() def read_one(self, sql): with self.connection.cursor() as cursor: try: cursor.execute(sql) result = cursor.fetchone() return result except Exception as e: self.connection.rollback() # 回滚 print('事务失败', e) def reConnect(self): try: self.connection.ping() except: self.connection()
二、excel,mysql,python字段说明
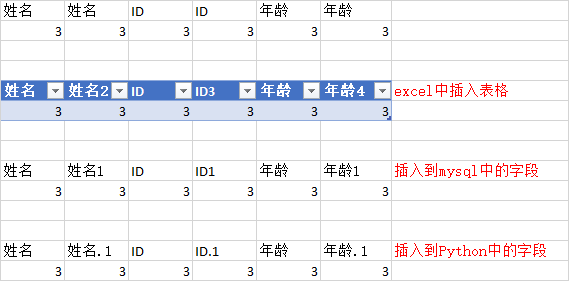
最上面的表格未原始表格,在几种不同情况下,字段的变化是不同的。
三、解决问题
3.1 读取不同格式的excel
import pandas as pd file_path_csv = r'C:Users1Desktop博客测试.csv' df_csv = pd.read_csv(file_path_csv, encoding='gbk') file_path_xls = r'C:Users1Desktop博客测试.xls' df_xls = pd.read_excel(file_path_xls) file_path_xlsx = r'C:Users1Desktop博客测试.xlsx' df_xlsx = pd.read_excel(file_path_xlsx)
说明:默认encoding = 'utf-8'。注意读取csv格式时的enconding。
3.2 字段问题
3.2.1 字段数不一致
解决的方法是重新索引,使用reindex。
reindex对于已有的字段,对应的值不变。对于没有的字段则为nan。
3.2.2 重命名字段
有些字段虽然名字不一样,但是代表的含义是一样的。比如excel字段“姓名”对应数据库字段“name”。
使用rename可以解决。
import pandas as pd file_path_xlsx = r'C:Users1Desktop博客测试.xlsx' df = pd.read_excel(file_path_xlsx) df.rename(columns={'姓名':'name'}, inplace=True)
此时便完成了对“姓名”重命名为“name”,其他不变。
3.3 对行进行筛选
具体的可以看一下我的这篇博客:https://www.cnblogs.com/qianslup/p/11898665.html 中的筛选数据
四、代码展示
import xlwt import xlrd import os import numpy as np from sqlConnect import MysqlOperation import pymysql import pandas as pd import math import datetime # 配置数据库 config = {'mysql_host': 'xxx', 'mysql_port': 0000, 'mysql_user': 'xxx', 'mysql_passwd': 'xxx', 'mysql_db': 'xxx' } mysql = MysqlOperation(config=config) def read_excel(path_file): df = pd.read_excel(path_file, sheet_name='Sheet1') columns_1 = [column for column in df] columns = [str(column).replace('.', '') for column in df] # 将字段在python中的“.1”转化为mysql中的“1”且字符串化 columns_dict = dict(zip(columns_1, columns)) df.rename(columns=columns_dict, inplace=True) # 重命名字符串字段 df.dropna(how='all') df.fillna('Null', inplace=True) # 填入“null"是为了与下面的sql_insert对应。 names = ['姓名', '姓名1', 'ID', 'ID1', '年龄', '年龄1'] # 数据库中的字段 i = 0 for name in names: if name in columns: # 判断数据库中的字段是否全部存在,防止将一整个字段填入NULL值 pass else: i += 1 if i == 0: df = df.reindex(columns=names) trs = [] for td in df.iloc[:].values: trs.append(f"{tuple(td)}") return trs else: print('字段不相符') def insert_mysql(path, path_file_judge): mysql.reConnect() mysql.delect_sql('delete from teble.ceshi') print('删除完成') lists = os.listdir(path) for file in lists: # 为了循环插入 path_file = path + '\' + file if path_file == path_file_judge: print(path_file) sql_insert = 'insert into qsl.user_evaluation(`姓名`, `姓名1`, `ID`, `ID1`, `年龄`, `年龄1`)' values = read_excel(path_file) sql_insert = sql_insert + ' values ' + ','.join(values) sql_insert = sql_insert.replace("'Null'", "Null") # read_excel中插入Null的原因 # print(sql_insert) mysql.insert_sql(sql_insert) print('插入完成') if __name__ == '__main__': path = r'Dceshi' everyday = datetime.datetime.now() - datetime.timedelta(days=1) everyday = everyday.strftime('%Y{Y}%m{m}%d{d}').format(Y='-', m='-', d='') path_file_judge = path + '\' + '测试_{everyday}.xlsx'.format(everyday=everyday) insert_mysql(path, path_file_judge)
这段代码的前提是excel的字段永不变化并且和数据库能保持一致。