
import re
str1 = 'imooc python'
# str1.find('l1') 输出: -1
# str1.find('imooc') 0
# str1.startswith('imooc') True
pa = re.compile(r'imooc') #加个r 代表是个原字符串
# pa = re.compile('imooc
')
会转译成一个换行符
# type: _sre.SRE_Pattern
pa.match(str1)
ma = pa.match(str1)
# ma.span() (0, 5)
# ma.group() 'imooc'
# ma.string 'imooc python'
# ma.re re.compile(r'imooc', re.UNICODE)
pa1 = re.compile(r'_')
ma1 = pa1.match('_value')
# ma1.group <function SRE_Match.group>
# pa re.compile(r'imooc', re.UNICODE)
ma = pa.match('imooc python')
# ma.group() 'imooc'
# pa = pa.match('imoOc python', re.I)
# type(pa) NoneType
pa = re.compile(r'(imooc)', re.I) #组 大写的i
ma = pa.match(str1)
# ma.group() 'imooc'
# ma.groups() ('imooc',)
# ma = re.match(r'imooc', str1)
# ma <_sre.SRE_Match object; span=(0, 5), match='imooc'>
# ma.group() 'imooc'
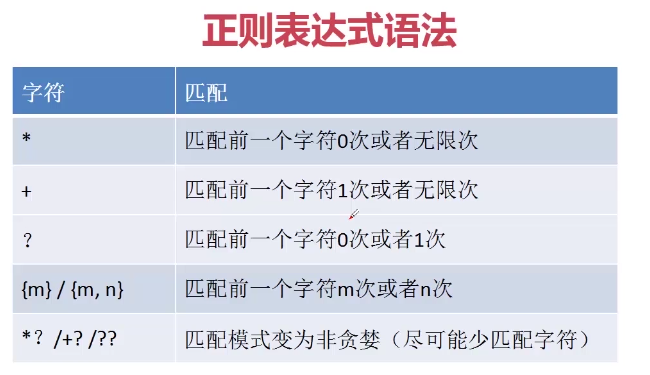
语法
# . 匹配任意字符 除了
# ma = re.match(r'a', 'a')
# ma.group() 'a'
# ma = re.match(r'.', 'b')
# ma.group() 'b'
# ma = re.match(r'.', '0')
# ma.group() '0'
# ma = re.match(r'{.}', '{a}')
# ma.group() '{a}'
# ma = re.match(r'{..}', '{a0}')
# ma.group() '{a0}'
# [...] 匹配字符集
# ma = re.match(r'{[abc]}', '{a}')
# ma.group() '{a}'
# ma = re.match(r'{[abc]}', '{d}')
# ma.group() AttributeError: 'NoneType' object has no attribute 'group'
# ma = re.match(r'{[a-z]}', '{d}')
# ma.group() '{d}'
# ma = re.match(r'{[a-zA-Z]}', '{D}')
# ma.group() '{D}'
# ma = re.match(r'{[a-zA-Z0-9]}', '{9}')
# ma.group() '{9}'
# ma = re.match(r'{[w]}', '{0}')
# ma.group() '{0}'
# ma = re.match(r'{[w]}', '{ }')
# ma.group() AttributeError: 'NoneType' object has no attribute 'group'
# ma = re.match(r'{[W]}', '{ }')
# ma.group() '{ }'
# ma = re.match(r'{[[w]]}', '[0]')
# ma.group() AttributeError:
# ma = re.match(r'[[w]]', '[0]') 要加转译字符
# ma.group() '[0]'
import re
# ma = re.match(r'[A-Z][a-z]', 'Aa')
# ma.group() 'Aa'
# ma = re.match(r'[A-Z][a-z]*', 'A')
# ma.group() 'A'
# ma = re.match(r'[A-Z][a-z]*', 'AdsfafeadcxAe') 如果出现数字是匹配不上的
# ma.group() 'Adsfafeadcx'
# _ = 10
# _ 10
# ma = re.match(r'[0-9]?[0-9]', '90')
# ma.group() '90'
# ma = re.match(r'[0-9]?[0-9]', '9')
# ma.group() '9'
# ma = re.match(r'[0-9]?[0-9]', '09')
# ma.group() '09'
# ma = re.match(r'[a-zA-Z0-9]{6}', 'abc123')
# ma.group() 'abc123'
# ma = re.match(r'[a-zA-Z0-9]', 'abc123')
# ma.group() 'a'
# ma = re.match(r'[a-zA-Z0-9]{6}', 'abc123__')
# ma.group() 'abc123'
# ma = re.match(r'[a-zA-Z0-9]{6}@163.com', 'abc123@163.com')
# ma.group() 'abc123@163.com'
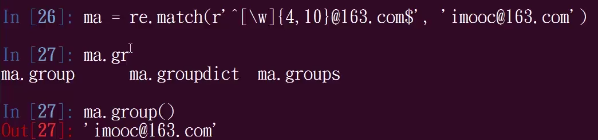
# ma = re.match(r'[a-zA-Z0-9]{6, 10}@163.com', 'imoocedu@163.com')
# ma.group() AttributeError: 'NoneType' object has no attribute 'group'
# ma = re.match(r'[0-9][a-z]*?', '1bc')
# ma.group() '1'
# ma = re.match(r'[a-zA-Z0-9]+?', '1bc')
# ma.group() '1'

# ma = re.match(r'Aimooc[w]', 'imoocpython') 边界匹配
# ma.group() 'imoocp'

# ma = re.match(r'abc|d', 'abc')
# ma.group() 'abc'
# ma = re.match(r'[1-9]?d$', '9')
# ma.group() '9'
# ma = re.match(r'[1-9]?d|100$', '100')
# ma.group() '10'
# ma = re.match(r'[1-9]?d|100$', '99')
# ma.group() '99'
# ma = re.match(r'[1-9]?d|100$', '9')
# ma.group() '9'
# ma = re.match(r'[w]{4, 6}@(163|126).com', 'imooc@163.com')
# ma.group() AttributeError: 'NoneType' object has no attribute 'group'
# ma = re.match(r'[w]{4, 6}@(163|126).com', 'imooc@126.com')
# ma.group() AttributeError: 'NoneType' object has no attribute 'group'
# ma = re.match(r'<[w]+>', '<book>')
# ma.group() '<book>'
# ma = re.match(r'<([w]+>)', '<book>')
# ma.group() '<book>'
# ma = re.match(r'<([w]+>)1', '<book>')
# ma.group() AttributeError: 'NoneType' object has no attribute 'group'
# ma = re.match(r'<([w]+>)1', '<book>book>')
# ma.group() '<book>book>'
# ma = re.match(r'<([w]>)[w]+</1', '<book>python</book>')
# ma.group() AttributeError: 'NoneType' object has no attribute 'group'
# ma = re.match(r'<(?P<mark>[w]>)[w]+</(?P=mark)', '<book>python</book>')
# ma.group() AttributeError: 'NoneType' object has no attribute 'group'



import re
str1 = 'imooc videonum = 100'
# str1.find('100') # 17
info = re.search(r'd+', str1)
# info # <_sre.SRE_Match object; span=(17, 20), match='100'>
str1 = 'imooc videonum = 10000'
# info.group() # '100'
str2 = 'c++=100, java=90, python=80'
info = re.findall(r'd+', str2)
# info ['100', '90', '80']
# sum([int(x) for x in info]) 270
str3 = 'imooc videonum = 10000'
info = re.sub(r'd+', '1001', str3)
# info 'imooc videonum = 1001'
def add1(match):
val = match.group()
num = int(val) + 1
return str(num)
# re.sub(r'd+', add1, str3) 'imooc videonum = 10001'
str4 = 'imooc:c c++ java python'
#不能仅仅使用空格分割
re.split(r':| ', str4) #['imooc', 'c', 'c++', 'java', 'python']
# str4 = 'imooc:c c++ java python,c#'
# re.split(r':| |,', str4) ['imooc', 'c', 'c++', 'java', 'python', 'c#']