map 的基本构成
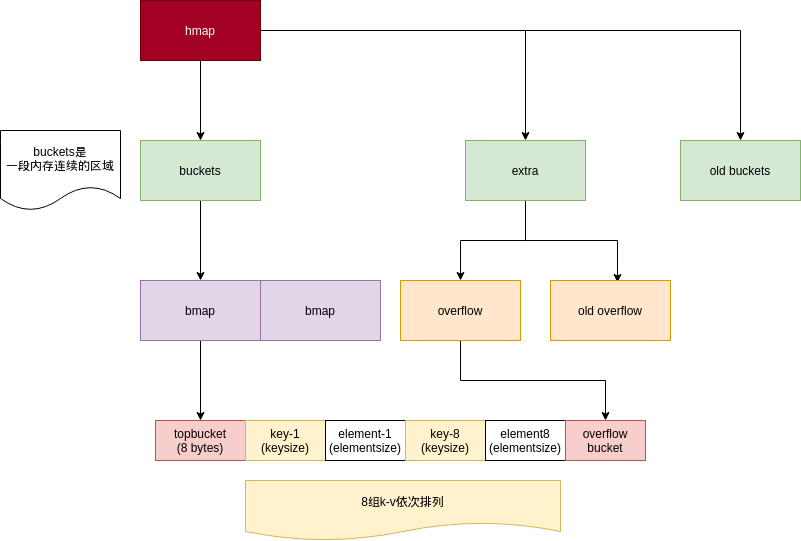
map的实现文件为 src/runtime/map.go. 它的基本结构是一个HashMap,实现方式为哈希桶, 根据key将数据散列到不同的桶中,每个桶中有固定的8个键值对.
桶尾部可以挂载额外的桶(overflow buckets).
由结构可知, Go map的访问复杂度为O(1), 假设哈希函数恶化, 所有key都映射到同一个bucket, map可以退化为单链表.
内存结构
为了内存能够连续分配,以及访问高效, Go将hashmap中的桶及键值对摊平作为连续内存结构存储.
初始化及空间复杂度
在func makemap(make map的原型)中, 我们可以看到以下代码.
假设我们现在有n个元素需要存储, 那么:
- 如果这个数量不超过8个, 那么一个桶就可以放得下
- 如果数量超过了8个, 那么hashmap允许承受的最大负载因子(loadFactor)为6.5,即:
找到一个B, 使得:
$$2^{B}cdotfrac{13}{2}>n$$
// Find the size parameter B which will hold the requested # of elements.
// For hint < 0 overLoadFactor returns false since hint < bucketCnt.
B := uint8(0)
for overLoadFactor(hint, B) {
B++
}
h.B = B
读取一个key
Go map 根据key获得值有几种方法:
- a := m[key], 其实现原型为 mapaccess1(),返回一个值
- a, ok := m[key], 返回两个值, 其实现原型为 mapaccess2()
如果使用map存储指针, 指针与map存在强关联,会对GC产生影响. mapaccess1() 中有一段注释, 说的就是此类情形.假设我们从一个map中取出了一个指针, 那么map要一直等到指针不再被使用后才有可能被回收.
// NOTE: The returned pointer may keep the whole map live, so don't
// hold onto it for very long.
func mapaccess1(t *maptype, h *hmap, key unsafe.Pointer) unsafe.Pointer
if h == nil || h.count == 0 {
if t.hashMightPanic() {
t.key.alg.hash(key, 0) // see issue 23734
}
return unsafe.Pointer(&zeroVal[0])
}
在mapaccess1这一段,描述了从一个空的或nil的map中取值, 会返回空值. 那么为什么不直接返回0值, 要去尝试调用key的hash呢?
查看 issue 23734, 会发现以前的代码还真就没有这一段. 之所以这样做, 是因为当从一个非空的map中取值时, 如果key为nil, 那么会导致一个panic, 但同样的操作在nil/空 map上就不会发生, 这可能会导致难以发现的bug, 所以就加上了 O_O.
下面这一段, 意味着不同的goroutine同时进行写操作和读操作, 会导致panic.
if h.flags&hashWriting != 0 {
throw("concurrent map read and map write")
}
Go map的写入非常复杂, 当多个goroutine同时对一个map进行读写操作, 可能会造成不可预知的效果.
这里主要两种解决方案, 即通过sync.Mutex对map加锁, 以及使用sync.Map.
那么如果是在一个单核处理器上, 这样是不是就可以避免panic了呢? 这也是不行的. 观察发现对 h.flags 修改和读操作都不是原子操作, 因此即使是单核处理器, 也仍可能会出现 goroutine 在写入过程中挂起, 另一个 goroutine 进行读取的情形.
遍历
for k, v := range m {
// ...
}
以上代码中, 通过range对map进行遍历的实现原型为 mapiterinit() 及 mapiternext()
开始遍历时,会随机选取一个bucket开始遍历.
因此,当map包含多个bucket时,每次遍历的顺序都是不一样的.
// decide where to start
r := uintptr(fastrand())
if h.B > 31-bucketCntBits {
r += uintptr(fastrand()) << 31
}
it.startBucket = r & bucketMask(h.B)
it.offset = uint8(r >> h.B & (bucketCnt - 1))
// iterator state
it.bucket = it.startBucket
理论上讲, Go的bucket是可以确保这个顺序一致的,但是Go的底层实现无法保证在不同平台保持一致(在不同的CPU架构及操作系统下),也无法保证不同版本的一致.
在察觉某些开发者尝试依赖这个一致性顺序后, Go决定在实现层面加入随机因素,使得开发者彻底不能够利用这个特性, 以避免隐形bug产生. 这种操作是不是很眼熟? 为了防止大家写出bug, 我们强行使其变得随机了.
不过除了以上考虑外,在以下情形:
for k, v := range m {
if v == N {
break
}
}
假设根据某个遍历顺序,符合条件的v在遍历末尾, 随机遍历顺序能够防止这种劣化情况持续发生.
桶溢出
m[a] = v1
m[b] = v2
在 mapassign() 中, 会完成已存在键则覆盖,未存在键则插入的过程.
在进行插入操作时, 可能会发生两种情况: 桶溢出(bucket overflow) 和 扩容(grow)
已知Go map每个桶最多存放8个键值对, 那么如果插入一个bucket时, 发现它已经满了, 该怎么办呢?
之前在内存布局图中可以看到,每个bucket末端都有一个指针空间,这个指针用于指向下一个溢出bucket.溢出bucket与buckets/oldbuckets中的bucket不同,它是游离在堆中的,理论上可以无限扩充.
hmap会纪录这些溢出桶.如果一个桶下挂的溢出桶过多,指向它的查询性能将会急剧恶化,因此将会触发扩容.
if inserti == nil {
// all current buckets are full, allocate a new one.
newb := h.newoverflow(t, b)
inserti = &newb.tophash[0]
insertk = add(unsafe.Pointer(newb), dataOffset)
elem = add(insertk, bucketCnt*uintptr(t.keysize))
}
扩容与转移
当我们尝试插入一个值时,可能待插入的桶需要溢出才能满足需求,同时,map中增加了一个值,负载因子变高了.
当hash恶化,溢出桶过多,或负载因子超过阈值(6.5)时,Go map将会进行扩容.
// If we hit the max load factor or we have too many overflow buckets,
// and we're not already in the middle of growing, start growing.
if !h.growing() && (overLoadFactor(h.count+1, h.B) || tooManyOverflowBuckets(h.noverflow, h.B)) {
hashGrow(t, h)
goto again // Growing the table invalidates everything, so try again
}
-
如果是负载因子过高需要扩容,那么新的buckets会新扩张为原来的两倍.
-
如果是溢出桶过多,则会保持会新建一组同样大小的buckets,查询会在oldbuckets/buckets中进行
扩容后,hash可能需要重建,桶内数据移动发生在 growWork()中,它调用了evacuate(),对数据进行移动及指针清理
func hashGrow(t *maptype, h *hmap) {
// If we've hit the load factor, get bigger.
// Otherwise, there are too many overflow buckets,
// so keep the same number of buckets and "grow" laterally.
bigger := uint8(1)
if !overLoadFactor(h.count+1, h.B) {
bigger = 0
h.flags |= sameSizeGrow
}
oldbuckets := h.buckets
newbuckets, nextOverflow := makeBucketArray(t, h.B+bigger, nil)
删除与清除
delete(m, k)的原型是mapdelete(),该操作不会影响原有的buckets布局,也不会导致hash散列重分布
在一个map已经很大的情况下,删除一部分键值并不会导致map本身占用的内存回收.
但由于map中存放的指针本身也存在强关联,存续会导致GC无法回收Object,因此能够让这些指针指向的内存空间得到释放
mapclear()能够真正的释放map占有空间,但map所有键值也会被清除.
我们没有办法直接调用mapclear(也没有意义),它由GC通过mapClear调用.在确认需要回收一个map时对其使用.
内存优化
map对于Go的内存产生了双重压力: map自身占用内存的压力,以及对GC的压力.
GC优化
当map中的键值对包含指针时,map会与它们形成关联,GC需要扫描其中所有指针.
如果map中不包含指针,那么GC将不会对map内的buckets进行扫描.
启示:尽量避免 key/value 为指针的map,如果一定需要,从中取出值后尽量不要逃逸出map的视线.
编译优化
在使用过程中,map是“只增不减”的,堆内存需要GC.对于小型的简单map,在编译期间通过逃逸分析,可以直接被分配到栈上.