前两章简单的讲了Beautiful Soup的用法,在爬虫的过程中相信都遇到过一些反爬虫,如何跳过这些反爬虫呢?今天通过知乎网写一个简单的反爬中
什么是反爬虫
简单的说就是使用任何技术手段,阻止别人批量获取自己网站信息的一种方式。关键也在于批量。
反反爬虫机制
- 增加请求头---headers为了模拟更真实的用户场景
- 更改IP地址---网站会根据你的IP对网站访问频密,判断你是否属于爬虫
- ua限制---UA是用户访问网站时候的浏览器标识,其反爬机制与ip限制类似
- 模拟帐号登录----通过request模拟登录进行访问网站
- cookies的限制---网站页面每次请求的cookies不同
爬取知乎热榜
1.首先打开需要爬取的网站
2.分析网站的html,标签为’a‘,属性为target="_blank"
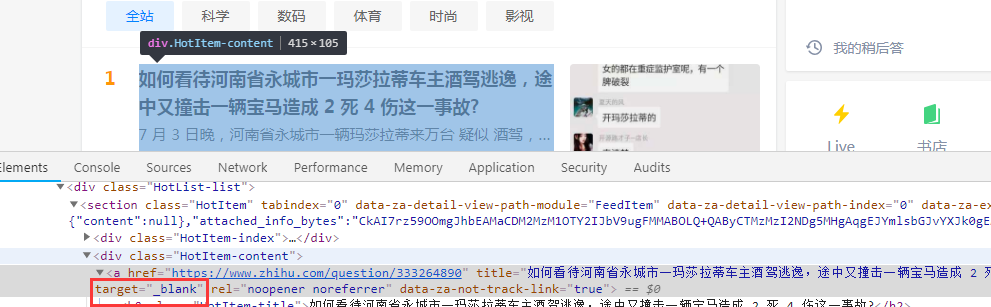
3.通过request方式进行请求网站
4.首先我们先不携带任何的反反爬虫机制进行访问
# coding:utf-8 import requests from bs4 import BeautifulSoup url = 'https://www.zhihu.com/hot' html = requests.get(url,verify = False).content.decode('utf-8') # verify = False表示请求https soup = BeautifulSoup(html,'html.parser') name = soup.find_all('a',target="_blank") for i in name: print(i)
结果发现请求为空
5.从F12中提取出完整的请求头(也可以通过fiddler进行查看)
- 请求地址的host
- 请求的cookies
- 请求的User-Agent
# coding:utf-8 import requests from bs4 import BeautifulSoup url = 'https://www.zhihu.com/hot' # 添加请求头 headers={ "host":"www.zhihu.com", "cookie":'_zap=482b5934-4878-4c78-84f9-893682c32b07; d_c0="ALCgSJhlsQ6PTpmYqrf51G' 'HhiwoTIQIlS1w=|1545203069"; _xsrf=XrStkKiqUlLxzwMIqRDc01J7jikO4xby; q_c1=94622' '462a93a4238aafabad8c004bc41|1552532103000|1548396224000; __utma=51854390.1197068257.' '1552532107.1552532107.1552532107.1; __utmz=51854390.1552532107.1.1.utmcsr=zhihu.com|utmccn=(r' 'eferral)|utmcmd=referral|utmcct=/; __utmv=51854390.100--|2=registration_date=20190314=1^3=entry_da' 'te=20190125=1; z_c0="2|1:0|10:1552535646|4:z_c0|92:Mi4xcFRlN0RnQUFBQUFBc0tCSW1HV3hEaVlBQUFCZ0FsVk5Ya' 'DUzWFFBWExTLXVpM3llZzhMb29QSmRtcjlKR3pRaTBB|03a1fa3d16c98e1688cdb5f6ba36082585d72af2f54597e370f05207' 'cd3a873f"; __gads=ID=27a40a1873146c19:T=1555320108:S=ALNI_MYb5D7sBKFhvJj32HBQXgrhyC6xxQ; tgw_l7_route=7' '3af20938a97f63d9b695ad561c4c10c; tst=h; tshl=', "User-Agent":"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3497.81 Safari/537.36", } html = requests.get(url,headers=headers,verify = False).content.decode('utf-8') # verify = False表示请求https soup = BeautifulSoup(html,'html.parser') name = soup.find_all('a',target="_blank") for i in name: print(i.get_text())
执行后发现成功的把热榜下的一些信息请求出来

喜欢的小伙伴可以自己手动试一试。