1. yarn白话介绍
hadoop yarn是一种新的hadoop资源管理器,它是一个通用的资源管理系统和调度平台,可为上层应用提供统一的资源管理和调度。
可以吧yarn理解为一个分布式操作系统平台,而mapreduce等运算程序相当于运行于操作系统之上的应用程序,yarn为这些程序提供运算所需要的资源(内存和cpu)。
- yarn并不知道用户提交程序的运行机制
- yarn只提供运算资源的调度
- yarn中的主管角色叫ResourceManager
- yarn中具体提供运算资源的角色是NodeManager
- yarn与用户提交的程序完全解耦,意味着yarn上面可以运行各种各样的运算程序。
- spark和storm都可以运行在yarn上,只需要它们符合yarn规范的资源请求
2. yarn架构
yarn是一个资源管理,任务调度的框架,主要包含三大模块:ResourceManager(RM),NodeManager(NM),ApplicationMaster(AM)。
- ResourceManager负责所有资源的分配,管理,监控。
- Nodemanager负责每一个节点的维护
- ApplicationMaster负责每一个具体应用程序的调度和协调
3. yarn运行流程
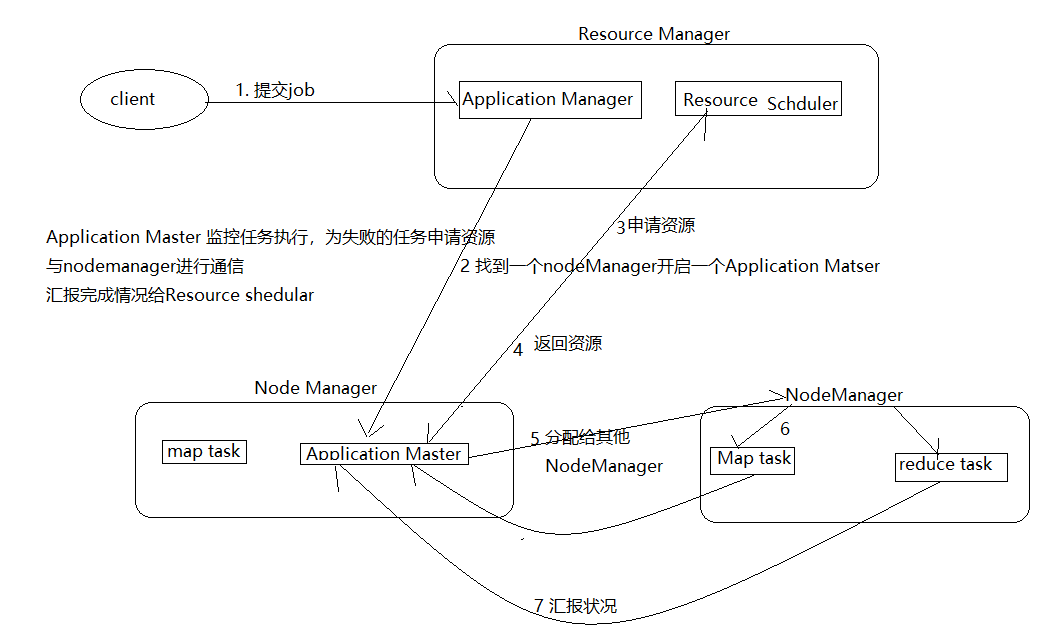
- client向yarn提交job,首先找ResourceManager分配资源
- ResourceManager开启一个container,在container中运行一个Application Manager
- Application Manager找一台Nodemanager启动application Master,计算任务所需。
- Application Master向Application Manager申请任务所需资源
- Resource Scheduler将资源封装(描述信息)给Application Master
- Applocation Manager获取到的资源分发给各个Node Manager
- 各个nodemanager开始执行map task
- map task结束后开始执行 reduce task
- map task和reduce task将执行结果反馈给Application Master
- Application Master 将结果反馈给Application Manager
4. yarn调度器 Scheduler
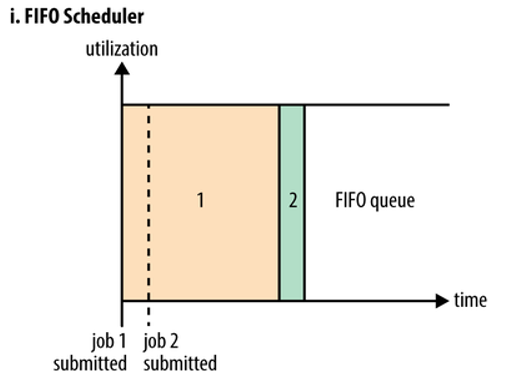
a. FIFO Scheduler
按照任务提交的顺序,将任务排成一个队列,当第一个任务执行完成,再执行第二个任务,先进入队列的任务先执行。
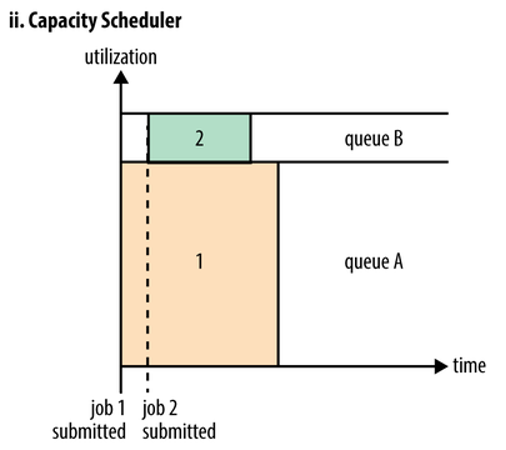
b. Capacity Scheduler
Capacity调度器允许多个组织共享集群资源,将每个组织分配专门的队列,每个队列分配一定的资源,这样就可以通过设置多个队列的方式为多个组织提供服务。在一个队列内,资源的调度还是FIFO Scheduler。
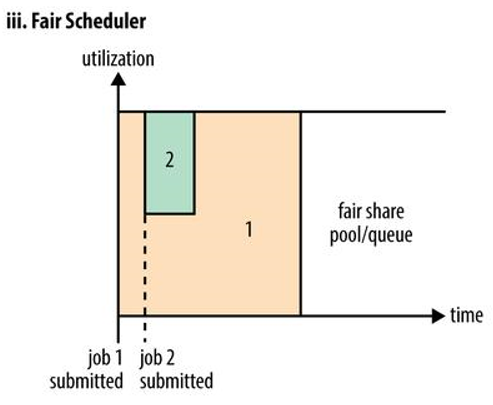
c. Fair Schedular
Fair 调度器会自动为所有运行的job动态的调整系统资源,比如当有一个大的job提交时,只有这个job在运行,此时所有系统资源都被他利用。当有另外一个小job提交时,Fair调度器也会为分配资源给这个job(注意这里会有一个延时,因为他需要等第一个任务释放占用的Container,小任务执行也会释放自己的Container)。
5. HA
HA(High Available),高可用,是保证业务连续性的有效方案。在hadoop1.x中,NameNode是集群的单点故障点,每个集群只有一个NameNode,如果这个这个机器或者这个进程挂掉,name整个集群就无法使用了,为了解决这个问题,出现了一堆针对了HDFS HA的解决方案。
Active NN和Standby NN之间要有个共享存储日志的地方,Active NN把edit log写到这个共享存储日志的地方,Standby NN去读取日志,然后执行这些操作,这样Active NN和Standby NN内存中的HDFS元数据保持着同步,一旦发生切换standby NN可以尽快接管Active NN的工作。
这时会有一个journal集群负责管理元数据的一致性,应该有2N+1个,当N+1台拥有元数据时,才认为元数据有效,还有一个守护进程zkfc负责监控namenode的状态,这个进程相当于zookeeper的一个客户端,当这个状态发上改变,这个客户端就断开连接,zookeeper上面的临时节点就消失,此时利用到了分布式锁知识,这时备用节点得到了锁,备用standby节点的守护进程将状态更改为active。
为保证只有一个NN向datanode发送命令,每个NN状态改变时会向datanode发送自己的状态和一个序列号,atanode负责维护此序列号。在failover时,新的NN在返回datanode心跳时会把自己的状态和更大的一个序列号发给datanode,datanode接收到则认为这个NN是active。当原来的NN重启或者复活后,还向datanode发送状态和原来的序列号的时候,这时候datanode就会拒绝命令。
6. 联邦机制
- 多个NN共用一个集群里面的存储资源,每个NN都可以单独对外面提供服务。
- 每个NN都会定义一个存储池,有单独的id,每个DN都会为所有的存储池提供服务。
- DN会按照id向NN汇报Block块信息,同时DN会向所有NN汇报自己本地存储可用资源情况
7. 其他见
第三阶段-day11( Failover Controller )
第三阶段-day11(Yarn HA)
