1. 流量分析
a.
- 统计 PageView 浏览次数(pv)


select count(*) from ods_weblog_detail where datestr ="20181101" and valid = "true"; 排除静态资源
- 统计Unique Visitor 独立访客(UV)
select count(distinct remote_addr) as uvs from ods_weblog_detail where datestr ="20181101";
- 统计访问次数(VV)
select count(distinct session) as vvs from ods_click_stream_visit where datestr ="20181101";
- ip
select count(distinct remote_addr) as ips from ods_weblog_detail where datestr ="20181101";
- 结果表
create table dw_webflow_basic_info(month string,day string, pv bigint,uv bigint ,ip bigint, vv bigint) partitioned by(datestr string); insert into table dw_webflow_basic_info partition(datestr="20181101") select '201811','01',a.*,b.* from (select count(*) as pv,count(distinct remote_addr) as uv,count(distinct remote_addr) as ips from ods_weblog_detail where datestr ='20181101') a join (select count(distinct session) as vvs from ods_click_stream_visit where datestr ="20181101") b;
- 多维度分析--按照时间
方式一:直接在ods_weblog_detail单表上进行查询 --计算该处理批次(一天)中的各小时pvs drop table dw_pvs_everyhour_oneday; create table dw_pvs_everyhour_oneday(month string,day string,hour string,pvs bigint) partitioned by(datestr string); insert into table dw_pvs_everyhour_oneday partition(datestr='20130918') select a.month as month,a.day as day,a.hour as hour,count(*) as pvs from ods_weblog_detail a where a.datestr='20130918' group by a.month,a.day,a.hour; --计算每天的pvs drop table dw_pvs_everyday; create table dw_pvs_everyday(pvs bigint,month string,day string); insert into table dw_pvs_everyday select count(*) as pvs,a.month as month,a.day as day from ods_weblog_detail a group by a.month,a.day; 方式二:与时间维表关联查询 --维度:日 drop table dw_pvs_everyday; create table dw_pvs_everyday(pvs bigint,month string,day string); insert into table dw_pvs_everyday select count(*) as pvs,a.month as month,a.day as day from (select distinct month, day from t_dim_time) a join ods_weblog_detail b on a.month=b.month and a.day=b.day group by a.month,a.day; --维度:月 drop table dw_pvs_everymonth; create table dw_pvs_everymonth (pvs bigint,month string); insert into table dw_pvs_everymonth select count(*) as pvs,a.month from (select distinct month from t_dim_time) a join ods_weblog_detail b on a.month=b.month group by a.month; --另外,也可以直接利用之前的计算结果。比如从之前算好的小时结果中统计每一天的 Insert into table dw_pvs_everyday Select sum(pvs) as pvs,month,day from dw_pvs_everyhour_oneday group by month,day having day='18';
- 按照referer、时间维度
--统计每小时各来访url产生的pv量 drop table dw_pvs_referer_everyhour; create table dw_pvs_referer_everyhour(referer_url string,referer_host string,month string,day string,hour string,pv_referer_cnt bigint) partitioned by(datestr string); insert into table dw_pvs_referer_everyhour partition(datestr='20181101') select http_referer,ref_host,month,day,hour,count(*) as pv_referer_cnt from dw_weblog_detail group by http_referer,ref_host,month,day,hour having ref_host is not null order by hour asc,day asc,month asc,pv_referer_cnt desc; --统计每小时各来访host的产生的pv数并排序 drop table dw_pvs_refererhost_everyhour; create table dw_pvs_refererhost_everyhour(ref_host string,month string,day string,hour string,ref_host_cnts bigint) partitioned by(datestr string); insert into table dw_pvs_refererhost_everyhour partition(datestr='20181101') select ref_host,month,day,hour,count(*) as ref_host_cnts from ods_weblog_detail group by ref_host,month,day,hour having ref_host is not null order by hour asc,day asc,month asc,ref_host_cnts desc;
b. 复合指标分析
- 人均浏览网页数(平均访问深度)
drop table dw_avgpv_user_everyday; create table dw_avgpv_user_everyday( day string, avgpv string); insert into table dw_avgpv_user_everyday select '20130918',sum(b.pvs)/count(b.remote_addr) from (select remote_addr,count(1) as pvs from ods_weblog_detail where datestr='20130918' group by remote_addr) b; 今日所有来访者平均请求浏览的页面数。该指标可以说明网站对用户的粘性。 计算方式:总页面请求数pv/独立访客数uv remote_addr表示不同的用户。可以先统计出不同remote_addr的pv量然后累加(sum)所有pv作为总的页面请求数,再count所有remote_addr作为总的去重总人数。
- 平均访问平度
select '20181101',vv/uv from dw_webflow_basic_info; --注意vv的计算采用的是点击流模型表数据 已经去除无效数据 select count(session)/ count(distinct remote_addr) from ods_click_stream_visit where datestr ="20181101"; --符合逻辑 平均每个独立访客一天内访问网站的次数(产生的session个数)。 计算方式:访问次数vv/独立访客数uv
c.分组Top的问题
- 统计每小时各来访host的产生的pvs数最多的前三个
--表:dw_weblog_detail --分组的字段:时间 --度量值:count select month,day,hour,ref_host,count(1) pvs from dw_weblog_detail group by month,day,hour,ref_host; select hour,ref_host,pvs,rank from (select concat(month,day,hour) hour ,ref_host,pvs, row_number() over(partition by concat(month,day,hour) order by pvs desc ) rank from (select month,day,hour,ref_host,count(1) pvs from dw_weblog_detail group by month,day,hour, ref_host) t) t1 where t1.rank<=3;
2.受访分析
a. 各个页面的pv(uv,vv等)
- 统计各个页面的pv
表:dw_weblog_detail 分组字段:request 度量值:count select request,count(1) request_count from dw_weblog_detail where valid='true' group by request having request is not null order by request_count desc limit 20;
b. 热门网页统计
- 统计每日最热门的页面top10
表:dw_weblog_detail 分组:request 度量值:count select '20130928',request,count(1) request_count from dw_weblog_detail where valid='true' group by request order by request_count desc limit 10;
3.访客分析
a. 独立访客
- 按照时间维度(比如小时)来统计独立访客及其产生的pv --独立访客分析
表:dw_weblog_detail 分组:hour 度量值:count select hour,remote_addr,count(1) pvs from dw_weblog_detail group by hour,remote_addr;
b. 每日新访客
- 将每天的新访客统计出来。
只要遇到新旧等二元问题,创建历史表和新的表,两个表进行join操作,最好是左外或者右外,我们用新访客左外的话,如果右表数据是null的话就证明是新的访客。 创建新表和历史表 --历日去重访客累积表 drop table dw_user_dsct_history; create table dw_user_dsct_history( day string, ip string ) partitioned by(datestr string); --每日新访客表 drop table dw_user_new_d; create table dw_user_new_d ( day string, ip string ) partitioned by(datestr string); --查询当天新的数据 select remote_addr from dw_weblog_detail group by remote_addr --和历史数据join select count(t1.remote_addr) from (select remote_addr from dw_weblog_detail where datestr="20181101" group by remote_addr) t1 left join dw_user_dsct_history t2 on t1.remote_addr=t2.ip where t2.ip is null; --将新的数据插入的新表中 insert into table dw_user_new_d partition(datestr="20181101") select t1.day, t1.remote_addr from (select concat(month,day) day,remote_addr from dw_weblog_detail where datestr="20181101" group by concat(month,day), remote_addr) t1 left join dw_user_dsct_history t2 on t1.remote_addr=t2.ip; --将新访客放置到历史访客表中 insert into table dw_user_dsct_history partition(datestr="20181101") select day,ip from dw_user_new_d where datestr="20181101";
c. 地域分析
目前,国内用的比较有名的是“纯真IP数据库”,国外常用的是 maxmind、ip2location。IP数据库是否收费:收费、免费都有。一般有人维护的数据往往都是收费的,准确率和覆盖率会稍微高一些。
查询形式:
本地: 将IP数据库下载到本地使用,查询效率高、性能好。常用在统计分析方面。具体形式又分为:
内存查询:将全部数据直接加载到内存中,便于高性能查询。或者二进制的数据文件本身就是经过优化的索引文件,可以直接对文件做查询。
数据库查询:将数据导入到数据库,再用数据库查询。效率没有内存查询快。
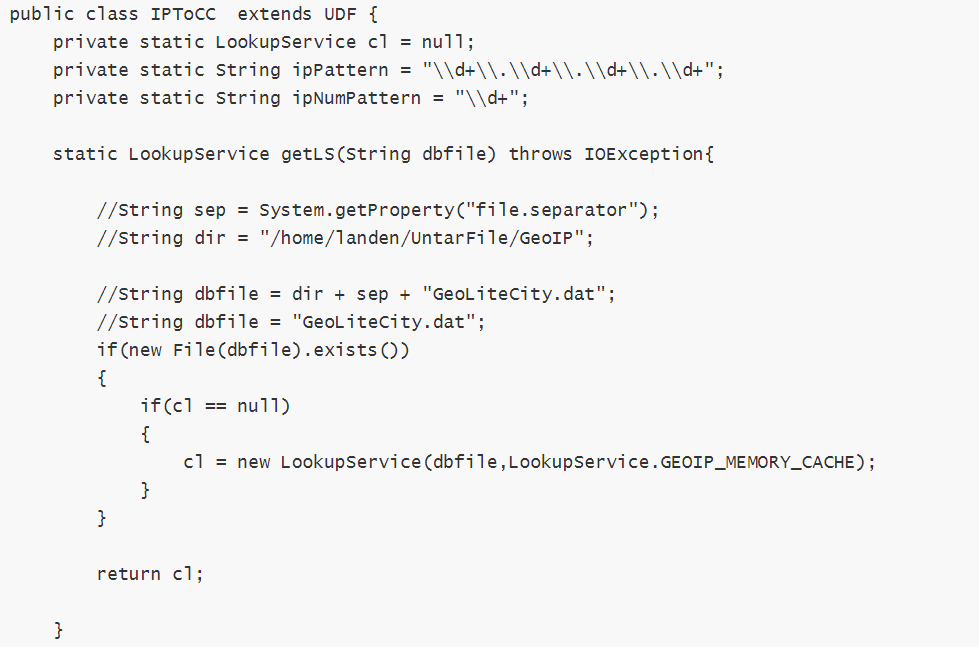
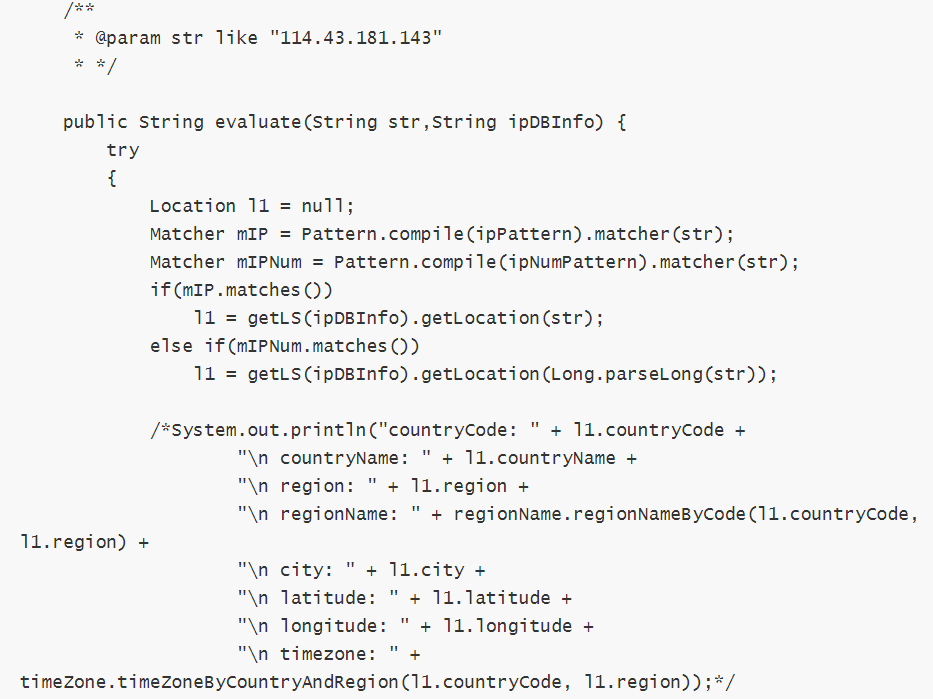

4. 访客visit分析
a. 回头/单次访客分析
表:ods_click_stream_visit 度量值:count 分组:remote_addr select t1.day,t1.remote_addr,t1.count from (select '20181101' as day,remote_addr,count(session) count from ods_click_stream_visit group by remote_addr) t1 where t1.count>1;
b. 人均访问频次
需求:统计出每天所有用户访问网站的平均次数(visit) 表:ods_click_stream_visit 度量值:count 分组:day select count(session)/count(distinct remote_addr) from ods_click_stream_visit where datestr='20181101';
5. 关键路径转换率
--规律:如果需要当前行和上一行进行计算 --我们就join自己表,根据需要找规律 首先创建总表 0) 规划一条用户行为轨迹线 Step1、 /item Step2、 /category Step3、 /index Step4、 /order 1) 计算在这条轨迹线当中, 每一步pv量是多少? 最终形成一张表 create table dw_oute_numbs as select 'step1' as step,count(distinct remote_addr) as numbs from ods_click_pageviews where datestr='20181103' and request like '/item%' union all select 'step2' as step,count(distinct remote_addr) as numbs from ods_click_pageviews where datestr='20181103' and request like '/category%' union all select 'step3' as step,count(distinct remote_addr) as numbs from ods_click_pageviews where datestr='20181103' and request like '/order%' union all select 'step4' as step,count(distinct remote_addr) as numbs from ods_click_pageviews where datestr='20181103' and request like '/index%'; 2) 求 每一步 和 第一步的转化率 select t2.pvs/t1.pvs from dw_oute_numbs t1 join dw_oute_numbs t2 where t1.step="step1"; 3) 求 每一步 和 上一步的转化率 select (t1.pvs /t2.pvs) *100 from dw_oute_numbs t1 join dw_oute_numbs t2 where cast(substring(t1.step,5,1) as int) -1 = cast(substring(t2.step,5,1) as int); 4) 合并在一起即可 select abs.step,abs.numbs,abs.rate as abs_ratio,rel.rate as leakage_rate from (select tmp.rnstep as step,tmp.rnnumbs as numbs,tmp.rnnumbs/tmp.rrnumbs as rate from (select rn.step as rnstep,rn.numbs as rnnumbs,rr.step as rrstep,rr.numbs as rrnumbs from dw_oute_numbs rn inner join dw_oute_numbs rr) tmp where tmp.rrstep='step1') abs left outer join (select tmp.rrstep as step,tmp.rrnumbs/tmp.rnnumbs as rate from (select rn.step as rnstep,rn.numbs as rnnumbs,rr.step as rrstep,rr.numbs as rrnumbs from dw_oute_numbs rn inner join dw_oute_numbs rr) tmp where cast(substr(tmp.rnstep,5,1) as int)=cast(substr(tmp.rrstep,5,1) as int)-1 ) rel on abs.step=rel.step;
6. 模块开发_数据导出
a. 从hive表到RDBMS表直接导出
效率较高,相当于直接在Hive表与RDBMS表的进行数据更新,但无法做精细的控制。
b. 从hive到HDFS再到RDBMS表的导出
需要先将数据从Hive表导出到HDFS,再从HDFS将数据导入到RDBMS。虽然比直接导出多了一步操作,但是可以实现对数据的更精准的操作,特别是在从Hive表导出到HDFS时,可以进一步对数据进行字段筛选、字段加工、数据过滤操作,从而使得HDFS上的数据更“接近”或等于将来实际要导入RDBMS表的数据,提高导出速度。
c. 全量导出数据到mysql
hive-->HDFS
导出dw_pvs_referer_everyhour表数据到HDFS
insert overwrite directory '/weblog/export/dw_pvs_referer_everyhour' row format delimited fields terminated by ',' STORED AS textfile select referer_url,hour,pv_referer_cnt from dw_pvs_referer_everyhour where datestr = "20181101";
d. 增量导出数据到mysql
- 使用技术: 使用sqoop export 中--update-mode 的allowinsert模式进行增量数据导入目标表中。该模式用于将Hive中有但目标表中无的记录同步到目标表中,但同时也会同步不一致的记录。
- 实现逻辑: 以dw_webflow_basic_info基础信息指标表为例进行增量导出操作
实现步骤: 1) mysql手动创建目标表 create table dw_webflow_basic_info( monthstr varchar(20), daystr varchar(10), pv bigint, uv bigint, ip bigint, vv bigint) 2) 先执行全量导入, 把当前的hive中20181101分区数据进行导出 bin/sqoop export --connect jdbc:mysql://node01:3306/weblog --username root --password 123456 --table dw_webflow_basic_info --fields-terminated-by '�01' --export-dir /user/hive/warehouse/itheima_weblog.db/dw_webflow_basic_info/datestr=20181101/ 3) 为了方便演示, 手动生成往hive中添加20181103的数据 insert into table dw_webflow_basic_info partition(datestr="20191006") values("201910","06",14250,1341,1341,96); 4) sqoop进行增量导出 bin/sqoop export --connect jdbc:mysql://node01:3306/weblog --username root --password 123456 --table dw_webflow_basic_info --fields-terminated-by '�01' --update-key monthstr,daystr --update-mode allowinsert --export-dir /user/hive/warehouse/itheima_weblog.db/dw_webflow_basic_info/datestr=20181103/
e. 定时增量导出数据
- 使用技术:使用sqoop expo rt 中--update-mode 的allowinsert模式进行增量数据导入目标表中。该模式用于将Hive中有但目标表中无的记录同步到目标表中,但同时也会同步不一致的记录
- 实现逻辑:以dw_webflow_basic_info基础信息指标表为例进行增量导出操作
#!/bin/bash export SQOOP_HOME=/export/servers/sqoop if [ $# -eq 1 ] then execute_date=`date --date="${1}" +%Y%m%d` else execute_date=`date -d'-1 day' +%Y%m%d` fi echo "execute_date:"${execute_date} table_name="dw_webflow_basic_info" hdfs_dir=/user/hive/warehouse/itheima.db/dw_webflow_basic_info/datestr=${execute_date} mysql_db_pwd=hadoop mysql_db_name=root echo 'sqoop start' $SQOOP_HOME/bin/sqoop export --connect "jdbc:mysql://node-1:3306/weblog" --username $mysql_db_name --password $mysql_db_pwd --table $table_name --fields-terminated-by '�01' --update-key monthstr,daystr --update-mode allowinsert --export-dir $hdfs_dir echo 'sqoop end'
7. 模块开发_工作流调度
数据预处理模块按照数据处理过程和业务需求,可以分成3个步骤执行:数据预处理清洗、点击流模型之pageviews、点击流模型之visit。并且3个步骤之间存在着明显的依赖关系,使用azkaban定时周期性执行将会非常方便.
- 对之前的预处理MapReduce进行打jar包(共三个)
#weblog_preprocess.job type=command command=/export/servers/hadoop-2.6.0-cdh5.14.0/bin/hadoop jar preprocess.jar /weblog/log /weblog/out # weblog_click_pageviews.job type=command dependencies=weblog_preprocess command=/export/servers/hadoop-2.6.0-cdh5.14.0/bin/hadoop jar weblog_click_pageviews.jar /weblog/out /weblog/pageviews # weblog_click_visit.job type=command dependencies=weblog_click_pageviews command=/export/servers/hadoop-2.6.0-cdh5.14.0/bin/hadoop jar weblog_click_visit.jar /weblog/pageviews /weblog/sisit
b. 数据库定时入库
#!/bin/bash export HIVE_HOME=/export/servers/hive if [ $# -eq 1 ] then datestr=`date --date="${1}" +%Y%m%d` else datestr=`date -d'-1 day' +%Y%m%d` fi HQL="load data inpath '/preprocess/' into table itheima.ods_weblog_origin partition(datestr='${datestr}')" echo "开始执行load......" $HIVE_HOME/bin/hive -e "$HQL" echo "执行完毕......" # load-weblog.job type=command command=sh load-weblog.sh
c. 数据统计计算定时
#!/bin/bash HQL=" drop table dw_user_dstc_ip_h; create table dw_user_dstc_ip_h( remote_addr string, pvs bigint, hour string); insert into table dw_user_dstc_ip_h select remote_addr,count(1) as pvs,concat(month,day,hour) as hour from ods_weblog_detail Where datestr='20181101' group by concat(month,day,hour),remote_addr; " echo $HQL /export/servers/hive/bin/hive -e "$HQL"