1. 消息队列的介绍
消息队列:一种应用间的通信方式,消息发送后立即返回。
我们可以把消息队列比作是一个存放消息的容器,当我们使用消息的时候可以取出消息供自己使用,消息队列是分布式系统中的重要组件,使用消息队列主要是为了异步处理提高系统性能和削峰,降低系统耦合性。
https://www.jianshu.com/p/36a7775b04ec
2. 常用的消息队列
RabbitMQ:开源的消息队列,基于AMQP。
ActiveMQ:Apache旗下的一款消息队列产品。消息处理速度快
RocketMQ:是阿里出品的开源消息队列
Kafk:最初是LinkedIn公司开发,后托管给Apache。
3. 消息队列的应用场景
应用耦合:将多个应用之间解耦合。如果各个模块之间不存在直接调用,那么在新增模块或者修改模块就对其他模块影响小。

异步处理:消息的异步处理
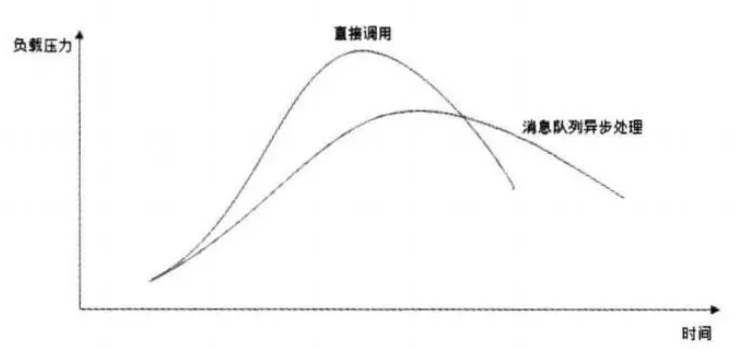
限流削峰:即通过异步处理,将短时间高并发产生的事务消息存储在消息队列中,从而削平高峰期的并发事务。对于峰值访问的数据,通过消息队列削峰。
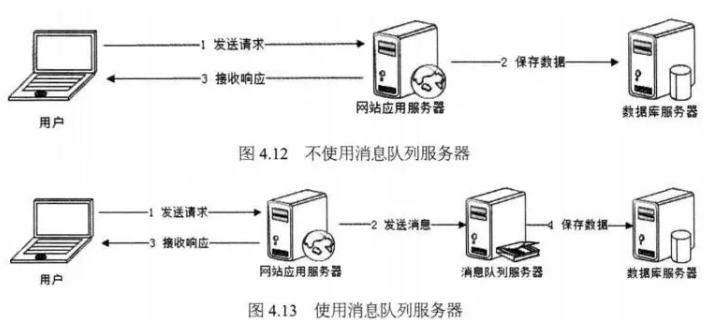
4.消息队列两种模式
点对点模式:一个生产者和一个消费者。一条消息只能被一个消费者接使用,未消费的消息存在队列直到被消费或者失效。

发布订阅模式:生产者和多个消费者,通过订阅主题消费。发布者发布一条消息,消息通过主题传递给所有的订阅用户。
5.kafka基本介绍
一个消息队列,是linkedin公司出品,适用于大数据的工作场景,使用scala语言编写的。
kafka是一个分布式,分区的,多副本的,多订阅者的日志系统,可用于搜索日志,监控日志,访问日志等。
流式处理:flume+kafka+spark streaming(flink)完成实时数据(流式处理)的处理
6. kafka的架构
生产者api:允许应用程序发布记录流至一个或者多个topic
消费者api:允许应用程序订阅一个或者多个主题,并处理这些主题接收到的记录流
7. kafka内部结构细节解析
8. kafka集群的使用命令


##集群的启动 nohup bin/kafka-server-start.sh config/server.properties 2>&1 & ##集群的关闭 bin/kafka-server-stop.sh ##创建主题 bin/kafka-topics.sh --create --zookeeper hadoop01:2181 --replication-factor 2 --partitions 3 --topic test ##查看主题 bin/kafka-topics.sh --list --zookeeper hadoop01:2181,hadoop02:2181,hadoop03:2181 ##生产数据 bin/kafka-console-producer.sh --broker-list hadoop01:9092,hadoop02:9092,hadoop03:9092 --topic test ##消费主题 bin/ kafka-console-consumer.sh --from-beginning --topic test --zookeeper hadoop01:2181,hadoop02:2181,hadoop03:2181 ##查看topic的信息 cd /export/servers/kafka_2.11-1.0.0 bin/kafka-topics.sh --describe --zookeeper hadoop01:2181 --topic test ##增加topic cd /export/servers/kafka_2.11-1.0.0 bin/kafka-topics.sh --zookeeper zkhost:port --alter --topic topicName --partitions 8 ##修改配置 bin/kafka-topics.sh --zookeeper hadoop01:2181 --alter --topic test --config flush.messages=1 ##删除配置 bin/kafka-topics.sh --zookeeper hadoop01:2181 --alter --topic test --delete-config flush.messages ##删除主题 kafka-topics.sh --zookeeper zkhost:port --delete --topic topicName
9. kafka当中的数据不丢失机制
A. 生产者的角度考虑
同步:发送一批数据给kafka后,等待kafka返回结果
- 生产者等待10秒,如果broker没有给ack响应,就认为失败
- 生产者会重试三次,如果三次后还没有响应就失败。
异步:发送一批数据给kfka,只提供一个回调函数。
- 先将数据保存在生产者端的buffer中。buffer大小是2万条
- 满足数据阈值或者数量阈值其中的一个条件就可以发送数据。
- 发送一批数据的大小是500条
ack确认机制:生产者发送数据,需要服务端返回一个确认码,即ack响应码
- 0:生产者只负责发送数据,不关心数据是否丢失,响应的状态码为0(丢失的数据,需要再次发送 )
- 1:partition的leader收到数据,响应的状态码为1
- -1:所有的从节点都收到数据,响应的状态码为-1
2. broker节点的角度考虑
通过副本的方式保证数据的不丢失
3. 从消费者的角度考虑
只要每个消费者记录好offset就好
10. kafka整合flume
#为我们的source channel sink起名 a1.sources = r1 a1.channels = c1 a1.sinks = k1 #指定我们的source收集到的数据发送到哪个管道 a1.sources.r1.channels = c1 #指定我们的source数据收集策略 a1.sources.r1.type = spooldir a1.sources.r1.spoolDir = /export/servers/flumedata a1.sources.r1.deletePolicy = never a1.sources.r1.fileSuffix = .COMPLETED a1.sources.r1.ignorePattern = ^(.)*\.tmp$ a1.sources.r1.inputCharset = GBK #指定我们的channel为memory,即表示所有的数据都装进memory当中 a1.channels.c1.type = memory #指定我们的sink为kafka sink,并指定我们的sink从哪个channel当中读取数据 a1.sinks.k1.channel = c1 a1.sinks.k1.type = org.apache.flume.sink.kafka.KafkaSink a1.sinks.k1.kafka.topic = test a1.sinks.k1.kafka.bootstrap.servers = hadoop01:9092,hadoop02:9092,hadoop03:9092 a1.sinks.k1.kafka.flumeBatchSize = 20 a1.sinks.k1.kafka.producer.acks = 1 ##启动flume bin/flume-ng agent --conf conf --conf-file conf/flume_kafka.conf --name a1 -Dflume.root.logger=INFO,console
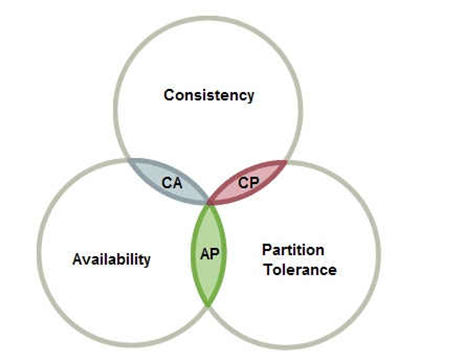
11. CAP理论及其在kafka中的应用
分布式系统最大的难点就是各个节点的状态如何同步。为了解决各个节点间的状态同步问题,1988年加州大学的计算机科学家提出了分布式系统的三个指标,分别是:
- Consistency:一致性
- Availabel:可用性
- Partition tolerance:分区容错性
A. 一致性
- 通过某个节点的写操作结果对后面通过其他节点的读操作可见
- 如果更新数据后,并发访问情况下后续读操作能立即感知到更新,称为强一致性。
- 如果更新数据后,允许部分或者全部感知不到该更新,称为弱一致性。
- 若在之后的一段时间后,一定可以感知到更新,称为最终一致性。
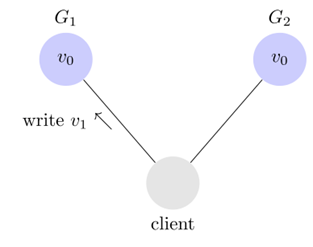

不一致性
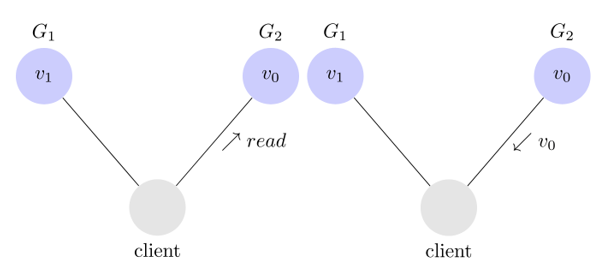
为了保持一致性

B. 可用性
- 任何一个没有故障的节点必须在优先的时间内返回合理的结果。
C. 分区容错性
- 部分节点宕机或者无法和其他节点通信时,各分区间还可保持分布式系统的功能。
D. kafka中的CAP应用
kafka满足CAP定律的CA。kafka写数据写入到不同的分区,每个分区可能有很多的副本,数据首先写到leader副本里面去,读写操作都是在leader分区进行通信,保证了数据的一致性。然后kafka通过分区机制来保证当中数据的可用性,但是存在另外的一个问题,就是副本分区当中的数据与leader当中数据存在差别的问题如何解决,这个就是分区容错性的问题。
kafka为了解决这个问题,使用了ISR的同步策略来尽可能的减少Partition tolerance的问题。每个leader会维护一个ISR的列表,这个列表的作用就是决定哪些副本分区是可用的,也就是说leader的数据同步到那个副本分区里面去。决定一个分区是否可用是由两个因素(见下),如果FollowOver超过一定时间或者消息落后太多leader会将其从isr的列表移除
replica.lag.time.max.ms=10000 副本分区与主分区心跳时间延迟replica.lag.max.messages=4000 副本分区与主分区消息同步最大差
12. kafka的监控和运维
##启动 cd /export/servers/kafka-eagle-bin-1.3.2/kafka-eagle-web-1.3.2/bin chmod u+x ke.sh ./ke.sh start ##进入网址 访问kafka-eagle http://hadoop03:8048/ke/account/signin?/ke/ 用户名:admin 密码:123456
补充:kafka消费消息为什么快?
1. 数据的存储按照队列的顺序进行存储
2. 采用页缓存(pagebuffer),系统级别的缓存。
3. 顺序读取数据(按照每一个分区)