1 SimHash简介
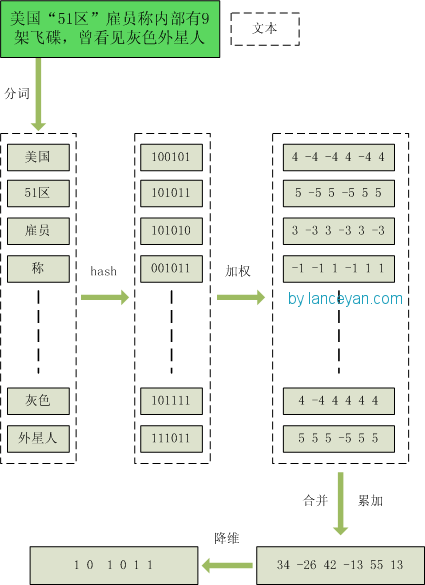
- 分词,把需要判断文本分词形成这个文章的特征单词,最后形成去掉噪音词的单词序列并为每个词加上权重。我们假设权重分为5个级别(1~5),比如:“ 美国“51区”雇员称内部有9架飞碟,曾看见灰色外星人 ” ==> 分词后为 “ 美国(4) 51区(5) 雇员(3) 称(1) 内部(2) 有(1) 9架(3) 飞碟(5) 曾(1) 看见(3) 灰色(4) 外星人(5)”,括号里是代表单词在整个句子里重要程度,数字越大越重要。
- hash,通过hash算法把每个词变成hash值,比如“美国”通过hash算法计算为 100101,“51区”通过hash算法计算为 101011。这样我们的字符串就变成了一串串数字,还记得文章开头说过的吗,要把文章变为数字计算才能提高相似度计算性能,现在是降维过程进行时。
- 加权,通过 2步骤的hash生成结果,需要按照单词的权重形成加权数字串,比如“美国”的hash值为“100101”,通过加权计算为“4 -4 -4 4 -4 4”;“51区”的hash值为“101011”,通过加权计算为 “ 5 -5 5 -5 5 5”。
- 合并,把上面各个单词算出来的序列值累加,变成只有一个序列串。比如 “美国”的 “4 -4 -4 4 -4 4”,“51区”的 “ 5 -5 5 -5 5 5”, 把每一位进行累加, “4+5 -4+-5 -4+5 4+-5 -4+5 4+5” ==》 “9 -9 1 -1 1 9”。这里作为示例只算了两个单词的,真实计算需要把所有单词的序列串累加。
- 降维,把4步算出来的 “9 -9 1 -1 1 9” 变成 0 1 串,形成我们最终的simhash签名。 如果每一位大于0 记为 1,小于0 记为 0。最后算出结果为:“1 0 1 0 1 1”。
过程图为:
2 算法几何意义及原理
2.1 几何意义
这个算法的几何意义非常明了。它首先将每一个特征映射为f维空间的一个向量,这个映射规则具体是怎样并不重要,只要对很多不同的特征来说,它们对所对应的向量是均匀随机分布的,并且对相同的特征来说对应的向量是唯一的就行。比如一个特征的4位hash签名的二进制表示为1010,那么这个特征对应的 4维向量就是(1, -1, 1, -1)T,即hash签名的某一位为1,映射到的向量的对应位就为1,否则为-1。然后,将一个文档中所包含的各个特征对应的向量加权求和,加权的系数等于该特征的权重。得到的和向量即表征了这个文档,我们可以用向量之间的夹角来衡量对应文档之间的相似度。最后,为了得到一个f位的签名,需要进一步将其压缩,如果和向量的某一维大于0,则最终签名的对应位为1,否则为0。这样的压缩相当于只留下了和向量所在的象限这个信息,而64位的签名可以表示多达264个象限,因此只保存所在象限的信息也足够表征一个文档了。
2.2 原理
明确了算法了几何意义,使这个算法直观上看来是合理的。但是,为何最终得到的签名相近的程度,可以衡量原始文档的相似程度呢?这需要一个清晰的思路和证明。在simhash的发明人Charikar的论文中并没有给出具体的simhash算法和证明,以下列出我自己得出的证明思路。
Simhash是由随机超平面hash算法演变而来的,随机超平面hash算法非常简单,对于一个n维向量v,要得到一个f位的签名(f<<n),算法如下:
- 随机产生f个n维的向量r1,…rf;
- 对每一个向量ri,如果v与ri的点积大于0,则最终签名的第i位为1,否则为0。
这个算法相当于随机产生了f个n维超平面,每个超平面将向量v所在的空间一分为二,v在这个超平面上方则得到一个1,否则得到一个0,然后将得到的 f个0或1组合起来成为一个f维的签名。如果两个向量u, v的夹角为θ,则一个随机超平面将它们分开的概率为θ/π,因此u, v的签名的对应位不同的概率等于θ/π。所以,我们可以用两个向量的签名的不同的对应位的数量,即汉明距离,来衡量这两个向量的差异程度。
Simhash算法与随机超平面hash是怎么联系起来的呢?在simhash算法中,并没有直接产生用于分割空间的随机向量,而是间接产生的:第 k个特征的hash签名的第i位拿出来,如果为0,则改为-1,如果为1则不变,作为第i个随机向量的第k维。由于hash签名是f位的,因此这样能产生 f个随机向量,对应f个随机超平面。下面举个例子:
假设用5个特征w1,…,w5来表示所有文档,现要得到任意文档的一个3维签名。假设这5个特征对应的3维向量分别为:
h(w1) = (1, -1, 1)T
h(w2) = (-1, 1, 1)T
h(w3) = (1, -1, -1)T
h(w4) = (-1, -1, 1)T
h(w5) = (1, 1, -1)T
按simhash算法,要得到一个文档向量d=(w1=1, w2=2, w3=0, w4=3, w5=0) T的签名,
先要计算向量m = 1*h(w1) + 2*h(w2) + 0*h(w3) + 3*h(w4) + 0*h(w5) = (-4, -2, 6) T,然后根据simhash算法的步骤3,得到最终的签名s=001。上面的计算步骤其实相当于,先得到3个5维的向量,第1个向量由h(w1),…,h(w5)的第1维组成:r1=(1,-1,1,-1,1) T;第2个5维向量由h(w1),…,h(w5)的第2维组成:r2=(-1,1,-1,-1,1) T;同理,第3个5维向量为:r3=(1,1,-1,1,-1) T.按随机超平面算法的步骤2,分别求向量d与r1,r2,r3的点积:
d T r1=-4 < 0,所以s1=0;
d T r2=-2 < 0,所以s2=0;
d T r3=6 > 0,所以s3=1.
故最终的签名s=001,与simhash算法产生的结果是一致的。
从上面的计算过程可以看出,simhash算法其实与随机超平面hash算法是相同的,simhash算法得到的两个签名的汉明距离,可以用来衡量原始向量的夹角。这其实是一种降维技术,将高维的向量用较低维度的签名来表征。衡量两个内容相似度,需要计算汉明距离,这对给定签名查找相似内容的应用来说带来了一些计算上的困难。
3 Java算法实现
1 import java.math.BigInteger; 2 import java.util.ArrayList; 3 import java.util.HashMap; 4 import java.util.List; 5 import java.util.StringTokenizer; 6 7 public class SimHash { 8 9 private String tokens; 10 11 private BigInteger intSimHash; 12 13 private String strSimHash; 14 15 private int hashbits = 64; 16 17 public SimHash(String tokens) { 18 this.tokens = tokens; 19 this.intSimHash = this.simHash(); 20 } 21 22 public SimHash(String tokens, int hashbits) { 23 this.tokens = tokens; 24 this.hashbits = hashbits; 25 this.intSimHash = this.simHash(); 26 } 27 28 HashMap wordMap = new HashMap(); 29 30 public BigInteger simHash() { 31 // 定义特征向量/数组 32 int[] v = new int[this.hashbits]; 33 // 1、将文本去掉格式后, 分词. 34 StringTokenizer stringTokens = new StringTokenizer(this.tokens); 35 while (stringTokens.hasMoreTokens()) { 36 String temp = stringTokens.nextToken(); 37 // 2、将每一个分词hash为一组固定长度的数列.比如 64bit 的一个整数. 38 BigInteger t = this.hash(temp); 39 for (int i = 0; i < this.hashbits; i++) { 40 BigInteger bitmask = new BigInteger("1").shiftLeft(i); 41 // 3、建立一个长度为64的整数数组(假设要生成64位的数字指纹,也可以是其它数字), 42 // 对每一个分词hash后的数列进行判断,如果是1000...1,那么数组的第一位和末尾一位加1, 43 // 中间的62位减一,也就是说,逢1加1,逢0减1.一直到把所有的分词hash数列全部判断完毕. 44 if (t.and(bitmask).signum() != 0) { 45 // 这里是计算整个文档的所有特征的向量和 46 // 这里实际使用中需要 +- 权重,而不是简单的 +1/-1, 47 v[i] += 1; 48 } else { 49 v[i] -= 1; 50 } 51 } 52 } 53 BigInteger fingerprint = new BigInteger("0"); 54 StringBuffer simHashBuffer = new StringBuffer(); 55 for (int i = 0; i < this.hashbits; i++) { 56 // 4、最后对数组进行判断,大于0的记为1,小于等于0的记为0,得到一个 64bit 的数字指纹/签名. 57 if (v[i] >= 0) { 58 fingerprint = fingerprint.add(new BigInteger("1").shiftLeft(i)); 59 simHashBuffer.append("1"); 60 } else { 61 simHashBuffer.append("0"); 62 } 63 } 64 this.strSimHash = simHashBuffer.toString(); 65 System.out.println(this.strSimHash + " length " + this.strSimHash.length()); 66 return fingerprint; 67 } 68 69 private BigInteger hash(String source) { 70 if (source == null || source.length() == 0) { 71 return new BigInteger("0"); 72 } else { 73 char[] sourceArray = source.toCharArray(); 74 BigInteger x = BigInteger.valueOf(((long) sourceArray[0]) << 7); 75 BigInteger m = new BigInteger("1000003"); 76 BigInteger mask = new BigInteger("2").pow(this.hashbits).subtract(new BigInteger("1")); 77 for (char item : sourceArray) { 78 BigInteger temp = BigInteger.valueOf((long) item); 79 x = x.multiply(m).xor(temp).and(mask); 80 } 81 x = x.xor(new BigInteger(String.valueOf(source.length()))); 82 if (x.equals(new BigInteger("-1"))) { 83 x = new BigInteger("-2"); 84 } 85 return x; 86 } 87 } 88 89 public int hammingDistance(SimHash other) { 90 91 BigInteger x = this.intSimHash.xor(other.intSimHash); 92 int tot = 0; 93 94 // 统计x中二进制位数为1的个数 95 // 我们想想,一个二进制数减去1, 96 //那么,从最后那个1(包括那个1)后面的数字全都反了, 97 //对吧,然后,n&(n-1)就相当于把后面的数字清0, 98 // 我们看n能做多少次这样的操作就OK了。 99 100 while (x.signum() != 0) { 101 tot += 1; 102 x = x.and(x.subtract(new BigInteger("1"))); 103 } 104 return tot; 105 } 106 107 public int getDistance(String str1, String str2) { 108 int distance; 109 if (str1.length() != str2.length()) { 110 distance = -1; 111 } else { 112 distance = 0; 113 for (int i = 0; i < str1.length(); i++) { 114 if (str1.charAt(i) != str2.charAt(i)) { 115 distance++; 116 } 117 } 118 } 119 return distance; 120 } 121 122 public List subByDistance(SimHash simHash, int distance) { 123 // 分成几组来检查 124 int numEach = this.hashbits / (distance + 1); 125 List characters = new ArrayList(); 126 127 StringBuffer buffer = new StringBuffer(); 128 129 int k = 0; 130 for (int i = 0; i < this.intSimHash.bitLength(); i++) { 131 // 当且仅当设置了指定的位时,返回 true 132 boolean sr = simHash.intSimHash.testBit(i); 133 134 if (sr) { 135 buffer.append("1"); 136 } else { 137 buffer.append("0"); 138 } 139 140 if ((i + 1) % numEach == 0) { 141 // 将二进制转为BigInteger 142 BigInteger eachValue = new BigInteger(buffer.toString(), 2); 143 System.out.println("----" + eachValue); 144 buffer.delete(0, buffer.length()); 145 characters.add(eachValue); 146 } 147 } 148 149 return characters; 150 } 151 152 public static void main(String[] args) { 153 String s = "小明叫她妈妈吃饭"; 154 SimHash hash1 = new SimHash(s, 64); 155 System.out.println(hash1.intSimHash + " " + hash1.intSimHash.bitLength()); 156 //hash1.subByDistance(hash1, 3); 157 158 s = "小明叫她妈妈吃饭"; 159 SimHash hash2 = new SimHash(s, 64); 160 System.out.println(hash2.intSimHash + " " + hash2.intSimHash.bitCount()); 161 //hash1.subByDistance(hash2, 3); 162 163 s = "小明叫她妈妈"; 164 SimHash hash3 = new SimHash(s, 64); 165 System.out.println(hash3.intSimHash + " " + hash3.intSimHash.bitCount()); 166 //hash1.subByDistance(hash3, 4); 167 168 System.out.println("============================"); 169 170 int dis = hash1.getDistance(hash1.strSimHash, hash2.strSimHash); 171 System.out.println(hash1.hammingDistance(hash2) + " " + dis); 172 173 int dis2 = hash1.getDistance(hash1.strSimHash, hash3.strSimHash); 174 System.out.println(hash1.hammingDistance(hash3) + " " + dis2); 175 176 //通过Unicode编码来判断中文 177 /*String str = "中国chinese"; 178 for (int i = 0; i < str.length(); i++) { 179 System.out.println(str.substring(i, i + 1).matches("[\u4e00-\u9fbb]+")); 180 }*/ 181 182 } 183 }
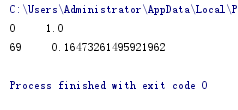
结果:

4 Python算法实现
1 #!/usr/bin/python 2 # coding=utf-8 3 class simhash: 4 # 构造函数 5 def __init__(self, tokens='', hashbits=128): 6 self.hashbits = hashbits 7 self.hash = self.simhash(tokens); 8 9 # toString函数 10 11 def __str__(self): 12 return str(self.hash) 13 14 # 生成simhash值 15 16 def simhash(self, tokens): 17 v = [0] * self.hashbits 18 for t in [self._string_hash(x) for x in tokens]: # t为token的普通hash值 19 for i in range(self.hashbits): 20 bitmask = 1 << i 21 if t & bitmask: 22 v[i] += 1 # 查看当前bit位是否为1,是的话将该位+1 23 else: 24 v[i] -= 1 # 否则的话,该位-1 25 fingerprint = 0 26 for i in range(self.hashbits): 27 if v[i] >= 0: 28 fingerprint += 1 << i 29 return fingerprint # 整个文档的fingerprint为最终各个位>=0的和 30 31 # 求海明距离 32 def hamming_distance(self, other): 33 x = (self.hash ^ other.hash) & ((1 << self.hashbits) - 1) 34 tot = 0; 35 while x: 36 tot += 1 37 x &= x - 1 38 return tot 39 40 # 求相似度 41 42 def similarity(self, other): 43 a = float(self.hash) 44 b = float(other.hash) 45 if a > b: 46 return b / a 47 else: 48 return a / b 49 50 # 针对source生成hash值 (一个可变长度版本的Python的内置散列) 51 52 def _string_hash(self, source): 53 if source == "": 54 return 0 55 else: 56 x = ord(source[0]) << 7 57 m = 1000003 58 mask = 2 ** self.hashbits - 1 59 for c in source: 60 x = ((x * m) ^ ord(c)) & mask 61 x ^= len(source) 62 if x == -1: 63 x = -2 64 return x 65 66 67 if __name__ == '__main__': 68 s = '小明叫她妈妈吃饭' 69 hash1 = simhash(s.split()) 70 71 s = '小明叫她妈妈吃饭' 72 hash2 = simhash(s.split()) 73 74 s = '小明叫她妈妈' 75 hash3 = simhash(s.split()) 76 77 print(hash1.hamming_distance(hash2), " ", hash1.similarity(hash2)) 78 print(hash1.hamming_distance(hash3), " ", hash1.similarity(hash3))
结果:
注:SimHash适用于大文本处理(>400字),对于小文本而言,误差较大!!!