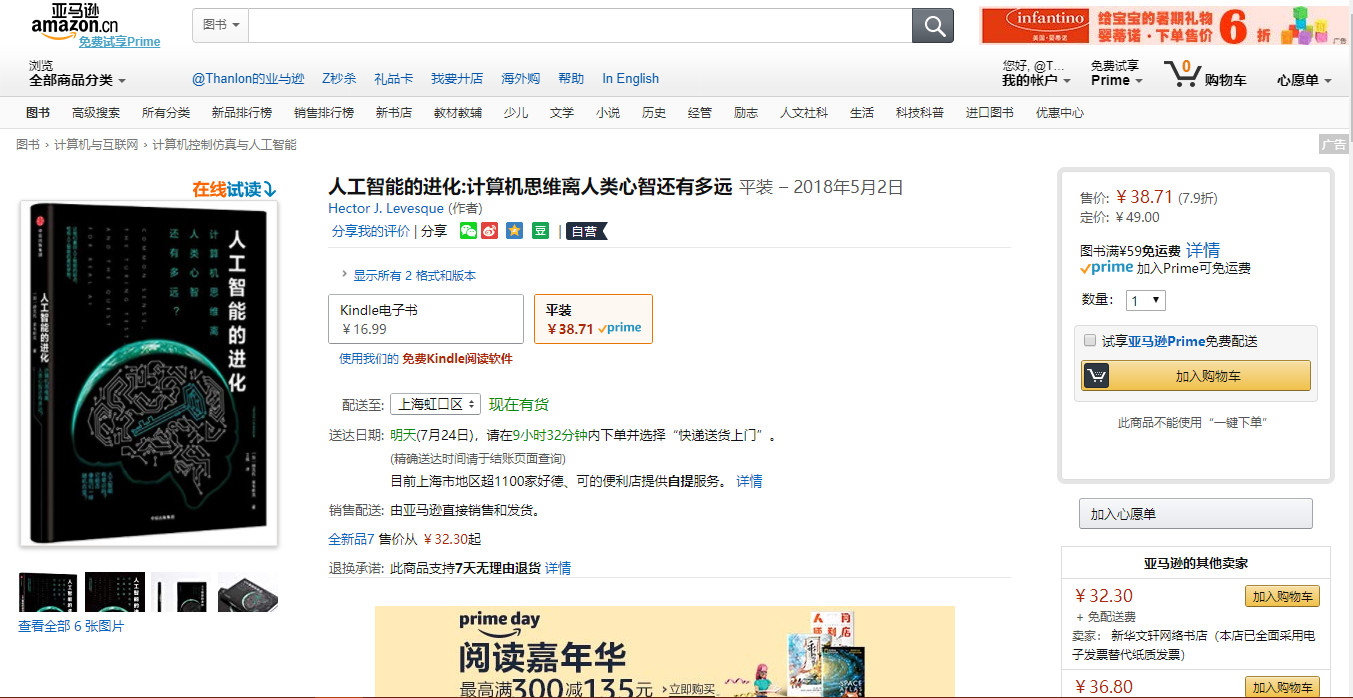
1、亚马逊商品页面链接地址(本次要爬取的页面url)
https://www.amazon.cn/dp/B07BSLQ65P/
2、代码部分
import requests
url = "https://www.amazon.cn/dp/B07BSLQ65P/"
try:
kv = {'user-agent': 'Mozilla/5.0'}
# 修改了发起请求的请求头中的user-agent的值,告诉目的url这是由浏览器发送的请求
r = requests.get(url, headers=kv)
r.raise_for_status()
r.encoding = r.apparent_encoding
print(r.text)
except:
print("爬取页面失败!")
3、打印结果
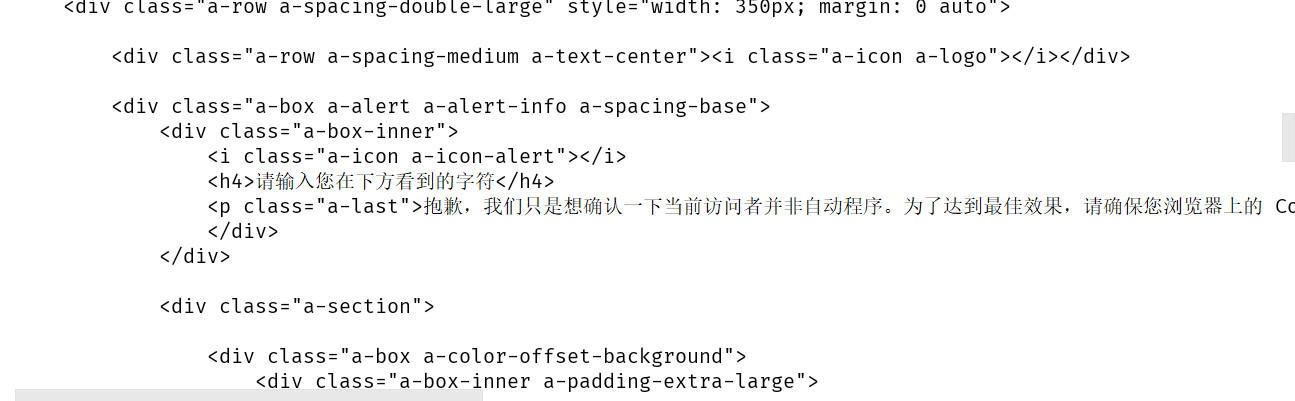
根据打印出的信息,很明显不是爬取到的目的url页面。可以将爬取到的页面在浏览器中打开,可以看到爬取到的其实是这样的页面:
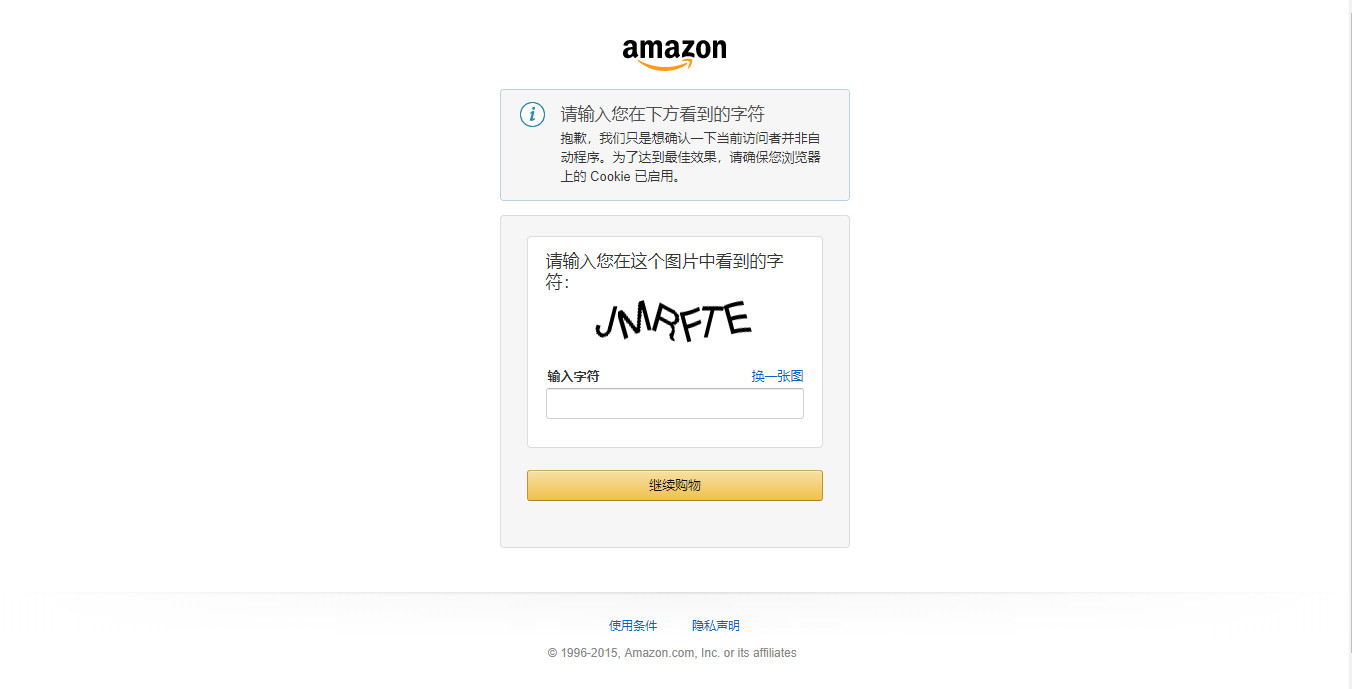
其实,这应该是亚马逊网站反爬虫的策略。对于如何爬取亚马逊商品页面,当然应该会有方法的,暂时先记录到这里吧!