个人作业2——WordCount
标签(空格分隔): 软件工程
Task1:Fork仓库的码云地址
码云地址:https://gitee.com/JiuSong/PersonalProject-Java
Task2:PSP表格
| PSP2.1 | 个人开发流程 | 预估耗费时间(分钟) | 实际耗费时间(分钟) |
|---|---|---|---|
| Planning | 计划 | 10 | 20 |
| · Estimate | 明确需求和其他相关因素,估计每个阶段的时间成本 | 20 | 20 |
| Development | 开发 | 240 | 300 |
| · Analysis | 需求分析 (包括学习新技术) | 20 | 30 |
| · Design Spec | 生成设计文档 | 20 | 25 |
| · Design Review | 设计复审 | 20 | 20 |
| · Coding Standard | 代码规范 | 10 | 10 |
| · Design | 具体设计 | 20 | 26 |
| · Coding | 具体编码 | 120 | 150 |
| · Code Review | 代码复审 | 20 | 25 |
| · Test | 测试(自我测试,修改代码,提交修改) | 60 | 70 |
| Reporting | 报告 | 80 | 110 |
| · | 测试报告 | 20 | 25 |
| · | 计算工作量 | 10 | 15 |
| · | 并提出过程改进计划 | 20 | 15 |
Task3:解题思路描述
题目的需求分析:
- 统计文件的字符数:
- 只需要统计Ascii码,汉字不需考虑
- 空格,水平制表符,换行符,均算字符
- 统计文件的单词总数,单词:至少以4个英文字母开头,跟上字母数字符号,单词以分隔符分割,不区分大小写。
- 英文字母: A-Z,a-z
- 字母数字符号:A-Z, a-z,0-9
- 分割符:空格,非字母数字符号
- 例:file123是一个单词, 123file不是一个单词。file,File和FILE是同一个单词
- 统计文件的有效行数:任何包含非空白字符的行,都需要统计。
- 统计文件中各单词的出现次数,最终只输出频率最高的10个。频率相同的单词,优先输出字典序靠前的单词。
- 按照字典序输出到文件result.txt:例如,windows95,windows98和windows2000同时出现时,则先输出windows2000
- 输出的单词统一为小写格式
- 输出的格式为
characters: number
words: number
lines: number
<word1>: number
<word2>: number
...
思路分析:
刚拿到题目时,就先分析了一下需求,经过网上查找资料,经过如下分析过程:
- 问题首先需要解决的是如何读文件?如何写文件?整个的类的封装要怎么构造。
- 统计文件字符数时,又有一个重点就是不区分大小写并且是输出单词统一为小写格式,所以我想到的是先对文件进行处理,读出来的整个内容赋予给一个字符串,在进行单词数量统计之前将字符串统一转化为小写格式
string.toLowerCase() - 题目要求讲的单词至少4个英文字母开头,所以
FILE1234可以作为单词,但123FILE这就不能算作单词。又因为要统计单词的频率,所以可以用Map来写,单词作为Key,频数作为Value值。 - 统计总的字符数,可以对全部内容进行读取,用
换行(' ')、回车(' ')来进行数组的切分,这样每一组都是原来的一行,然后对每一个数组元素去除空格后进行比较,如果空则原来是空内容的一行。
最后综合以上分析可以得到流程图如下:

Task4:设计实现过程
一、相关类的设计
针对这个要求,得到一个主函数,两个类,其中:
- Word类:进行字符数量、行数、单词数、词频的统计。
- OperateFile类:进行文件内容的读取,以及处理结果的写入。
- Main类:结合实际情况,创建以上两种对象,进行方法的调用,实现题目要求。
二、相关函数的设计
Word:
- wd.getcharNum(); //字符数统计
- wd.getwordNum();//单词数统计
- wd.getlineNum();//有效行统计
- wd.getwordFreq();//单词频率统计
OperateFile:
- fd.FileToString(file);//读出文件内容变成字符串
- fd.WriteToFile(w);//结果写入指定文件
Task5:代码说明
1. getcharNum()
//统计文件的字符数:只需要统计Ascii码,汉字不需考虑空格,水平制表符,换行符,均算字符
public int getcharNum()
{
char ch;
for(int i = 0;i<str.length();i++)
{
ch = str.charAt(i);//String str = "abc";char ch = str.charAt(0);char ch2 = str.charAt(1);这时候ch是a,ch2是b;
if(ch>=32 && ch<=126 || ch == '
' || ch == '
' || ch == ' ') //换行('
')、回车('
')、水平制表符(' ')、垂直制表符('v')
{
charNum++;
}
}
return charNum;
}
2. getwordNum()
//统计文件的单词总数,单词:以4个英文字母开头,跟上字母数字符号,单词以分隔符分割,不区分大小写。
节选:
for(int i = 0;i<everyword.length;i++)
{
if(everyword[i].length()<4)
{
continue;
}
else //符合长度的单词
{
int flag=0;
char[] ch = everyword[i].toCharArray();//每一个everyword数组内容拆分成字符数组
for(int j = 0;j<4;j++)
{
if(!(ch[j]>= 'A' && ch[j]<= 'Z' || ch[j]>= 'a' && ch[j]<= 'z'))
{
flag=1;
}
}
if(flag ==0 )
{
wordNum++;
}
}
}
3. getlineNum()
//统计文件的有效行数:任何包含非空白字符的行,都需要统计。
public int getlineNum()
{
String[] line = str.split("
|
");//换行('
')、回车('
')
for(int i=0; i<line.length;i++)
{
if(line[i].trim().isEmpty())
{
continue;
}
else
{
lineNum++;
}
}
return lineNum;
}
4. getwordFreq()
//单词频率统计
public List<Map.Entry<String, Integer>> getwordFreq()
{
wordFreq = new HashMap<String,Integer>();
String s = str;
s = s.replace('
',' ');
s = s.replace('
',' ');
s = s.replace(' ',' ');
String[] everyword = s.split(" ");//用空格作为分割
for(int i = 0;i<everyword.length;i++)
{
if(everyword[i].length()<4)
{
continue;
}
else
{
int flag=0;
char[] ch = everyword[i].toCharArray();
for(int j = 0;j<4;j++)
{
if(!(ch[j]>= 'A' && ch[j]<= 'Z' || ch[j]>= 'a' && ch[j]<= 'z'))//开头四位不全为字母
{
flag=1;
}
}
if(flag ==0 )//符合一个单词的标准
{
String key = everyword[i].trim().toLowerCase();//统一转换成小写
if (wordFreq.containsKey(key)){
int n=Integer.parseInt(wordFreq.get(key).toString())+1;
wordFreq.put(key,n);
}else {
wordFreq.put(key,1);
}
}
}
}
List<Map.Entry<String, Integer>> list = new ArrayList<Map.Entry<String, Integer>>(wordFreq.entrySet());
Collections.sort(list, new Comparator<Map.Entry<String, Integer>>() {
@Override//降序排序
public int compare(Entry<String, Integer> o1, Entry<String, Integer> o2) {
// TODO Auto-generated method stub
if(o1.getValue() == o2.getValue())
{
return o1.getKey().compareTo(o2.getKey());
}
return o2.getValue().compareTo(o1.getValue());
}
});
return list;
/* for (Entry<String, Integer> mapping : list) { //输出
System.out.println(mapping.getKey() + ":" + mapping.getValue());
} */
}
该函数用于单词词频的统计,按照要求首先判断词是否为单词,然后实验map进行储存,由于map的key不可重复,则每次写入时需要判断map之前是否存在过该数据,若没有存在过,则该value值为1,否则,在其value值上再加1.
统计后,将map改为list存储,再用Collections.sort进行排序,通过重写comparator来实现要求的排序。
Task6:单元测试
根据以上函数,设置了一些测试点,尽可能罗列出各种情况:
- 字符数为空
- 完全的中文文件
- 完全的英文文件
- 完全的英文文件,大小写混合
- 完全的英文文件,无合法单词
对应设置的文件为:
- test1:完全的空文件
- test2:纯中文文件,不含有英文
- test3:纯英文文件,完全小写
- test4:纯英文文件,大小写混合
- test5:英文、数字、特殊符号混合
测试代码:
package WordCount;
import static org.junit.Assert.*;
import java.io.IOException;
import java.util.ArrayList;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
import java.util.Scanner;
import org.junit.Before;
import org.junit.Test;
public class WordTest {
//String file1 = "text1.txt";
//String file2 = "text2.txt";
//String file3 = "text3.txt";
//String file4 = "text4.txt";
/* Scanner sc =new Scanner(System.in);
String file1 = sc.next();
String file2 = sc.next();
String file3 = sc.next();
String file4 = sc.next();
*/
@Before
public void setUp() throws Exception {
}
//统计字符数量测试
@Test
public void testGetcharNum() throws IOException {
OperateFile fd = new OperateFile();
// System.out.print(file1);
String str1 = fd.FileToString("test1.txt");//读出文件内容变成字符串
String str2 = fd.FileToString("test2.txt");
String str3 = fd.FileToString("test3.txt");
String str4 = fd.FileToString("test4.txt");
Word wd1 = new Word(str1);
Word wd2 = new Word(str2);
Word wd3 = new Word(str3);
Word wd4 = new Word(str4);
int p1 = wd1.getcharNum();//调用
int p2 = wd2.getcharNum();
int p3 = wd3.getcharNum();
int p4 = wd4.getcharNum();
assertEquals(0, p1);//测试与结果匹配
assertEquals(37, p2);
assertEquals(86, p3);
assertEquals(272, p4);
}
@Test
public void testGetwordNum() throws IOException {//统计单词数量测试
OperateFile fd = new OperateFile();
String str1 = fd.FileToString("test1.txt");//读出文件内容变成字符串
String str2 = fd.FileToString("test2.txt");
String str3 = fd.FileToString("test3.txt");
String str4 = fd.FileToString("test4.txt");
Word wd1 = new Word(str1);
Word wd2 = new Word(str2);
Word wd3 = new Word(str3);
Word wd4 = new Word(str4);
int p1 = wd1.getwordNum();//调用
int p2 = wd2.getwordNum();
int p3 = wd3.getwordNum();
int p4 = wd4.getwordNum();
assertEquals(0, p1);//测试与结果匹配
assertEquals(0, p2);
assertEquals(10, p3);
assertEquals(35, p4);
}
@Test
public void testGetlineNum() throws IOException {//统计有效行数测试
OperateFile fd = new OperateFile();
String str1 = fd.FileToString("test1.txt");//读出文件内容变成字符串
String str2 = fd.FileToString("test2.txt");
String str3 = fd.FileToString("test3.txt");
String str4 = fd.FileToString("test4.txt");
Word wd1 = new Word(str1);
Word wd2 = new Word(str2);
Word wd3 = new Word(str3);
Word wd4 = new Word(str4);
int p1 = wd1.getlineNum();//调用
int p2 = wd2.getlineNum();
int p3 = wd3.getlineNum();
int p4 = wd4.getlineNum();
assertEquals(0, p1);//测试与结果匹配
assertEquals(6, p2);
assertEquals(4, p3);
assertEquals(12, p4);
}
@Test
public void testGetwordFreq() throws IOException {//统计词频测试
OperateFile fd = new OperateFile();
String str1 = fd.FileToString("test1.txt");//读出文件内容变成字符串
String str2 = fd.FileToString("test2.txt");
String str5 = fd.FileToString("test5.txt");
Word wd1 = new Word(str1);
Word wd2 = new Word(str2);
Word wd5 = new Word(str5);
List<Map.Entry<String, Integer>> wordFreq1 = wd1.getwordFreq();
List<Map.Entry<String, Integer>> wordFreq2 = wd2.getwordFreq();
List<Map.Entry<String, Integer>> wordFreq5 = wd5.getwordFreq();
Map<String,Integer> w1 = new HashMap<String,Integer>();
Map<String,Integer> w2 = new HashMap<String,Integer>();
Map<String,Integer> w3 = new HashMap<String,Integer>();
// Map<String,Integer> w4 = new HashMap<String,Integer>();
w3.put("jiusong", 4);
w3.put("test111", 1);
List<Map.Entry<String, Integer>> t1 = new ArrayList<Map.Entry<String, Integer>>(w1.entrySet());
List<Map.Entry<String, Integer>> t2 = new ArrayList<Map.Entry<String, Integer>>(w2.entrySet());
List<Map.Entry<String, Integer>> t3 = new ArrayList<Map.Entry<String, Integer>>(w3.entrySet());
assertEquals(t1, wordFreq1);
assertEquals(t2, wordFreq2);
assertEquals(t3, wordFreq5);
/*
jiusong=4
test111=1*/
}
}
测试结果:

分值覆盖率截图:
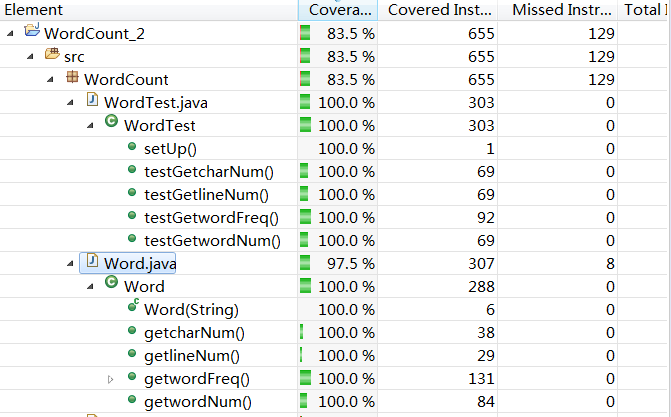
代码内的覆盖率:
在右侧工具栏中点击”Coverage”图标,打开Coverage的视图后,代码字体背景变红/变绿/变黄原因,经过百度后,有关覆盖测试的颜色含义如下:
Source lines containing executable code get the following color code:
1.green for fully covered lines,
2.yellow for partly covered lines (some instructions or branches missed) and
3.red for lines that have not been executed at all.
即:
- 绿色为完全覆盖的线条,
- 黄色部分覆盖的线条(一些指示或分支遗漏)
- 红色表示尚未执行的行
测试的代码中,在word处理类里面这两部分吗没有完全被覆盖:


Task7:效能分析
分析图,由Jprofiler生成:
运行结果:
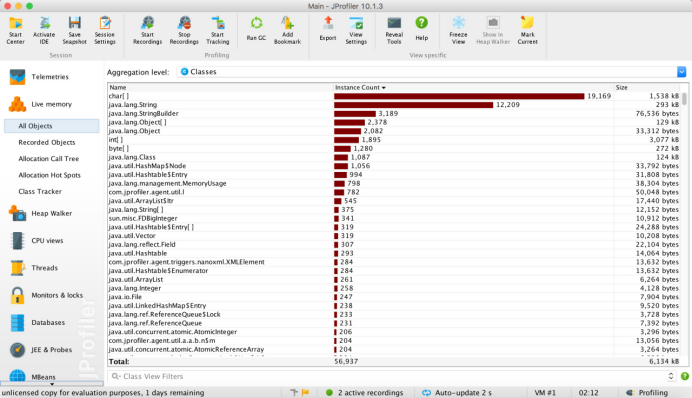


分析:
根据以上生成的图,可知道char[]、String用得比较多。在统计文件的单词总数中,有用到char[],嵌套在一个大的for循环中,可能是因为循环的缘故导致调用的频率比较高。因为对一个文件运行时,相当于把整个文件中的每个字符都变成了char[]中的一员,数量比较庞大。
Task8:心得体会
在这次试验中,我发现自己学到了很多编写代码以外其他的很多内容,一个项目的核心不仅仅是代码,它的性能以及准确性也十分重要。之前我以为做软件就是要编写代码,现在我发现做单元测试进行分析是一件十分有意思的事情,尤其是eclemma得到的覆盖率,每个调用的多少频率如何,这可以帮助我们找到自己编写的代码的思维逻辑上的错误,更加快速准确的找到问题所在。
后面的jprofiler也十分的厉害,但是安装消耗了很久的时间,安装出了问题的解决也用了很久,可能是网上关于出错的教程太少,很多问题很难解决。还有就是这个软件只能做到很表面的一个小测试,有些测试给出的结果图有些看不懂,分析起来也很费劲。所以这边的截图只能粗略浅显的大概进行了一波分析。
总的来讲,这一次学到了很多,让我的观点也发生了一些改变,我觉得软件不再是单纯地写代码枯燥的事情,还可以进行分析进行测试,加大了我对这个事情的一个兴趣度。