写在前面:(这里总结了一些三次作业我查找用到的好办法)
1.正则表达式与字符串
正则表达式定义了字符串的模式,可以用来搜索、编辑或处理文本。关于正则表达式具体的语法可以参考菜鸟教程。
java.util.regex 包主要包括以下三个类:
- Pattern 类:
pattern 对象是一个正则表达式的编译表示。Pattern 类没有公共构造方法。要创建一个 Pattern 对象,你必须首先调用其公共静态编译方法,它返回一个 Pattern 对象。该方法接受一个正则表达式作为它的第一个参数。
- Matcher 类:
Matcher 对象是对输入字符串进行解释和匹配操作的引擎。与Pattern 类一样,Matcher 也没有公共构造方法。你需要调用 Pattern 对象的 matcher 方法来获得一个 Matcher 对象。
- PatternSyntaxException:
PatternSyntaxException 是一个非强制异常类,它表示一个正则表达式模式中的语法错误。
以第一次作业多项式的匹配为例:
public static boolean judge(String s) { int end = 0; Pattern p = Pattern.compile("[\+-]?\{\([\+-]?[0-9]{1,6},[\+-]?[0-9]{1,6}\)(,\([\+-]?[0-9]{1,6},[\+-]?[0-9]{1,6}\)){0,49}\}"); Matcher m = p.matcher(s); if(m.find()) { if(m.start() == 0) { end = m.end(); Pattern p1 = Pattern.compile("[\+-]\{\([\+-]?[0-9]{1,6},[\+-]?[0-9]{1,6}\)(,\([\+-]?[0-9]{1,6},[\+-]?[0-9]{1,6}\)){0,49}\}"); Matcher m1 = p1.matcher(s); while(m1.find()) { if(m1.start() == 0) end = 0; if(m1.start() == end) { end = m1.end(); } else return false; } } else return false; } if(end != s.length()) return false; return true; }
上述片段以一个多项式作为一个整体进行匹配,代码内运用到了正则表达式关于Pattern类和Matcher类的方法,不做过多描述。
这里需要注意的是,关于正则表达式的匹配有整体匹配与部分匹配两种。一开始写第一次作业时,我采用了多个多项式一起匹配的办法(即一个多项式可以重复被匹配50次),但在计算50个多项式每个多项式20项这样的大数据时,毫无意外的爆栈了,于是采用了部分匹配的模式,避免了爆栈的可能性。然而在具体运用过程中,如果需要匹配的字符串长度一般,我更倾向于整体匹配直接得到结果。
字符串被判断合法后也可以利用正则表达式对需要用到的部分进行提取。例如在第三次作业中(只截取了对FR判断的部分代码):
String pattern1 = "\(FR,\+?\d+,(UP|DOWN),\+?\d+\)"; String pattern2 = "\(ER,\+?\d+,\+?\d+\)"; if(Pattern.matches(pattern1, s)) { type = 0; Pattern p = Pattern.compile("\d+"); Matcher m = p.matcher(s); if(m.find()) { num1 = Integer.parseInt(m.group()); } if(m.find()) { num2 = Long.parseLong(m.group()); } Pattern p1 = Pattern.compile("UP"); Matcher m1 = p1.matcher(s); if(m1.find()) updown = 0; else updown = 1;
这里可以发现Java中有一个非常好用的工具
Integer.parseInt(String)就是将String字符类型数据转换为Integer整型数据。(Long.parseInt(String)的作用也就可以意会了)
Integer.parseInt(String)遇到一些不能被转换为整型的字符时,会抛出异常。
2.try-catch判断异常
这里接着上部分进行叙述,如果字符串转为整型时超出整型的范围了怎么办,下面的方法可以解决这个问题:
try{
有可能出现错误的代码写在这里
}
catch{
出错后的处理
}
如果try中的代码没有出错,则程序正常运行try中的内容后,不会执行catch中的内容,
如果try中的代码一但出错,程序立即跳入catch中去执行代码,那么try中出错代码后的所有代码就不再执行了.
3.接口的使用
想来老师课上的ppt已经大致介绍了接口的使用方法这里不多做赘述,下面看一段第三次作业代码的使用实例:
interface Elemovement{ public void up();//上1层 public void down();//下1层 public void door();//开关门 }
在这段代码中,用接口实现了对电梯运动行为的刻画,在接下来的类中则对这三个方法进行具体行为的书写,使电梯的运动行为逻辑清晰:
public class Elevator implements Elemovement { //...... public void up(){ position ++; time += 0.5; } public void down() { position --; time += 0.5; } public void door(){ time ++; } //toString 来获得电梯运行状态和时刻的观察 public String toString() { String s; DecimalFormat df = new DecimalFormat("#.0"); s = "("+position+","+dir+","+df.format(time)+")"; return s; } }
这段代码中还用到了老师上课时要求的对toString的使用要求,这里大家可以自行参考(毕竟笔者的水平也很渣)。
4.继承的使用
以课上公司员工和课下电梯调度类为例,继承用法的必要性不必多说,子类继承父类的特征和行为,使得子类对象(实例)具有父类的实例域和方法,或子类从父类继承方法,使得子类具有父类相同的行为。这有利于构建起有层次逻辑的代码结构,不会出现代码量大且臃肿且维护性不高的缺点。这里需要注意的有以下几点:
- 子类拥有父类非private的属性,方法。
子类可以拥有自己的属性和方法,即子类可以对父类进行扩展。
子类可以用自己的方式实现父类的方法。
通过继承的关键字来记住并避免使用时容易犯的错误:
extends关键字
在 Java 中,类的继承是单一继承,也就是说,一个子类只能拥有一个父类,所以 extends 只能继承一个类。
super 与 this 关键字
super关键字:我们可以通过super关键字来实现对父类成员的访问,用来引用当前对象的父类。
this关键字:指向自己的引用。
这里引出构造器的易错点:(以oo第二次实验课上修改的代码为例)
子类不能继承父类的构造器(构造方法或者构造函数),但是父类的构造器带有参数的,则必须在子类的构造器中显式地通过super关键字调用父类的构造器并配以适当的参数列表。
class Person{ public String name; public char sex; public int age; Person(String name,char sex,int age){ this.name=name; this.sex=sex; this.age=age; } } class Teacher extends Person implements PrintInfo{ public String departmentno,tno; Teacher(String name,char sex,int age,String departmentno,String tno){ super(name, sex, age); this.tno=tno; this.departmentno=departmentno; } }
5.动态数组的使用
菜鸡本人在第二次作业第三次作业保存必要信息的时候使用的是定长的数组,这也给笔者在写代码过程中造成了巨大的困难。
在后来的百度过程中笔者发现了一个很好用的东西:ArrayList。
它的优点官方的解读是这样的:
(1)动态的增加和减少元素
(2)实现了ICollection和IList接口
(3)灵活的设置数组的大小
它的用法是这样的:
(1)ArrayList的创建
ArrayList <变量名> = new ArrayList(); //()中也可传参。
注意:上面是创建一个空的ArrayList列表。当我们想往列表中传递元素的时候是通过.add()的方法来进行赋值的。要想输出出列表中的元素的话要通过for循环遍历。如下:
public class test { public static void main(String[] args) { ArrayList lis = new ArrayList(); lis.add("tony"); lis.add("tom"); for(int i=0;i<lis.size();i++){ String result = (String)lis.get(i); System.out.println(result); }(2)ArrayList的常用方法
add(E e): 在数组末尾添加元素
size(): 数组中实际元素个数,并不是数组容量
add(int index, E e): 在数组指定位置添加元素
clear(): 将数组中元素清空
contains(E e): 判断数组中是否含有某个元素
get(int index): 返回数组指定位置的元素
indexOf(E e): 返回数组指定元素第一次出现的位置
set(int index, E e): 替换数组指定位置的值
remove(int index): 移除数组指定位置的元素
remove(E e): 移除数组中第一次出现的指定元素
addAll(Collection<? extends E> c): 在数组末尾添加另一个数组
addAll(int index, collection<? extends E> c): 在数组指定位置添加另一个数组
removeAll(Collection<?>c): 将数组中属于数组 c 中的元素全部删除
总结的比较凌乱,具体大家使用的时候不太会用可以善用万能的百度大神多看一些使用实例。
6.有神奇作用的优先队列
优先级队列是不同于先进先出队列的另一种队列,每次从队列中取出的是具有最高优先权的元素。网上搜到的实例大多数都很复杂,这里我用自己第三次作业的代码给大家简单看一下用法。
import java.util.Comparator; import java.util.PriorityQueue; import java.util.Queue; class Pqueue { int i; int x; //差值 Pqueue(int i, int x) { this.i = i; this.x = x; } int geti() { return this.i; } int getx() { return this.x; } public static Comparator<Pqueue> Order = new Comparator<Pqueue>() { public int compare(Pqueue o1, Pqueue o2) { int x1 = o1.getx(); int x2 = o2.getx(); int i1 = o1.geti(); int i2 = o2.geti(); if (x1 != x2) { return (x1 - x2); } return (i1 - i2); } }; public static Comparator<Pqueue> getorder() { return Order; } }
这段代码是干什么的呢?
这其实是捎带队列的存储,大家回忆一下捎带的具体要求,规定如果可以捎带,则距离当前楼层的先捎带,若果楼层相同,则发出请求时间在前的先捎带。所以我传入请求的目的楼层和当前楼层的差值和请求的下标,利用比较器判断优先级,没错这个比较器可以判断优先级后自动帮你排序,非常省事好用!
7.对方法名变量名的规范化
这里笔者不得不说,如果你的程序满篇都是a,b,c,x,i,j类似这样的变量名,这不但给别人读懂(看都懒得看)你的代码造成困扰,自己debug也不太好搞啊。
建议让每个类名,方法名,变量名都有具体的含义。
ps.这里可以多啰嗦一句,拿到要求不要立刻动手写代码,规划出一个大概的框架,例如这次代码我需要几个类,每个类都要干什么,根据每个类的用途我都需要构造哪些方法,设置哪些变量,想清楚之后,写起代码可以轻松很多。
这里是总结:
1.基于度量分析自己的程序结构
第一次作业:

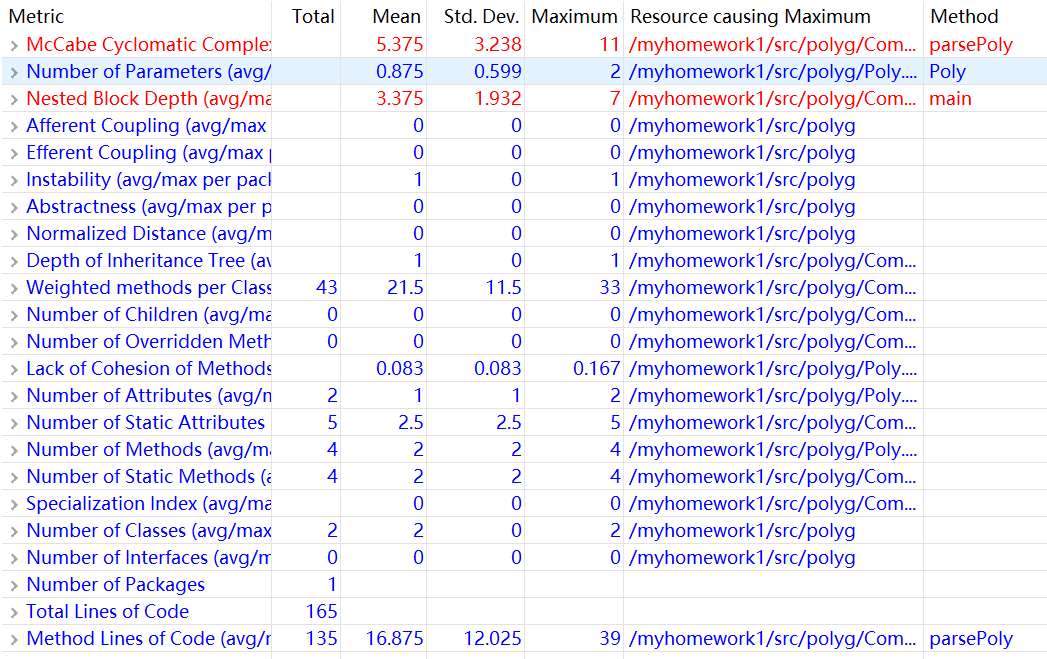
针对第一次作业,思路逻辑较为简单,不多做叙述,但初学Java,对面向对象编程的理解不够深入,根据老师ppt上的内容较为面向对象的编写了Poly类的代码,但当编写计算时,又回到了C语言的面向过程式编程,虽然没有逻辑运算上的错误,但其实就是个披着Java外表的C语言。但通过这次编程作业,确实让我理解到了面向对象编程和面向过程编程的区别(就是不太会用)。
可以改进之处是本可以在匹配正确之后直接提取并储存信息,这样可以减少代码的冗余,但当时并没有想到。
第二次作业:

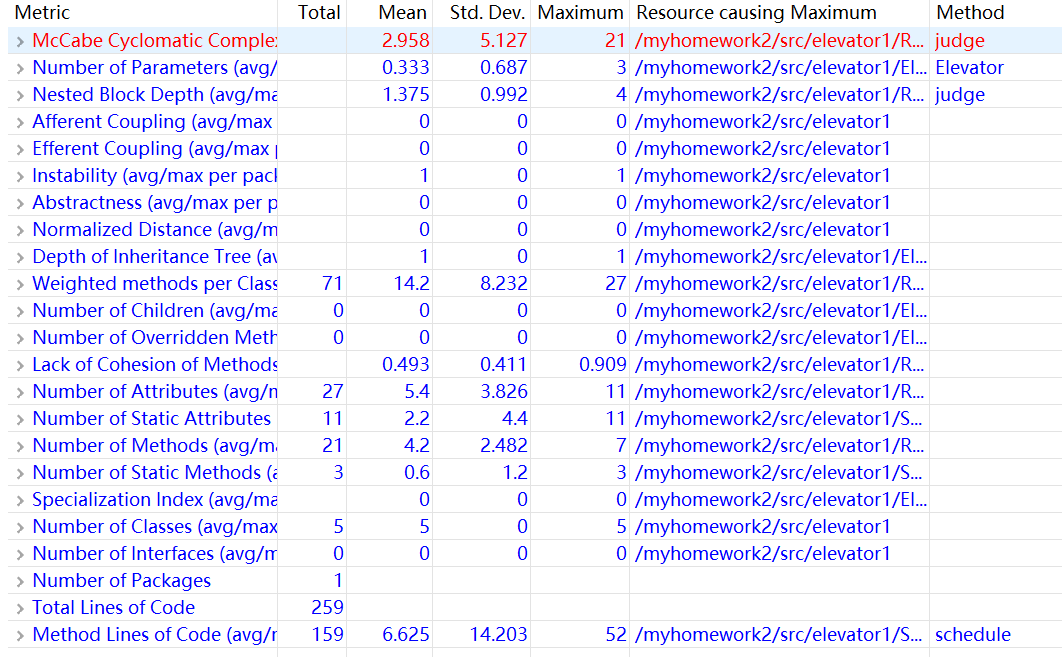
第二次作业中,总的来说为了实现一个电梯的功能,我采用了如下的思路:在RequestQueue类中读入每行字符串,将字符串传入Request类中判断输入要求的合法性正确性,如果错误做出相应的容错处理,如果正确则提取出必要的参数存入数组,在Scheduler类中统一调度计算。写到这里大家应该能发现Floor类和Elevator类并没有发挥任何的用处,就是摆在那里显得这很像一个面向对象式的编程。这一点在写第三次作业时有了改进,在写第三次作业时也对第二次作业的写法有了反思,在写第二次作业时为了写出功能正常的代码,我下意识的选择了较为熟悉的面向过程式编程,在每一个类中,函数式的算法占了较大的篇幅。但总体来说,除了没有认真阅读指导书导致可以带正号的输入判断错误,其他并无较大逻辑错误。
第三次作业:
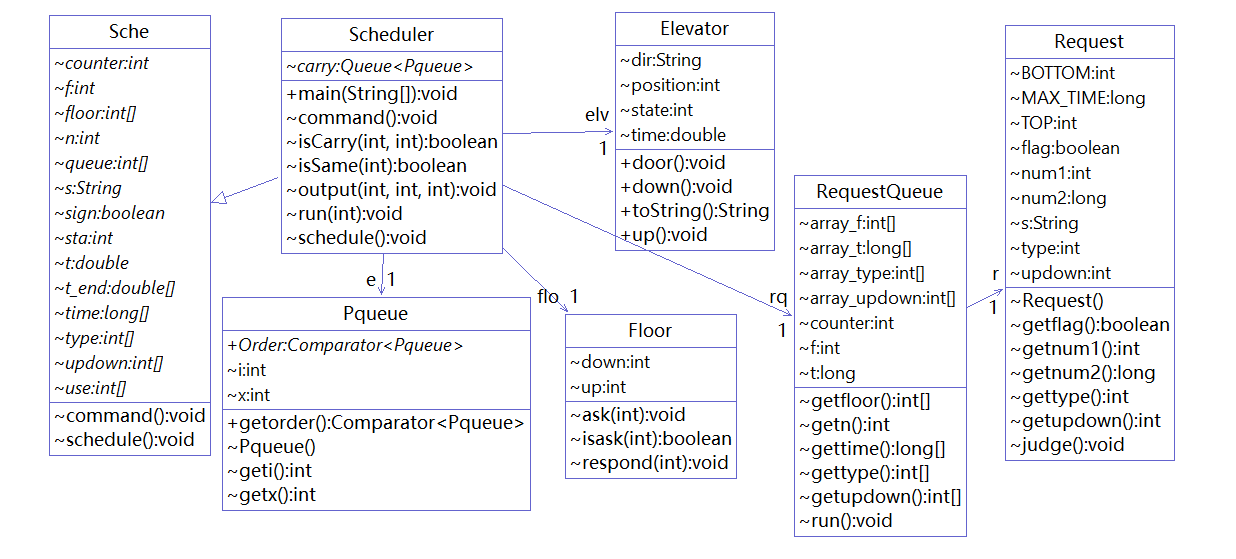
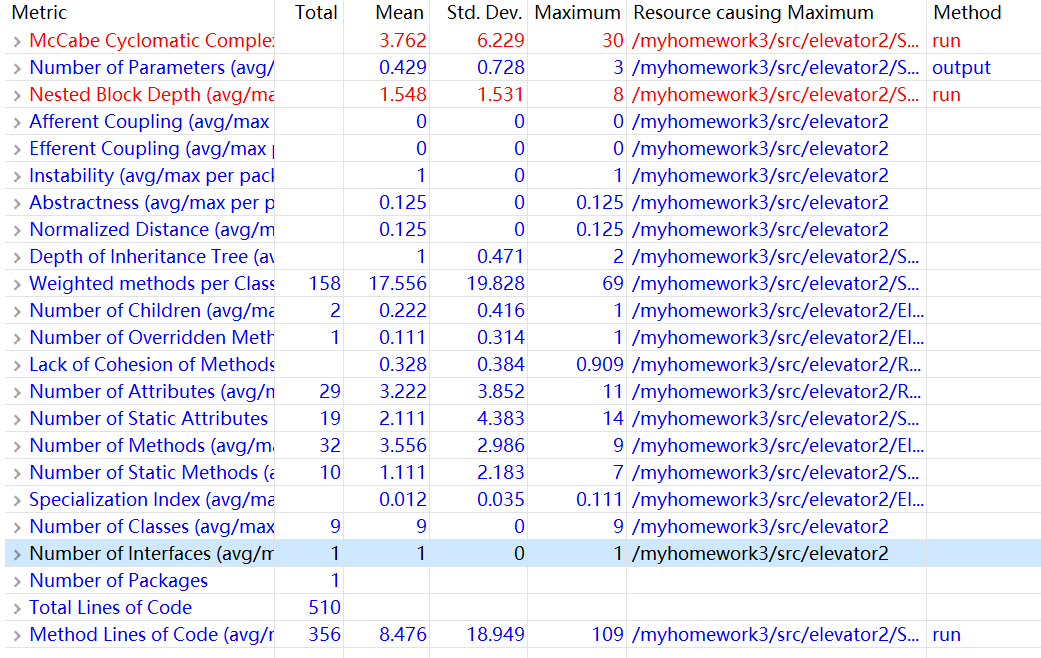
对于第三次作业,不得不说我做了很大的改进,Floor类和Elevator类总算发挥了应有的作用。这一次写代码的思路与第二次作业大同小异都是在RequestQueue类中读入每行字符串,将字符串传入Request类中判断输入要求的合法性正确性,如果错误做出相应的容错处理,如果正确则提取出必要的参数存入数组,在Scheduler类中统一调度计算。不同的是,在调度计算的过程中,我运用到了在电梯运动方法的接口基础上完成的Elevator类来进行对电梯的上下开关门的调度,重载 Object 的 toString 来获得电梯运行状态和时刻的观察。在调度算法上,使用继承机制,在第二次作业的 scheduler 代码基础上,重写(override)调度方法来实现捎带响应请求。一步步使自己的代码面向对象化。
对于这次作业的算法,我觉得我还有可以改进之处,对于判断捎带和判断同质,我一层循环套一层循环套一层循环,虽然保证了情况判断的全面性,但是使代码复杂度变得非常大,应该可以有更好的优化算法,之后可以研究一下。
2.分析自己程序的bug
在这三次作业中,我的代码逻辑未出现较大的错误,所以在公测和互测中未被检查出功能性错误。
但在第二次“单部傻瓜电梯”的作业中,由于忽略了指导书中输入数字可以有正号,导致我在Request类中的judge方法里用正则表达式判断输入的合法正确性时出了错误。
程序在功能上没有错误,但在运行性能上较差,没有用完全面向对象的方式实现,具体已在上一部分做出分析。
3.分析自己发现别人程序bug所采用的策略
(1)利用错误分支树构造简单测试样例,但容易漏掉bug。
(2)利用一些随机大数据进行覆盖性测试,如发现错误则进行进一步排查。
(3)大概理解对方代码的基本逻辑,判定有无逻辑上的错误。
(4)在代码无较大问题的情况下,重点关注边界问题,易混淆问题,自己写代码时de出的自己的bug和易出错部分,根据这些情况构造测试集进行测试。
4.心得体会
这里可以多啰嗦几句了。
完成一个完全面向对象式的编程,实现的功能还不能出错真的是一件很痛苦的事,尤其是在刚接触的时候,所以导致写着写着就面向过程了,笔者本人对此也表示很无奈。
要注意的点有很多了,这里把笔者的还能想起来的一些想法列在这里。
- 有时候老成的办法虽然比较有把握,但往往会使代码变得复杂,因此写代码的过程中一定要多查阅学习新的内容,说不定就发现更简单的办法了
- get set写多了代码真的显得很zz
- 类名方法名变量名一定要起好,方便别人方便自己
- debug要学会多种方法,print最想了解的数据,设置断点单步调试等都要会
- 最最最重要:写代码之前一定要好好读指导书,都明白都仔细了规则,对于自己readme的部分请不要简略的全部写进readme里
- 千万不要因为懒而少测试了自己的程序,一定要多测试,而且要各种各样的测试才能发现自己的程序有没有问题
- 写代码的过程中心路历程在坎坷也要冷静,不然反应过来的bug写一会就忘了要改啥或者改到心理崩溃越改越错就凉透了(微笑
- 有时候遇到困难可以和身边的同学适当交流启发思维,但绝对不要直接看或抄代码,不然就变成了禁锢思维