1. 首先,在浏览器里输入网址

2. 浏览器查找域名的IP地址
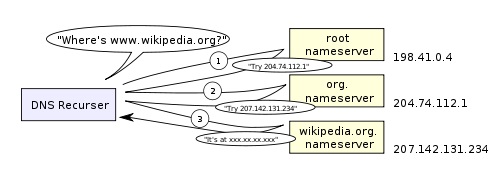
DNS查找过程如下:
浏览器缓存 – 浏览器会缓存DNS记录一段时间。 操作系统没有告诉浏览器储存DNS记录的时间,所以不同浏览器会储存各自固定的一个时间(2分钟到30分钟不等)。
系统缓存 –
如果在浏览器缓存里没有找到需要的记录,浏览器会做一个系统调用(windows里是gethostbyname)。这样便可获得系统缓存中的记录。
路由器缓存 – 接着,前面的查询请求发向路由器,它一般会有自己的DNS缓存。
ISP DNS 缓存 – 接下来要check的就是ISP缓存DNS的服务器。在这一般都能找到相应的缓存记录。
递归搜索 –
你的ISP的DNS服务器从跟域名服务器开始进行递归搜索,从.com顶级域名服务器到Facebook的域名服务器。一般DNS服务器的缓存中会有.com域名服务器中的域名,所以到顶级服务器的匹配过程不是那么必要了。
DNS返回多个IP时的解决方案:
1.负载平衡器:是以一个特定IP地址进行侦听并将网络请求转发到集群服务器上的硬件设备。
一些大型的站点一般都会使用这种昂贵的高性能负载平衡器。
2.
地理DNS:根据用户所处的地理位置,通过把域名映射到多个不同的IP地址提高可扩展性。这样不同的服务器不能够更新同步状态,但映射静态内容的话非常好。比如输入google.com在中国返回www.google.com.hk,在法国返回www.google.fr
3.
Anycast:是一个IP地址映射多个物理主机的路由技术。美中不足,Anycast与TCP协议适应的不是很好。大多数DNS服务器使用Anycast来获得高效低延迟的DNS查找。
3. 浏览器给web服务器发送一个HTTP请求

GET http://facebook.com/ HTTP/1.1
Accept: application/x-ms-application,
image/jpeg, application/xaml+xml, [...] User-Agent: Mozilla/4.0 (compatible; MSIE 8.0;
Windows NT 6.1; WOW64; [...] Accept-Encoding: gzip, deflate Connection: Keep-Alive Host: facebook.com
Cookie: datr=1265876274-[...];
locale=en_US; lsd=WW[...]; c_user=2101[...]
GET 这个请求定义了:
1)要读取的URL: “http://facebook.com/”。
2)浏览器自身定义 (User-Agent 头)
3)它希望接受什么类型的相应 (Accept and Accept-Encoding 头)
4)Connection头要求服务器为了后边的请求不要关闭TCP连接。
5)cookies是与跟踪一个网站状态相匹配的键值。这样cookies会存储登录用户名,服务器分配的密码和一些用户设置等。Cookies会以文本文档形式存储在客户机里,每次请求时发送给服务器。
4. facebook服务的永久重定向响应
HTTP/1.1 301 Moved Permanently
Cache-Control: private, no-store, no-cache, must-revalidate,
post-check=0, pre-check=0 Expires: Sat, 01 Jan 2000 00:00:00 GMT
Location: http://www.facebook.com/ P3P: CP="DSP LAW" Pragma:
no-cache Set-Cookie: made_write_conn=deleted; expires=Thu,
12-Feb-2009 05:09:50 GMT; path=/; domain=.facebook.com; httponly
Content-Type: text/html; charset=utf-8 X-Cnection: close Date: Fri,
12 Feb 2010 05:09:51 GMT Content-Length: 0
服务器给浏览器响应一个301永久重定向响应,这样浏览器就会访问“http://www.facebook.com/”
而非“http://facebook.com/”。
为什么服务器一定要重定向而不是直接发会用户想看的网页内容呢?
原因I:跟搜索引擎排名有关。你看,如果一个页面有两个地址,就像http://www.igoro.com/
和http://igoro.com/,搜索引擎会认为它们是两个网站,结果造成每一个的搜索链接都减少从而降低排名。
原因II:用不同的地址会造成缓存友好性变差。当一个页面有好几个名字时,它可能会在缓存里出现好几次。
5. 浏览器跟踪重定向地址

现在,浏览器知道了“http://www.facebook.com/”才是要访问的正确地址,所以它会发送另一个获取请求:
GET http://www.facebook.com/ HTTP/1.1 Accept:
application/x-ms-application, image/jpeg, application/xaml+xml,
[...] Accept-Language: en-US User-Agent: Mozilla/4.0 (compatible;
MSIE 8.0; Windows NT 6.1; WOW64; [...] Accept-Encoding: gzip,
deflate Connection: Keep-Alive Cookie: lsd=XW[...]; c_user=21[...];
x-referer=[...] Host: www.facebook.com
这就是为什么当你在浏览器中输入http://facebook.com/,之后会重定向到http://www.facebook.com/。
6. 服务器“处理”请求

web服务器软件(像IIS和阿帕奇)接收到HTTP请求,然后
1)执行相关请求处理,可能会读取或更新一些数据,并将数据存储在服务器上.
请求处理就是一个能够读懂请求并且能生成HTML来进行响应的程序(像ASP.NET,PHP,RUBY...)。
2)需求处理会生成一个HTML响应。
需求处理可以以映射网站地址结构的文件层次存储。像http://example.com/folder1/page1.aspx这个地址会映射
/httpdocs/folder1/page1.aspx这个文件。web服务器软件可以设置成为地址人工的对应请求处理,这样
page1.aspx的发布地址就可以是http://example.com/folder1/page1。
服务器要区分不同客户的请求,可以通过socket,每当服务期接收了一个客户端发来的连接请求,服务器与该客户创建一个socket,保证数据传输的通道,http请求可以在这个通道中传输。
7. 服务器发回一个HTML响应

HTTP/1.1 200 OK Cache-Control: private, no-store, no-cache,
must-revalidate, post-check=0, pre-check=0 Expires: Sat, 01 Jan
2000 00:00:00 GMT P3P: CP="DSP LAW" Pragma: no-cache Content-Encoding: gzip Content-Type: text/html; charset=utf-8 X-Cnection:
close Transfer-Encoding: chunked Date: Fri, 12 Feb 2010 09:05:55
GMT 2b3Tn@[...]
整个响应大小为35kB,其中大部分在整理后以blob类型传输。内容包括:
1)内容编码头告诉浏览器整个响应体用gzip算法进行压缩。解压blob块后,才可以看到期望的HTML:
2)是否缓存这个页面,如果缓存的话如何去做,有什么cookies要去设置(前面这个响应里没有这点)和隐私信息等等。
3)把Content-type设置为“text/html”,以让浏览器将该响应内容以HTML形式呈现,而不是以文件形式下载它。
8. 浏览器开始显示HTML
在浏览器没有完整接受全部HTML文档时,它就已经开始显示这个页面了:
9. 浏览器发送获取嵌入在HTML中的对象
在浏览器显示HTML时,它会注意到需要获取其他地址内容的标签。这时,浏览器会发送一个获取请求来重新获得这些文件。
下面是几个我们访问facebook.com时需要重获取的几个URL:
图片
http://upload.chinaz.com/2013/0228/1362014211396.gif
http://upload.chinaz.com//
…
CSS 式样表
http://static.ak.fbcdn.net/rsrc.php/z448Z/hash/2plh8s4n.css
http://static.ak.fbcdn.net/rsrc.php/zANE1/hash/cvtutcee.css
…
JavaScript 文件
http://static.ak.fbcdn.net/rsrc.php/zEMOA/hash/c8yzb6ub.js
http://static.ak.fbcdn.net/rsrc.php/z6R9L/hash/cq2lgbs8.js
…
这些地址都要经历一个和HTML读取类似的过程。所以浏览器会在DNS中查找这些域名,发送请求,重定向等等...
但不像动态页面那样,静态文件会允许浏览器对其进行缓存。有的文件可能会不需要与服务器通讯,而从缓存中直接读取。服务器的响应中包含了静态文件保存的期限信息,所以浏览器知道要把它们缓存多长时间。
10. 浏览器发送异步(AJAX)请求
以
Facebook聊天功能为例,它会持续与服务器保持联系来及时更新你那些亮亮灰灰的好友状态。为了更新这些头像亮着的好友状态,在浏览器中执行的
JavaScript代码会给服务器发送异步请求。这个异步请求发送给特定的地址http://www.facebook.com/ajax/chat/buddy_list.php来获取你好友里哪个在线的状态信息。
提起这个模式,就必须要讲讲"AJAX"-- “异步JavaScript 和
XML”,虽然服务器为什么用XML格式来进行响应也没有个一清二白的原因。再举个例子吧,对于异步请求,Facebook会返回一些JavaScript的代码片段。
除了其他,fiddler这个工具能够让你看到浏览器发送的异步请求。事实上,你不仅可以被动的作为这些请求的看客,还能主动出击修改和重新发送它们。AJAX请求这么容易被蒙,可着实让那些计分的在线游戏开发者们郁闷的了。
Facebook聊天功能提供了关于AJAX一个有意思的问题案例:把数据从服务器端推送到客户端。因为HTTP是一个请求-响应协议,所以聊天服务器不能把新消息发给客户。取而代之的是客户端不得不隔几秒就轮询下服务器端看自己有没有新消息,称作“轮询”。