0 简介
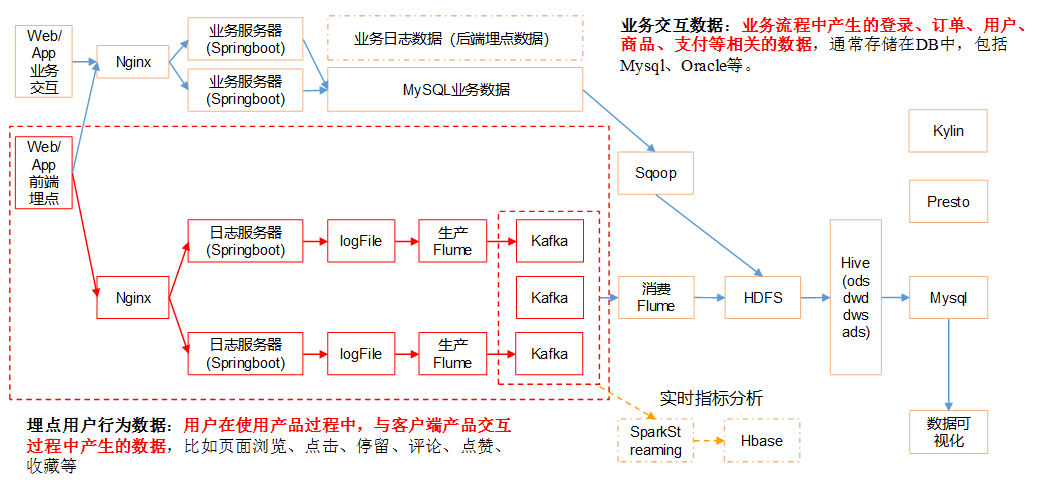
1 Kafka集群安装
集群规划:
|
服务器hadoop102 |
服务器hadoop103 |
服务器hadoop104 |
|
|
Kafka |
Kafka |
Kafka |
Kafka |
2 Kafka集群启动停止脚本
1)在/home/atguigu/bin目录下创建脚本kf.sh
[atguigu@hadoop102 bin]$ vim kf.sh
在脚本中填写如下内容
#! /bin/bash case $1 in "start"){ for i in hadoop102 hadoop103 hadoop104 do echo " --------启动 $i Kafka-------" # 用于KafkaManager监控 ssh $i "export JMX_PORT=9988 && /opt/module/kafka/bin/kafka-server-start.sh -daemon /opt/module/kafka/config/server.properties " done };; "stop"){ for i in hadoop102 hadoop103 hadoop104 do echo " --------停止 $i Kafka-------" ssh $i "/opt/module/kafka/bin/kafka-server-stop.sh stop" done };; esac
说明:启动Kafka时要先开启JMX端口,是用于后续KafkaManager监控。
2)增加脚本执行权限
[atguigu@hadoop102 bin]$ chmod 777 kf.sh
3)kf集群启动脚本
[atguigu@hadoop102 module]$ kf.sh start
4)kf集群停止脚本
[atguigu@hadoop102 module]$ kf.sh stop
3 查看Kafka Topic列表
[atguigu@hadoop102 kafka]$ bin/kafka-topics.sh --zookeeper hadoop102:2181 --list
4 创建Kafka Topic
进入到/opt/module/kafka/目录下分别创建:启动日志主题、事件日志主题。
1)创建启动日志主题
[atguigu@hadoop102 kafka]$ bin/kafka-topics.sh --zookeeper hadoop102:2181,hadoop103:2181,hadoop104:2181 --create --replication-factor 1 --partitions 1 --topic topic_start
2)创建事件日志主题
[atguigu@hadoop102 kafka]$ bin/kafka-topics.sh --zookeeper hadoop102:2181,hadoop103:2181,hadoop104:2181 --create --replication-factor 1 --partitions 1 --topic topic_event
5 删除Kafka Topic
1)删除启动日志主题
[atguigu@hadoop102 kafka]$ bin/kafka-topics.sh --delete --zookeeper hadoop102:2181,hadoop103:2181,hadoop104:2181 --topic topic_start
2)删除事件日志主题
[atguigu@hadoop102 kafka]$ bin/kafka-topics.sh --delete --zookeeper hadoop102:2181,hadoop103:2181,hadoop104:2181 --topic topic_event
6 Kafka生产消息
[atguigu@hadoop102 kafka]$ bin/kafka-console-producer.sh --broker-list hadoop102:9092 --topic topic_start >hello world >atguigu atguigu
7 Kafka消费消息
[atguigu@hadoop102 kafka]$ bin/kafka-console-consumer.sh
--bootstrap-server hadoop102:9092 --from-beginning --topic topic_start
--from-beginning:会把主题中以往所有的数据都读取出来。根据业务场景选择是否增加该配置。
8 查看Kafka Topic详情
[atguigu@hadoop102 kafka]$ bin/kafka-topics.sh --zookeeper hadoop102:2181
--describe --topic topic_start
9 项目经验之Kafka压力测试
1)Kafka压测
用Kafka官方自带的脚本,对Kafka进行压测。Kafka压测时,可以查看到哪个地方出现了瓶颈(CPU,内存,网络IO)。一般都是网络IO达到瓶颈。
kafka-consumer-perf-test.sh
kafka-producer-perf-test.sh
2)Kafka Producer压力测试
(1)在/opt/module/kafka/bin目录下面有这两个文件。我们来测试一下
[atguigu@hadoop102 kafka]$ bin/kafka-producer-perf-test.sh --topic test --record-size 100 --num-records 100000 --throughput 1000 --producer-props bootstrap.servers=hadoop102:9092,hadoop103:9092,hadoop104:9092
说明:record-size是一条信息有多大,单位是字节。num-records是总共发送多少条信息。throughput 是每秒多少条信息。
(2)Kafka会打印下面的信息
5000 records sent, 999.4 records/sec (0.10 MB/sec), 1.9 ms avg latency, 254.0 max latency. 5002 records sent, 1000.4 records/sec (0.10 MB/sec), 0.7 ms avg latency, 12.0 max latency. 5001 records sent, 1000.0 records/sec (0.10 MB/sec), 0.8 ms avg latency, 4.0 max latency. 5000 records sent, 1000.0 records/sec (0.10 MB/sec), 0.7 ms avg latency, 3.0 max latency. 5000 records sent, 1000.0 records/sec (0.10 MB/sec), 0.8 ms avg latency, 5.0 max latency.
参数解析:本例中一共写入10w条消息,每秒向Kafka写入了0.10MB的数据,平均是1000条消息/秒,每次写入的平均延迟为0.8毫秒,最大的延迟为254毫秒。
3)Kafka Consumer压力测试
Consumer的测试,如果这四个指标(IO,CPU,内存,网络)都不能改变,考虑增加分区数来提升性能。
[atguigu@hadoop102 kafka]$
bin/kafka-console-consumer.sh --bootstrap-server 192.168.1.122:2181 --topic wordsendertest --from-beginning
参数说明:
--zookeeper 指定zookeeper的链接信息
--topic 指定topic的名称
--fetch-size 指定每次fetch的数据的大小
--messages 总共要消费的消息个数
测试结果说明:
start.time, end.time, data.consumed.in.MB, MB.sec, data.consumed.in.nMsg, nMsg.sec
2019-02-19 20:29:07:566, 2019-02-19 20:29:12:170, 9.5368, 2.0714, 100010, 21722.4153
开始测试时间,测试结束数据,最大吞吐率9.5368MB/s,平均每秒消费2.0714MB/s,最大每秒消费100010条,平均每秒消费21722.4153条。
10 项目经验之Kafka机器数量计算
Kafka机器数量(经验公式)=2*(峰值生产速度*副本数/100)+1
先拿到峰值生产速度,再根据设定的副本数,就能预估出需要部署Kafka的数量。
比如我们的峰值生产速度是50M/s。副本数为2。
Kafka机器数量=2*(50*2/100)+ 1=3台