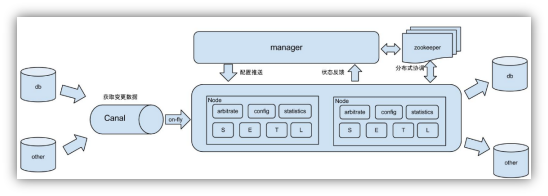
1 什么是 canal
阿里巴巴B2B公司,因为业务的特性,卖家主要集中在国内,买家主要集中在国外,所以衍生出了杭州和美国异地机房的需求,从2010年开始,阿里系公司开始逐步的尝试基于数据库的日志解析,获取增量变更进行同步,由此衍生出了增量订阅&消费的业务。
canal是用java开发的基于数据库增量日志解析,提供增量数据订阅&消费的中间件。目前,canal主要支持了MySQL的binlog解析,解析完成后才利用canal client 用来处理获得的相关数据。(数据库同步需要阿里的otter中间件,基于canal)。
2 使用场景
1)原始场景: 阿里otter中间件的一部分
otter是阿里用于进行异地数据库之间的同步框架,canal是其中一部分。
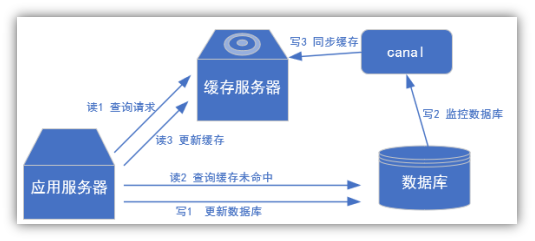
2) 常见场景1:更新缓存
3) 场景2:抓取业务数据新增变化表,用于制作拉链表。
4) **场景3:抓取业务表的新增变化数据,用于制作实时统计。
3 canal的工作原理
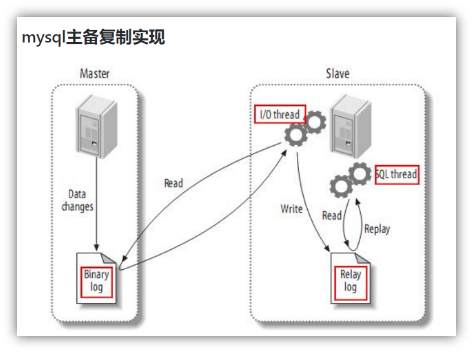
复制过程分成三步:
1) Master主库将改变记录,写到二进制日志(binary log)中
2) Slave从库向mysql master发送dump协议,将master主库的binary log events拷贝到它的中继日志(relay log);
3) Slave从库读取并重做中继日志中的事件,将改变的数据同步到自己的数据库。
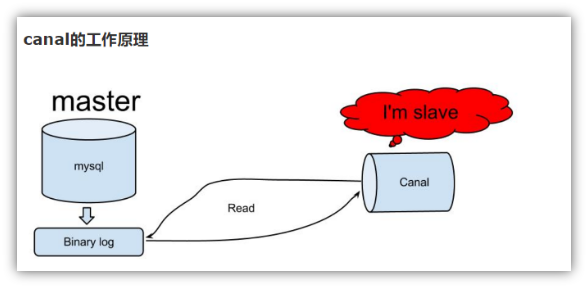
canal的工作原理很简单,就是把自己伪装成slave,假装从master复制数据。
4 mysql的binlog
4.1 什么是binlog
MySQL的二进制日志可以说是MySQL最重要的日志了,它记录了所有的DDL和DML(除了数据查询语句)语句,以事件形式记录,还包含语句所执行的消耗的时间,MySQL的二进制日志是事务安全型的。
一般来说开启二进制日志大概会有1%的性能损耗。二进制有两个最重要的使用场景:
其一:MySQL Replication在Master端开启binlog,Mster把它的二进制日志传递给slaves来达到master-slave数据一致的目的。
其二:自然就是数据恢复了,通过使用mysqlbinlog工具来使恢复数据。
二进制日志包括两类文件:二进制日志索引文件(文件名后缀为.index)用于记录所有的二进制文件,二进制日志文件(文件名后缀为.00000*)记录数据库所有的DDL和DML(除了数据查询语句)语句事件。
4.2 binlog的开启
在mysql的配置文件(Linux: /etc/my.cnf , Windows: my.ini)下,修改配置
在[mysqld] 区块
设置/添加
log-bin=mysql-bin
这个表示binlog日志的前缀是mysql-bin ,以后生成的日志文件就是 mysql-bin.123456 的文件后面的数字按顺序生成。
每次mysql重启或者到达单个文件大小的阈值时,新生一个文件,按顺序编号。
4.3 binlog的分类设置
mysql binlog的格式,那就是有三种,分别是STATEMENT,MIXED,ROW。
在配置文件中可以选择配置
binlog_format=row
区别:
1) statement
语句级,binlog会记录每次一执行写操作的语句。
相对row模式节省空间,但是可能产生不一致性,比如
update tt set create_date=now()
如果用binlog日志进行恢复,由于执行时间不同可能产生的数据就不同。
优点: 节省空间
缺点: 有可能造成数据不一致。
2) row
行级, binlog会记录每次操作后每行记录的变化。
优点:保持数据的绝对一致性。因为不管sql是什么,引用了什么函数,他只记录执行后的效果。
缺点:占用较大空间。
3) mixed
statement的升级版,一定程度上解决了,因为一些情况而造成的statement模式不一致问题
在某些情况下譬如:
当函数中包含 UUID() 时;
包含 AUTO_INCREMENT 字段的表被更新时;
执行 INSERT DELAYED 语句时;
用 UDF 时;
会按照 ROW的方式进行处理
优点:节省空间,同时兼顾了一定的一致性。
缺点:还有些极个别情况依旧会造成不一致,另外statement和mixed对于需要对binlog的监控的情况都不方便。