版本说明:
- Flink 1.11.2
- Kafka 2.4.0
- Hive 3.1.2
- Hadoop 3.1.3
1 hive
安装hive,使用mysql做为元数据存储
1.2 hive-site.xml 配置 (版本3.1.2)

<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://hadoop102:3306/metastore?createDatabaseIfNotExist=true</value>
<description>JDBC connect string for a JDBC metastore</description>
</property>
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.cj.jdbc.Driver</value>
<description>Driver class name for a JDBC metastore</description>
</property>
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>root</value>
<description>username to use against metastore database</description>
</property>
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>123456</value>
<description>password to use against metastore database</description>
</property>
<property>
<name>hive.metastore.warehouse.dir</name>
<value>/user/hive/warehouse</value>
<description>location of default database for the warehouse</description>
</property>
<property>
<name>hive.cli.print.header</name>
<value>true</value>
</property>
<property>
<name>hive.cli.print.current.db</name>
<value>true</value>
</property>
<property>
<name>hive.cli.print.current.db</name>
<value>true</value>
</property>
<property>
<name>hive.metastore.schema.verification</name>
<value>false</value>
</property>
<property>
<name>hive.server2.thrift.bind.host</name>
<value>192.168.1.122</value>
</property>
<property>
<name>hive.metastore.event.db.notification.api.auth</name>
<value>false</value>
</property>
<property>
<name>datanucleus.schema.autoCreateAll</name>
<value>true</value>
</property>
<property>
<name>hive.metastore.uris</name>
<value>thrift://localhost:9083</value> <!-- metastore 在的pc的ip-->
</property>
</configuration>
2 flink(版本1.10.2)
2.1 配置conf/sql-client-hive.yaml
################################################################################
# Licensed to the Apache Software Foundation (ASF) under one
# or more contributor license agreements. See the NOTICE file
# distributed with this work for additional information
# regarding copyright ownership. The ASF licenses this file
# to you under the Apache License, Version 2.0 (the
# "License"); you may not use this file except in compliance
# with the License. You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
################################################################################
# This file defines the default environment for Flink's SQL Client.
# Defaults might be overwritten by a session specific environment.
# See the Table API & SQL documentation for details about supported properties.
#==============================================================================
# Tables
#==============================================================================
# Define tables here such as sources, sinks, views, or temporal tables.
#tables: [] # empty list
# A typical table source definition looks like:
# - name: ...
# type: source-table
# connector: ...
# format: ...
# schema: ...
# A typical view definition looks like:
# - name: ...
# type: view
# query: "SELECT ..."
# A typical temporal table definition looks like:
# - name: ...
# type: temporal-table
# history-table: ...
# time-attribute: ...
# primary-key: ...
#==============================================================================
# User-defined functions
#==============================================================================
# Define scalar, aggregate, or table functions here.
#functions: [] # empty list
# A typical function definition looks like:
# - name: ...
# from: class
# class: ...
# constructor: ...
#==============================================================================
# Catalogs
#==============================================================================
# Define catalogs here.
catalogs: # empty list
# A typical catalog definition looks like:
- name: myhive # 名字随意取
type: hive
hive-conf-dir: /opt/module/hive/conf # hive-site.xml 所在的路径
# default-database: ...
#==============================================================================
# Modules
#==============================================================================
# Define modules here.
#modules: # note the following modules will be of the order they are specified
# - name: core
# type: core
#==============================================================================
# Execution properties
#==============================================================================
# Properties that change the fundamental execution behavior of a table program.
execution:
# select the implementation responsible for planning table programs
# possible values are 'blink' (used by default) or 'old'
planner: blink
# 'batch' or 'streaming' execution
type: streaming
# allow 'event-time' or only 'processing-time' in sources
time-characteristic: event-time
# interval in ms for emitting periodic watermarks
periodic-watermarks-interval: 200
# 'changelog' or 'table' presentation of results
result-mode: table
# maximum number of maintained rows in 'table' presentation of results
max-table-result-rows: 1000000
# parallelism of the program
parallelism: 1
# maximum parallelism
max-parallelism: 128
# minimum idle state retention in ms
min-idle-state-retention: 0
# maximum idle state retention in ms
max-idle-state-retention: 0
# current catalog ('default_catalog' by default)
current-catalog: myhive
# current database of the current catalog (default database of the catalog by default)
current-database: hive
# controls how table programs are restarted in case of a failures
restart-strategy:
# strategy type
# possible values are "fixed-delay", "failure-rate", "none", or "fallback" (default)
type: fallback
#==============================================================================
# Configuration options
#==============================================================================
# Configuration options for adjusting and tuning table programs.
# A full list of options and their default values can be found
# on the dedicated "Configuration" web page.
# A configuration can look like:
# configuration:
# table.exec.spill-compression.enabled: true
# table.exec.spill-compression.block-size: 128kb
# table.optimizer.join-reorder-enabled: true
#==============================================================================
# Deployment properties
#==============================================================================
# Properties that describe the cluster to which table programs are submitted to.
deployment:
# general cluster communication timeout in ms
response-timeout: 5000
# (optional) address from cluster to gateway
gateway-address: ""
# (optional) port from cluster to gateway
gateway-port: 0
2.2 配置jar包
/flink-1.10.2
/lib
// Flink's Hive connector.Contains flink-hadoop-compatibility and flink-orc jars
flink-connector-hive_2.11-1.10.2.jar
// Hadoop dependencies
// You can pick a pre-built Hadoop uber jar provided by Flink, alternatively
// you can use your own hadoop jars. Either way, make sure it's compatible with your Hadoop
// cluster and the Hive version you're using.
flink-shaded-hadoop-2-uber-2.7.5-8.0.jar
// Hive dependencies
hive-exec-2.3.4.jar
hive-metastore-3.1.2.jar
libfb303-0.9.3.jar
// kafka dependencies
flink-sql-connector-kafka_2.11-1.11.2.jar
后三个JAR包都是Hive自带的,可以在${HIVE_HOME}/lib目录下找到。前两个可以通过阿里云Maven搜索GAV找到并手动下载(groupId都是org.apache.flink)。
注意:要将lib包分发到集群中其他flink机器上
3 启动
3.1 启动hadoop集群
省略。。。
3.2 启动Hive meatastore
hive --service metastore &
3.3 启动Flink
$FLINK_HOME/bin/start-cluster.sh
3.4 启动 Flink SQL Client
atguigu@hadoop102:/opt/module/flink$ bin/sql-client.sh embedded -d conf/sql-client-hive.yaml -l lib/
3.5 在Flink SQL Client中创建Hive表,指定数据源为Kafka
CREATE TABLE student( id INT, name STRING, password STRING, age INT, ts BIGINT, eventTime AS TO_TIMESTAMP(FROM_UNIXTIME(ts / 1000, 'yyyy-MM-dd HH:mm:ss')), -- 事件时间 WATERMARK FOR eventTime AS eventTime - INTERVAL '10' SECOND -- 水印 ) WITH ( 'connector.type' = 'kafka', 'connector.version' = 'universal', -- 指定Kafka连接器版本,不能为2.4.0,必须为universal,否则会报错 'connector.topic' = 'student', -- 指定消费的topic 'connector.startup-mode' = 'latest-offset', -- 指定起始offset位置 'connector.properties.zookeeper.connect' = 'hadoop000:2181', 'connector.properties.bootstrap.servers' = 'hadooop000:9092', 'connector.properties.group.id' = 'student_1', 'format.type' = 'json', 'format.derive-schema' = 'true', -- 由表schema自动推导解析JSON 'update-mode' = 'append' );
3.6 启动Kafka,发送数据
$KAFKA_HOME/bin/kafka-console-producer.sh --broker-list hadoop000:9092 --topic student
{"id":12, "name":"kevin", "password":"wong", "age":22, "ts":1603769073}
3.7 通过Flink SQL Client查询表中的数据
select * from student
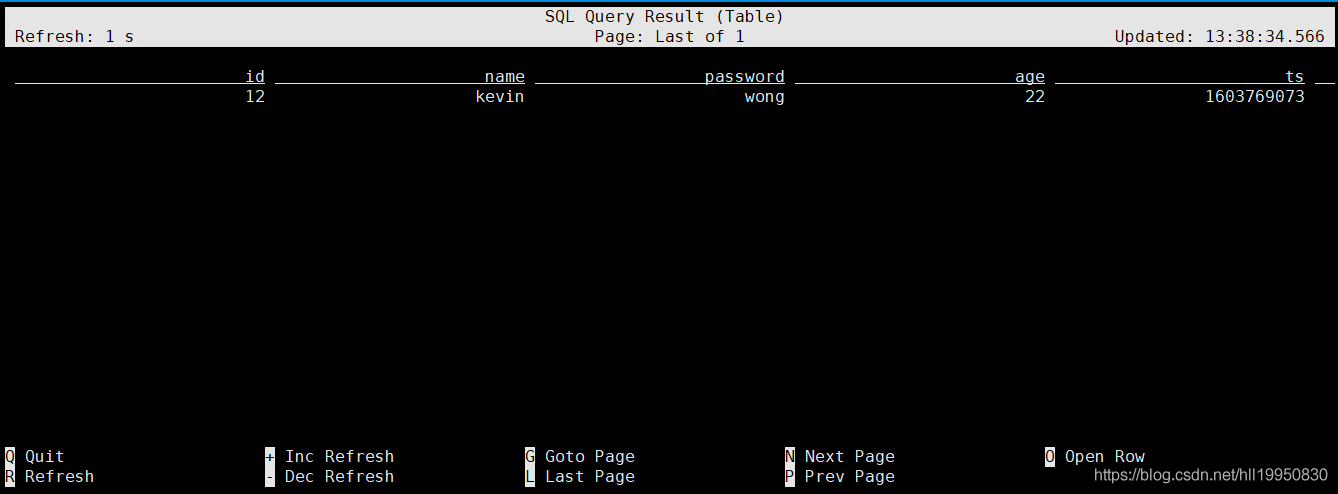
参考:https://blog.csdn.net/hll19950830/article/details/109308055
错误参考:
java.lang.ClassNotFoundException: org.apache.flink.streaming.connectors.kafka.FlinkKafkaConsumer
https://blog.csdn.net/qq_31866793/article/details/107487858