来源:https://mp.weixin.qq.com/s/52qSPOxX1F-o4sSwF0rgaQ
一、背景
FLink Job端到端延迟是一个重要的指标,用来衡量Flink任务的整体性能和响应延迟(大部分流式应用,要求低延迟特性)。通过流处理引擎竞品对比,我们发现大部分流计算引擎产品,都在告警监控页面,集成了全链路时延指标展示。一些低延时的处理场景,例如用于登陆、用户下单规则检测,实时预测场景,需要一个可度量的Metric指标,来实时观测、监控集群全链路时延情况。
二、源码分析来源
1、本文的源码分析基于FLink社区issue FLINK-3660,以及issue对应的pr源码pull-2386,另外,个人也新增了实现源码的说明。2、其pr源码中只涉及到了部分全链路时延实现代码,因此,我在文章中总结了:
-
Source到Sink处理Latency Marker源码
-
LatencyMarksEmitter 提交时延标记类
-
LatencyStats(时延直方图Metric实现)源码
-
时延测量–整体架构图
三、腾讯Oceanus监控指标参考
如下图,红色框线对应的数据延时,即我们描述的指标
四、Flink LatencyMarker实现思路
在webinterface中,加入流式job的端到端延迟是一个重要特性。因此,FLink社区最初的想法是在每个记录的source上附加一个摄取时间( ingestion -time)时间戳。然而,这为不使用monitor feature(监控功能)的用户,带来了额外开销(每个元素+每个元素上的System.currentTimeMilis()需要8个字节)。因此,FLink社区最后决定,通过定期发送特殊事件来实现此功能,类似于通过拓扑发送水印watermark。这些特殊事件(LatencyMarker)在source上以可配置发送间隔,并由任务Task转发。Sink最后接收到LatencyMarks后,将比较LatencyMarker的时间戳与当前系统时间,以确定延迟。LatencyMarker不会增加作业的延迟,但是LatencyMarker与常规记录类似,可以被delay阻塞(例如反压情况),因此LatencyMarker的延迟与Record延迟近似。上述建议期望所有任务管理器TaskManager上的时钟是同步的。否则,测量的延迟也包括TaskManager时钟之间的偏移。后续,我们可以尝试通过使用JobManager作为计时服务中心(central timing service)来缓解这个问题。taskmanager将定期查询JM的当前时间,以确定其时钟的偏移量。这个偏移量仍然包括TM和JM之间的网络延迟,但是仍然比较好的测量时延。
五、Flink LatencyMarker实现源码
本章节对应到pr源码pull-2386的实现,这里简要说明。
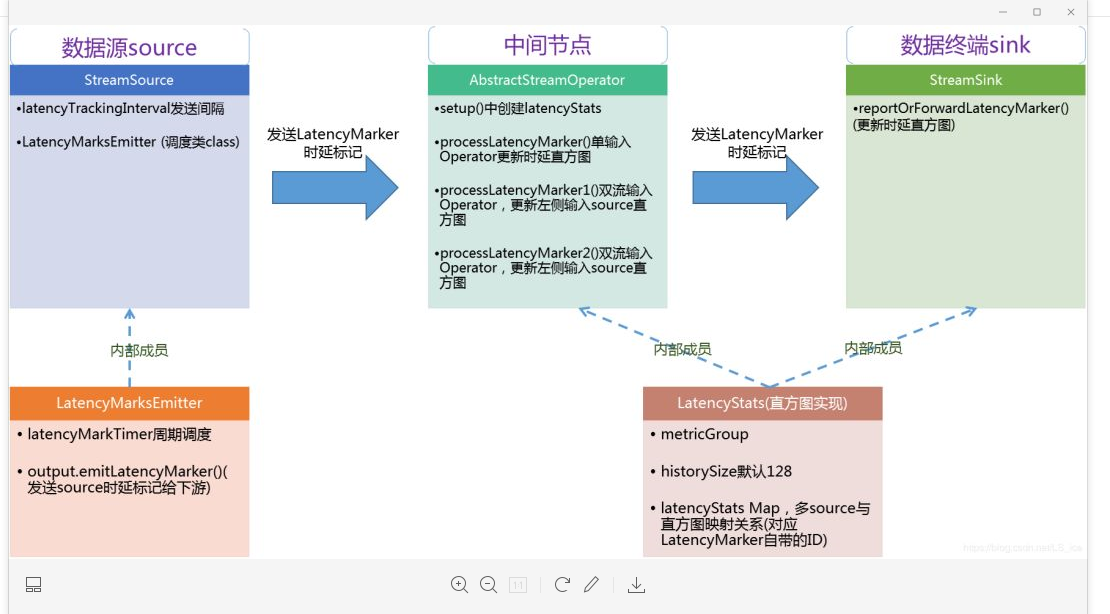
Flink源码中,引入了一个新的StreamElement,称为LatencyMarker。
与水印类似,LatencyMarker按配置的间隔从源发出。这个时间间隔的默认值是0毫秒,即不触发 (配置项在ExecutionConfig#latencyTrackingInterval,名称metrics.latency.interval),例如可以配置成2000毫秒触发一次LatencyMarker发送。
LatencyMarker不能“多于”常规元素。这确保了测量的延迟接近于常规流元素的端到端延迟。
常规操作符Operator(不包括那些参与迭代的Operator)如果不是sink,就会转发延迟标记LatencyMarker。具有多个输出channel的Operator,随机选择一个channel通道,将LatencyMarker发送给它。这可以确保每个LatencyMarker标记在系统中只存在一次,并且重新分区步骤不会导致传输的LatencyMarker数量激增。
public class RecordWriterOutput{ @Override public void emitLatencyMarker(LatencyMarker latencyMarker) { serializationDelegate.setInstance(latencyMarker); try { // 内部实现了随机选择通道 recordWriter.randomEmit(serializationDelegate); } catch (Exception e) { throw new RuntimeException(e.getMessage(), e); } } }
上述RecordWriterOutput#emitLatencyMarker()会被StreamSource、AbstractStreamOperator调用,分别实现source和中间operator的延迟标记下发
如果操作符Operator是Sink,它将维护每个已知source实例的最后512个LatencyMarker信息。每个已知source的最小/最大/平均值/p50/p95/p99时延,在sink的LatencyStats对象中,进行汇总(如果没有任何输出的Operator,就是是sink)。此pr代码,不会在web ui中显示延迟。此外,目前还没有确保系统时钟同步的机制,因此如果硬件时钟不正确,则延迟测量将不准确。
六、总结说明
1、LatencyMarker不参与window、MiniBatch的缓存计时,直接被中间Operator下发。
2、Metric路径:TaskManagerJobMetricGroup/operator_id/operator_subtask_index/latency
3、每个中间Operator、以及Sink都会统计自己与Source节点的链路延迟,我们在监控页面,一般展示Source至Sink链路延迟。
4、延迟粒度细分到Task,可以用来排查哪台机器的Task时延偏高,进行对比和运维排查。
5、从实现原理来看,发送时延标记间隔配置大一些(例如20秒一次),一般不会影响系统处理业务数据的性能。