原文:https://blog.csdn.net/rlnlo2pnefx9c/article/details/108288956
本节题目为:亿级数据从 MySQL 到 Hbase 的三种同步方案与实践,首先需要了解如何快速插入MySQL。
那么MySQL数据插入将会从以下几个方法入手:
-
load data infile -
Python 单条插入
-
Python 多线程插入
当然也可以使用其他语言进行实现!!!
下面来逐步谈谈数据插入!
数据插入之前,需要了解我们的数据,先来看一下数据字段描述:
数据以ASCII文本表示,以逗号为分隔符,以回车换行符(0x0D 0x0A)结尾。数据项及顺序:车辆标识、触发事件、运营状态、GPS时间、GPS经度、GPS纬度,、GPS速度、GPS方向、GPS状态 车辆标识:6个字符 触发事件:0=变空车,1=变载客,2=设防,3=撤防,4=其它 运营状态:0=空车,1=载客,2=驻车,3=停运,4=其它 GPS时间:格式yyyymmddhhnnss,北京时间 GPS经度:格式ddd.ddddddd,以度为单位。 GPS纬度:格式dd.ddddddd,以度为单位。 GPS速度:格式ddd,取值000-255内整数,以公里/小时为单位。 GPS方位:格式ddd,取值000-360内整数,以度为单位。 GPS状态:0=无效,1=有效 结束串:回车符+换行符
数据举例:
154747,4,2,20121130001607,116.6999512,39.9006233,0,128,1
078245,4,0,20121130001610,116.3590469,39.9909782,0,92,1
194086,4,1,20121130001610,116.5017776,40.0047951,25,220,1
那么只需要将上述的数据字段与数据对上就行了,一行为一条数据记录。
首先编写创建数据库与表命令:
create database loaddb; CREATE TABLE loadTable(id int primary key not null auto_increment, carflag VARCHAR(6),touchevent CHAR(1),opstatus CHAR(1),gpstime DATETIME, gpslongitude DECIMAL(10,7),gpslatitude DECIMAL(9,7),gpsspeed TINYINT, gpsorientation SMALLINT,gpsstatus CHAR(1))engine=MyISAM;
注意:上述选择了MyISAM引擎是因为load命令使用的时候,保证数据插入的效率!
3.1 load data infile
load data infile在导入大数据场景下非常的快!具体的说明后面会在比较的时候详细说,这里说一下使用语法,如下:
load data local infile "/home/light/mysql/gps1.txt" into table loadTable fields terminated by ',' lines terminated by " " (carflag, touchevent, opstatus,gpstime,gpslongitude,gpslatitude,gpsspeed,gpsorientation,gpsstatus);
在使用这个命令的时候,是在MySQL的clinet端使用,登陆后敲这个命令即可!在数据字段描述中大家会看到几个关键点:以逗号为分隔符,以回车换行符,对应于上述代码是:
fields terminated by ',' lines terminated by " "
注意:更换自己的数据集路径!
3.2 Python 批量插入
Python单条插入使用的是pymysql库。下面是部分代码,完整代码见:
批量提交源码
with open('/home/light/mysql/gps1.txt', 'r') as fp: for line in fp: ... ... ... count += 1 if count and count%70000==0: # 执行多行插入,executemany(sql语句,数据(需一个元组类型)) self.cur.executemany(sql, data_list) # 提交数据,必须提交,不然数据不会保存 self.conn.commit() data_list = [] print("提交了:" + str(count) + "条数据") if data_list: # 执行多行插入,executemany(sql语句,数据(需一个元组类型)) self.cur.executemany(sql, data_list) # 提交数据,必须提交,不然数据不会保存 self.conn.commit() print("提交了:" + str(count) + "条数据") self.cur.close() # 关闭游标 self.conn.close() # 关闭pymysql连接
上述有个关键点需要说明一下:
(1)使用executemany而非execute,这个提交速度要快!(2)使用批量插入,而非单条插入提交,这样会提升效率!
3.3 Python 多线程插入
原始数据为一个gps1.txt文件,这个数据太大,如果直接使用多线程插入,不太方便,所以先使用文件切分方法,然后进行多线程的插入。
关于文件切分,可以点击这里:文件切分源码。
Python中使用多线程源码
def multicore(self): file_list = [1,2324,4648,6972,9298] m1 = mp.Process(target=self.run, args=(file_list[0],file_list[1],'m1',)) m2 = mp.Process(target=self.run, args=(file_list[1]+1,file_list[2],'m2',)) m3 = mp.Process(target=self.run, args=(file_list[2]+1,file_list[3],'m3',)) m4 = mp.Process(target=self.run, args=(file_list[3]+1,file_list[4],'m4',)) m1.start() m2.start() m3.start() m4.start() m1.join() m2.join() m3.join() m4.join()
具体插入思路是使用四个线程分别读取每个区间段的数据,然后再对数据进行批量插入!如果这一块不懂的伙伴,欢迎留言哈~
3.4 MySQL数据导入方法对比
★load命令与普通的insert区别
”
| 相同点 | 不同点 |
|---|---|
| 两者都是通过读取本地txt文件,按照相同的分隔来读取进行插入。 | 程序插入法实质为insert语句间接执行。load data设计用于在单个操作中大量加载表格数据。 |
★效率比较
”
两者耗时如下:
第一种:load data (这里截取的是Innodb引擎表的插入结果,当使用MyISAM时,会比现在还快!)
enter image description here
用时1h11分。
第二种:程序插入法(这里只截取了批量插入的!)
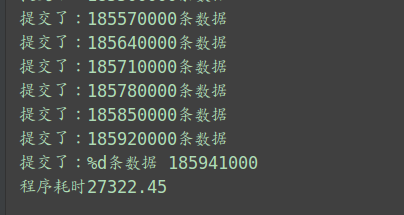
用时:27322.45/36=7.58h
上述对比可知,load data效率非常高,原因在于使用的是load data infile方式,而第二种则为传统的insert方式。
究其根源主要是MySQL内部对于load 和 insert的处理机制不同。
Load的处理机制是:在执行load之前,会关掉索引,当load全部执行完成后,再重新创建索引.
Insert的处理机制是:每插入一条则更新一次数据库,更新一次索引.
另外,load与insert的不同还体现在load省去了sql语句解析,sql引擎处理,而是直接生成文件数据块,所以会比Insert快很多.