来源:https://mp.weixin.qq.com/s/PLWovsMDxO0wUrDTMaOh4w
目录
数据准备
数据集
建表语句
窗口函数
row_number:使用频率 ★★★★★
rank :使用频率 ★★★★
dense_rank:使用频率 ★★★★
rank/dense_rank/row_number对比
first_value:使用频率 ★★★
last_value:使用频率 ★
lead:使用频率 ★★
lag:使用频率 ★★
集合相关
collect_set:使用频率 ★★★★★
collect_list:使用频率 ★★★★★
sort_array:使用频率 ★★★
URL相关parse_url:使用频率 ★★★★
reflect:使用频率 ★★
JSON相关
get_json_object:使用频率 ★★★★★
列转行相关
explode:使用频率 ★★★★★
Cube相关
GROUPING SETS:使用频率 ★
字符相关
concat:使用频率 ★★★★★
concat_ws:使用频率 ★★★★★
instr:使用频率 ★★★★
length:使用频率 ★★★★★
size:使用频率 ★★★★★
trim:使用频率 ★★★★★
regexp_replace:使用频率 ★★★★★
regexp_extract:使用频率 ★★★★
substring_index:使用频率 ★★
条件判断if:使用频率 ★★★★★
case when :使用频率 ★★★★★
coalesce:使用频率 ★★★★★
数值相关
round:使用频率 ★★
ceil:使用频率 ★★★
floor:使用频率 ★★★
hex:使用频率 ★
时间相关(比较简单)
from_unxitime:使用频率 ★★★★★
unix_timestamp:使用频率 ★★★★★
to_date:使用频率 ★★★★★
year:使用频率 ★★★★★
month:使用频率 ★★★★★
day:使用频率 ★★★★★
date_add:使用频率 ★★★★★
date_sub:使用频率 ★★★★★
数据准备
数据集
user1,https://blog.csdn.net/qq_28680977/article/details/108161655?k1=v1&k2=v2#Ref1,10,2020-09-12 02:20:02,2020-09-12 user1,https://blog.csdn.net/qq_28680977/article/details/108298276?k1=v1&k2=v2#Ref1,2,2020-09-11 11:20:12,2020-09-11 user1,https://blog.csdn.net/qq_28680977/article/details/108295053?k1=v1&k2=v2#Ref1,4,2020-09-10 08:19:22,2020-09-10 user1,https://blog.csdn.net/qq_28680977/article/details/108460523?k1=v1&k2=v2#Ref1,5,2020-08-12 19:20:22,2020-08-12 user2,https://blog.csdn.net/qq_28680977/article/details/108161655?k1=v1&k2=v2#Ref1,29,2020-04-04 12:23:22,2020-04-04 user2,https://blog.csdn.net/qq_28680977/article/details/108161655?k1=v1&k2=v2#Ref1,30,2020-05-15 12:34:23,2020-05-15 user2,https://blog.csdn.net/qq_28680977/article/details/108161655?k1=v1&k2=v2#Ref1,30,2020-05-15 13:34:23,2020-05-15 user2,https://blog.csdn.net/qq_28680977/article/details/108161655?k1=v1&k2=v2#Ref1,19,2020-05-16 19:03:32,2020-05-16 user2,https://blog.csdn.net/qq_28680977/article/details/108161655?k1=v1&k2=v2#Ref1,10,2020-05-17 06:20:22,2020-05-17 user3,https://blog.csdn.net/qq_28680977/article/details/108161655?k1=v1&k2=v2#Ref1,43,2020-04-12 08:02:22,2020-04-12 user3,https://blog.csdn.net/qq_28680977/article/details/108161655?k1=v1&k2=v2#Ref1,5,2020-08-02 08:10:22,2020-08-02 user3,https://blog.csdn.net/qq_28680977/article/details/108161655?k1=v1&k2=v2#Ref1,6,2020-08-02 10:10:22,2020-08-02 user3,https://blog.csdn.net/qq_28680977/article/details/108161655?k1=v1&k2=v2#Ref1,50,2020-08-12 12:23:22,2020-08-12 user4,https://blog.csdn.net/qq_28680977/article/details/108161655?k1=v1&k2=v2#Ref1,10,2020-04-12 11:20:22,2020-04-12 user4,https://blog.csdn.net/qq_28680977/article/details/108161655?k1=v1&k2=v2#Ref1,30,2020-03-12 10:20:22,2020-03-12 user4,https://blog.csdn.net/qq_28680977/article/details/108161655?k1=v1&k2=v2#Ref1,20,2020-02-12 20:26:43,2020-02-12 user2,https://blog.csdn.net/qq_28680977/article/details/108161655?k1=v1&k2=v2#Ref1,10,2020-04-12 19:12:36,2020-04-12 user2,https://blog.csdn.net/qq_28680977/article/details/108161655?k1=v1&k2=v2#Ref1,40,2020-05-12 18:24:31,2020-05-12
建表语句
create table wedw_tmp.tmp_url_info( user_id string comment "用户id", visit_url string comment "访问url", visit_cnt int comment "浏览次数/pv", visit_time timestamp comment "浏览时间", visit_date string comment "浏览日期" ) row format delimited fields terminated by ',' stored as textfile;
窗口函数
row_number:使用频率 ★★★★★
row_number函数通常用于分组统计组内的排名,然后进行后续的逻辑处理。
注意:当遇到相同排名的时候,不会生成同样的序号,且中间不会空位
该函数经常被大厂问到,可以参考
1 -- 统计每个用户每天最近一次访问记录 2 select 3 user_id, 4 visit_time, 5 visit_cnt 6 from 7 ( 8 select 9 *, 10 row_number() over(partition by user_id,visit_date order by visit_time desc) as rank 11 from wedw_tmp.tmp_url_info 12 )t 13 where rank=1 14 order by user_id,visit_time 15+----------+------------------------+------------+--+ 16| user_id | visit_time | visit_cnt | 17+----------+------------------------+------------+--+ 18| user1 | 2020-08-12 19:20:22.0 | 5 | 19| user1 | 2020-09-10 08:19:22.0 | 4 | 20| user1 | 2020-09-11 11:20:12.0 | 2 | 21| user1 | 2020-09-12 02:20:02.0 | 10 | 22| user2 | 2020-04-04 12:23:22.0 | 29 | 23| user2 | 2020-04-12 19:12:36.0 | 10 | 24| user2 | 2020-05-12 18:24:31.0 | 40 | 25| user2 | 2020-05-15 13:34:23.0 | 30 | --该用户同一天访问了多次,但只取了最新一次访问记录 26| user2 | 2020-05-16 19:03:32.0 | 19 | 27| user2 | 2020-05-17 06:20:22.0 | 10 | 28| user3 | 2020-04-12 08:02:22.0 | 43 | 29| user3 | 2020-08-02 10:10:22.0 | 6 | 30| user3 | 2020-08-12 12:23:22.0 | 50 | 31| user4 | 2020-02-12 20:26:43.0 | 20 | 32| user4 | 2020-03-12 10:20:22.0 | 30 | 33| user4 | 2020-04-12 11:20:22.0 | 10 | 34+----------+------------------------+------------+--+
rank :使用频率 ★★★★
和row_number功能一样,都是分组内统计排名,但是当出现同样排名的时候,中间会出现空位。这里给一个例子就可以很容易理解了
1 select 2 user_id, 3 visit_time, 4 visit_date, 5 rank() over(partition by user_id order by visit_date desc) as rank --每个用户按照访问时间倒排,通常用于统计用户最近一天的访问记录 6 from wedw_tmp.tmp_url_info 7 order by user_id,rank 8+----------+------------------------+-------------+-------+--+ 9| user_id | visit_time | visit_date | rank | 10+----------+------------------------+-------------+-------+--+ 11| user1 | 2020-09-12 02:20:02.0 | 2020-09-12 | 1 | 12| user1 | 2020-09-12 02:20:02.0 | 2020-09-12 | 1 | --同一天访问了两次,9月11号访问排名第三 13| user1 | 2020-09-11 11:20:12.0 | 2020-09-11 | 3 | 14| user1 | 2020-09-10 08:19:22.0 | 2020-09-10 | 4 | 15| user1 | 2020-08-12 19:20:22.0 | 2020-08-12 | 5 | 16| user2 | 2020-05-17 06:20:22.0 | 2020-05-17 | 1 | 17| user2 | 2020-05-16 19:03:32.0 | 2020-05-16 | 2 | 18| user2 | 2020-05-15 12:34:23.0 | 2020-05-15 | 3 | 19| user2 | 2020-05-15 13:34:23.0 | 2020-05-15 | 3 | 20| user2 | 2020-05-12 18:24:31.0 | 2020-05-12 | 5 | 21| user2 | 2020-04-12 19:12:36.0 | 2020-04-12 | 6 | 22| user2 | 2020-04-04 12:23:22.0 | 2020-04-04 | 7 | 23| user3 | 2020-08-12 12:23:22.0 | 2020-08-12 | 1 | 24| user3 | 2020-08-02 08:10:22.0 | 2020-08-02 | 2 | 25| user3 | 2020-08-02 10:10:22.0 | 2020-08-02 | 2 | 26| user3 | 2020-04-12 08:02:22.0 | 2020-04-12 | 4 | 27| user4 | 2020-04-12 11:20:22.0 | 2020-04-12 | 1 | 28| user4 | 2020-03-12 10:20:22.0 | 2020-03-12 | 2 | 29| user4 | 2020-02-12 20:26:43.0 | 2020-02-12 | 3 | 30+----------+------------------------+-------------+-------+--+
dense_rank:使用频率 ★★★★
和row_number以及rank功能一样,都是分组排名,但是该排名如果出现同次序的话,中间不会留下空位
1 --还是以rank的sql为例子 2 select 3 user_id, 4 visit_time, 5 visit_date, 6 dense_rank() over(partition by user_id order by visit_date desc) as rank 7 from wedw_tmp.tmp_url_info 8 order by user_id,rank 9+----------+------------------------+-------------+-------+--+ 10| user_id | visit_time | visit_date | rank | 11+----------+------------------------+-------------+-------+--+ 12| user1 | 2020-09-12 02:20:02.0 | 2020-09-12 | 1 | 13| user1 | 2020-09-12 02:20:02.0 | 2020-09-12 | 1 | 14| user1 | 2020-09-11 11:20:12.0 | 2020-09-11 | 2 |--中间不会留下空缺 15| user1 | 2020-09-10 08:19:22.0 | 2020-09-10 | 3 | 16| user1 | 2020-08-12 19:20:22.0 | 2020-08-12 | 4 | 17| user2 | 2020-05-17 06:20:22.0 | 2020-05-17 | 1 | 18| user2 | 2020-05-16 19:03:32.0 | 2020-05-16 | 2 | 19| user2 | 2020-05-15 12:34:23.0 | 2020-05-15 | 3 | 20| user2 | 2020-05-15 13:34:23.0 | 2020-05-15 | 3 | 21| user2 | 2020-05-12 18:24:31.0 | 2020-05-12 | 4 | 22| user2 | 2020-04-12 19:12:36.0 | 2020-04-12 | 5 | 23| user2 | 2020-04-04 12:23:22.0 | 2020-04-04 | 6 | 24| user3 | 2020-08-12 12:23:22.0 | 2020-08-12 | 1 | 25| user3 | 2020-08-02 08:10:22.0 | 2020-08-02 | 2 | 26| user3 | 2020-08-02 10:10:22.0 | 2020-08-02 | 2 | 27| user3 | 2020-04-12 08:02:22.0 | 2020-04-12 | 3 | 28| user4 | 2020-04-12 11:20:22.0 | 2020-04-12 | 1 | 29| user4 | 2020-03-12 10:20:22.0 | 2020-03-12 | 2 | 30| user4 | 2020-02-12 20:26:43.0 | 2020-02-12 | 3 | 31+----------+------------------------+-------------+-------+--+
rank/dense_rank/row_number对比
相同点:都是分组排序
不同点:
Row_number:即便出现相同的排序,排名也不会一致,只会进行累加;即排序次序连续,但不会出现同一排名
rank:当出现相同的排序时,中间会出现一个空缺,即分组内会出现同一个排名,但是排名次序是不连续的
Dense_rank:当出现相同排序时,中间不会出现空缺,即分组内可能会出现同样的次序,且排序名次是连续的
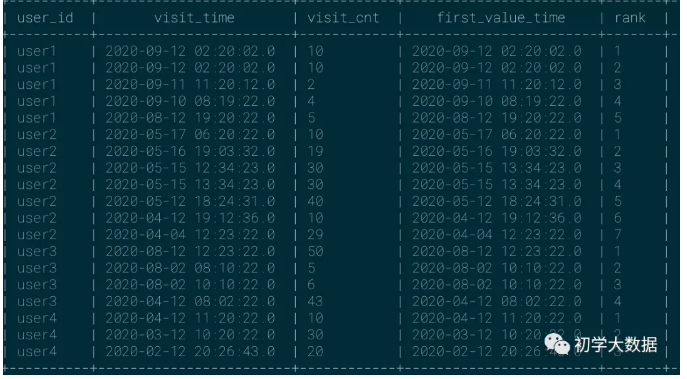
first_value:使用频率 ★★★
按照分组排序取截止到当前行的第一个值;通常用于取最新记录或者最早的记录(根据排序字段进行变通即可)
1 --仍然使用row_number的例子;方便读者理解 2 select 3 user_id, 4 visit_time, 5 visit_cnt, 6 first_value(visit_time) over(partition by user_id order by visit_date desc) as first_value_time, 7 row_number() over(partition by user_id order by visit_date desc) as rank 8 from wedw_tmp.tmp_url_info 9 order by user_id,rank

last_value:使用频率 ★
按照分组排序取当前行的最后一个值;这个函数好像没啥卵用
1 --仍然使用row_number的例子;方便读者理解 2 select 3 user_id, 4 visit_time, 5 visit_cnt, 6 last_value(visit_time) over(partition by user_id order by visit_date desc) as first_value_time, 7 row_number() over(partition by user_id order by visit_date desc) as rank 8 from wedw_tmp.tmp_url_info 9 order by user_id,rank
lead:使用频率 ★★
LEAD(col,n,DEFAULT)用于取窗口内往下第n行值;通常用于行值填充;或者和指定行进行差值比较
第一个参数为列名
第二个参数为往下第n行(可选),
第三个参数为默认值(当往下第n行为NULL时候,取默认值,如不指定,则为NULL)
1 select 2 user_id, 3 visit_time, 4 visit_cnt, 5 row_number() over(partition by user_id order by visit_date desc) as rank, 6 lead(visit_time,1,'1700-01-01') over(partition by user_id order by visit_date desc) as lead_time 7 from wedw_tmp.tmp_url_info 8 order by user_id 9+----------+------------------------+------------+-------+------------------------+--+ 10| user_id | visit_time | visit_cnt | rank | lead_time | 11+----------+------------------------+------------+-------+------------------------+--+ 12| user1 | 2020-09-12 02:20:02.0 | 10 | 1 | 2020-09-12 02:20:02.0 | --取下一行的值作为当前值 13| user1 | 2020-09-12 02:20:02.0 | 10 | 2 | 2020-09-11 11:20:12.0 | 14| user1 | 2020-09-11 11:20:12.0 | 2 | 3 | 2020-09-10 08:19:22.0 | 15| user1 | 2020-09-10 08:19:22.0 | 4 | 4 | 2020-08-12 19:20:22.0 | 16| user1 | 2020-08-12 19:20:22.0 | 5 | 5 | 1700-01-01 00:00:00.0 | --这里是最后一条记录,则取默认值 17| user2 | 2020-05-17 06:20:22.0 | 10 | 1 | 2020-05-16 19:03:32.0 | 18| user2 | 2020-05-16 19:03:32.0 | 19 | 2 | 2020-05-15 12:34:23.0 | 19| user2 | 2020-05-15 12:34:23.0 | 30 | 3 | 2020-05-15 13:34:23.0 | 20| user2 | 2020-05-15 13:34:23.0 | 30 | 4 | 2020-05-12 18:24:31.0 | 21| user2 | 2020-05-12 18:24:31.0 | 40 | 5 | 2020-04-12 19:12:36.0 | 22| user2 | 2020-04-12 19:12:36.0 | 10 | 6 | 2020-04-04 12:23:22.0 | 23| user2 | 2020-04-04 12:23:22.0 | 29 | 7 | 1700-01-01 00:00:00.0 | 24| user3 | 2020-08-12 12:23:22.0 | 50 | 1 | 2020-08-02 08:10:22.0 | 25| user3 | 2020-08-02 08:10:22.0 | 5 | 2 | 2020-08-02 10:10:22.0 | 26| user3 | 2020-08-02 10:10:22.0 | 6 | 3 | 2020-04-12 08:02:22.0 | 27| user3 | 2020-04-12 08:02:22.0 | 43 | 4 | 1700-01-01 00:00:00.0 | 28| user4 | 2020-04-12 11:20:22.0 | 10 | 1 | 2020-03-12 10:20:22.0 | 29| user4 | 2020-03-12 10:20:22.0 | 30 | 2 | 2020-02-12 20:26:43.0 | 30| user4 | 2020-02-12 20:26:43.0 | 20 | 3 | 1700-01-01 00:00:00.0 | 31+----------+------------------------+------------+-------+------------------------+--+
lag:使用频率 ★★
和lead功能一样,但是是取上n行的值作为当前行值
1 select 2 user_id, 3 visit_time, 4 visit_cnt, 5 row_number() over(partition by user_id order by visit_date desc) as rank, 6 lag(visit_time,1,'1700-01-01') over(partition by user_id order by visit_date desc) as lead_time 7 from wedw_tmp.tmp_url_info 8 order by user_id
