来源:https://developer.aliyun.com/article/769981
http://bubuko.com/infodetail-3554826.html
1 开发环境依赖
PyFlink作业的开发和运行需要依赖Python 3.5/3.6/3.7 版本和Java 8或者Java 11,本游乐场所使用的环境是Java 1.8.0_211, Python 3.7.7 还有一些其他基础软件如下;
- Java 1.8.0_211
- Python 3.7.7
- PIP 20.0.2
- PyCharm Runtime version: 11.0.7
- MocOS 10.14.6
2 PyCharm 配置 Python interpreter
应用PyCharm进行开发首先要配置一下项目所使用的Python环境,配置路径PyCharm -> Preferences -> Project Interpreter如下:
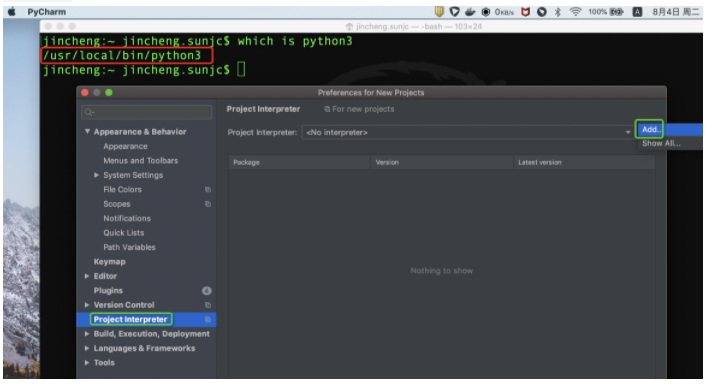
点击 Add 配置新的环境,如下:

一路”OK“,完成配置。
安装PyFlink
我们先利用PyCharm创建一些项目,名为PyFlinkPlayground, 并为项目选择我们刚才创建的Virtualenv环境,如下:
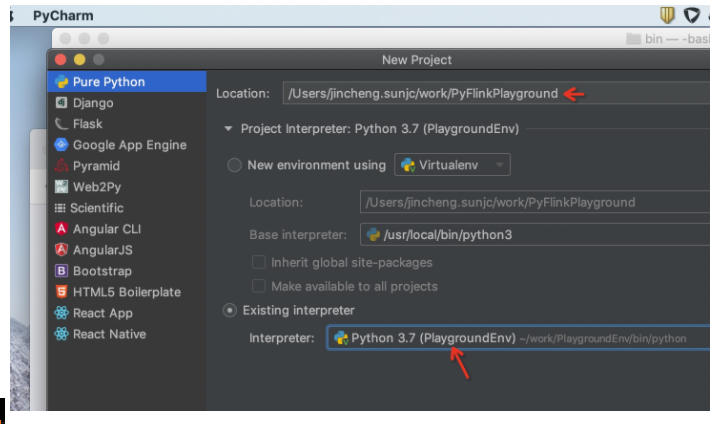
创建之后,我们会看到External Libraries 里面使用了PlaygroundEnv, 但是初始化并没有PyFlink,所以我们需要进行显示的安装,如下:
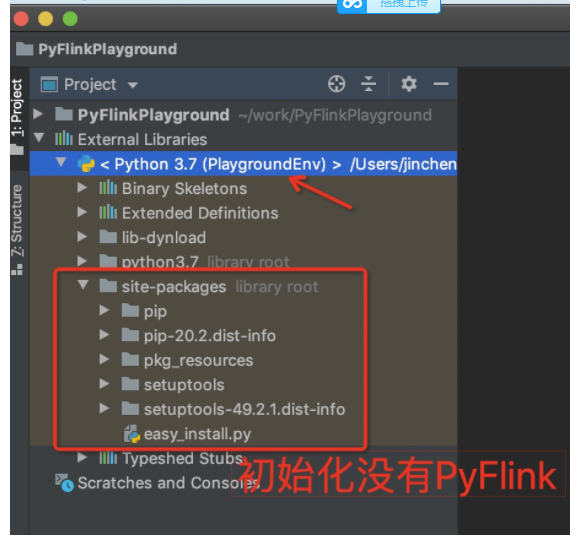
我们可以手工安装PyFlink,直接在PyCharm的Terminal下进行安装,这时候我们自动就是启动的PlaygroundEnv环境,在安装的过程中你也可以看到site-packages内容会不断增加,
(PlaygroundEnv) jincheng:~ jincheng.sunjc$ python --version Python 3.7.7 (PlaygroundEnv) jincheng:~ jincheng.sunjc$ python -m pip install apache-flink==1.11.1 Collecting apache-flink==1.11.1 Using cached apache_flink-1.11.1-cp37-cp37m-macosx_10_9_x86_64.whl (206.7 MB) ... ... Successfully installed apache-beam-2.19.0 apache-flink-1.11.1 avro-python3-1.9.1 certifi-2020.6.20 chardet-3.0.4 cloudpickle-1.2.2 crcmod-1.7 dill-0.3.1.1 docopt-0.6.2 fastavro-0.21.24 future-0.18.2 grpcio-1.30.0 hdfs-2.5.8 httplib2-0.12.0 idna-2.10 jsonpickle-1.2 mock-2.0.0 numpy-1.19.1 oauth2client-3.0.0 pandas-0.25.3 pbr-5.4.5 protobuf-3.12.4 py4j-0.10.8.1 pyarrow-0.15.1 pyasn1-0.4.8 pyasn1-modules-0.2.8 pydot-1.4.1 pymongo-3.11.0 pyparsing-2.4.7 python-dateutil-2.8.0 pytz-2020.1 requests-2.24.0 rsa-4.6 six-1.15.0 typing-3.7.4.3 typing-extensions-3.7.4.2 urllib3-1.25.10 (PlaygroundEnv) jincheng:~ jincheng.sunjc$
最终完成之后你可以在 site-packages下面找的 pyflink目录,如下:

有了这些信息我们就可以进行PyFlink的作业开发了。
from pyflink.datastream import StreamExecutionEnvironment from pyflink.table import EnvironmentSettings, StreamTableEnvironment def hello_world(): """ 从随机Source读取数据,然后直接利用PrintSink输出。 """ settings = EnvironmentSettings.new_instance().in_streaming_mode().use_blink_planner().build() env = StreamExecutionEnvironment.get_execution_environment() t_env = StreamTableEnvironment.create(stream_execution_environment=env, environment_settings=settings) source_ddl = """ CREATE TABLE random_source ( f_sequence INT, f_random INT, f_random_str STRING ) WITH ( 'connector' = 'datagen', 'rows-per-second'='5', 'fields.f_sequence.kind'='sequence', 'fields.f_sequence.start'='1', 'fields.f_sequence.end'='1000', 'fields.f_random.min'='1', 'fields.f_random.max'='1000', 'fields.f_random_str.length'='10' ) """ sink_ddl = """ CREATE TABLE print_sink ( f_sequence INT, f_random INT, f_random_str STRING ) WITH ( 'connector' = 'print' ) """ # 注册source和sink t_env.execute_sql(source_ddl); t_env.execute_sql(sink_ddl); # 数据提取 tab = t_env.from_path("random_source"); # 这里我们暂时先使用 标注了 deprecated 的API, 因为新的异步提交测试有待改进... tab.insert_into("print_sink"); # 执行作业 t_env.execute("Flink Hello World"); if __name__ == '__main__': hello_world()
上面代码在PyCharm里面右键运行就应该打印如下结果了:
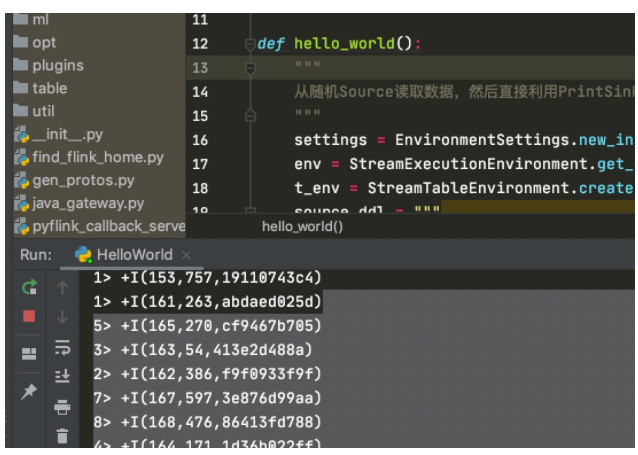
开发日志
正常来讲我们可能开发一些UDF,可能打印一些日志或者特殊情况还可能进行Python代码的调试,怎么解?
- 首先,我们定义一个UDF,在UDF里面添加调试日志,如下:
# 定义UDF @udf(input_types=[DataTypes.STRING()], result_type=DataTypes.STRING()) def pass_by(str): logging.error("Some debugging infomation...") return str
- 然后在SQL里面使用这个UDF,如下:
# 注册 UDF t_env.register_function('pass_by', pass_by) # 使用UDF tab.select("f_sequence, f_random, pass_by(f_random_str) ")
- 完整的代码
from pyflink.datastream import StreamExecutionEnvironment from pyflink.table import EnvironmentSettings, StreamTableEnvironment, DataTypes from pyflink.table.udf import udf import logging # 定义UDF @udf(input_types=[DataTypes.STRING()], result_type=DataTypes.STRING()) def pass_by(str): logging.error("Some debugging infomation...") return "pass_by_" + str def hello_world(): """ 从随机Source读取数据,然后直接利用PrintSink输出。 """ settings = EnvironmentSettings.new_instance().in_streaming_mode().use_blink_planner().build() env = StreamExecutionEnvironment.get_execution_environment() t_env = StreamTableEnvironment.create(stream_execution_environment=env, environment_settings=settings) t_env.get_config().get_configuration().set_boolean("python.fn-execution.memory.managed", True) source_ddl = """ CREATE TABLE random_source ( f_sequence INT, f_random INT, f_random_str STRING ) WITH ( 'connector' = 'datagen', 'rows-per-second'='5', 'fields.f_sequence.kind'='sequence', 'fields.f_sequence.start'='1', 'fields.f_sequence.end'='1000', 'fields.f_random.min'='1', 'fields.f_random.max'='1000', 'fields.f_random_str.length'='10' ) """ sink_ddl = """ CREATE TABLE print_sink ( f_sequence INT, f_random INT, f_random_str STRING ) WITH ( 'connector' = 'print' ) """ # 注册source和sink t_env.execute_sql(source_ddl); t_env.execute_sql(sink_ddl); # 注册 UDF t_env.create_temporary_system_function('pass_by', pass_by) # 数据提取 tab = t_env.from_path("random_source"); # 这里我们暂时先使用 标注了 deprecated 的API, 因为新的异步提交测试有待改进... tab.select("f_sequence, f_random, pass_by(f_random_str) ").execute_insert("print_sink")
if __name__ == '__main__': hello_world()
那么运行之后,日志在哪里呢?就是在项目的 PlaygroundEnv -> site-packages -> pyflink -> log 目录 ,如下:
到这里,简单的 开发环境就OK了,大家可以改改代码,直观体验一下。。。