面试题目一
场景:一个日志表中记录了某个商户费率变化状态的所有信息,现在有个需求,要取出按照时间轴顺序,发生了状态变化的数据行;
1.数据如下:
create table datafrog_merchant (f_merchant_id varchar(20), f_rate varchar(20), f_date date ); insert into datafrog_merchant values (100,0.1,'2016-03-02'), (100,0.1,'2016-02-02'), (100,0.2,'2016-03-05'), (100,0.2,'2016-03-06'), (100,0.3,'2016-03-07'), (100,0.1,'2016-03-09'), (100,0.1,'2016-03-10'), (100,0.1,'2016-03-10'), (200,0.1,'2016-03-10'), (200,0.1,'2016-02-02'), (200,0.2,'2016-03-05'), (200,0.2,'2016-03-06'), (200,0.3,'2016-03-07'), (200,0.1,'2016-03-09'), (200,0.1,'2016-03-10'), (200,0.1,'2016-03-10');
我们来看看数据长得怎么样:
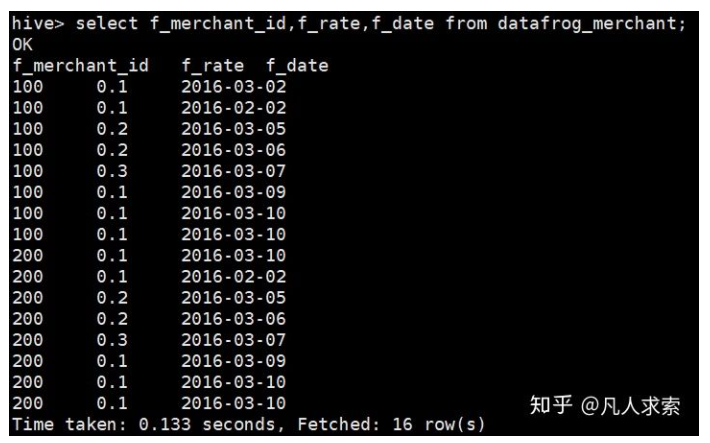
2.实现想要的效果
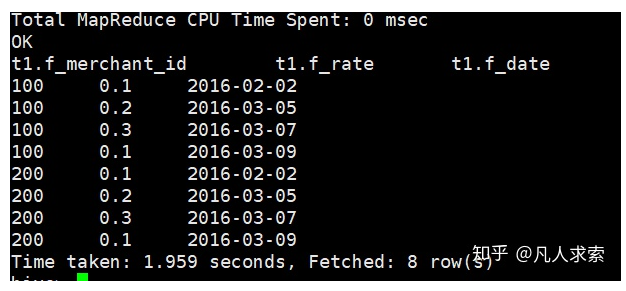
解决问题思路:Lag函数或者Lead函数可以将上一行或者下一行的字段内容获取到本行,这样可以比较字段是否发生变化,进而判断是否状态变化,是否需要提取出该数据行;
select t1.f_merchant_id, t1.f_rate, t1.f_date from ( select f_merchant_id, f_rate, f_date, lag(f_rate,1,-999) over(partition by f_merchant_id order by f_date) as f_rate2 from datafrog_merchant ) t1 where t1.f_rate <> t1.f_rate2
面试题目二
1.题目如下
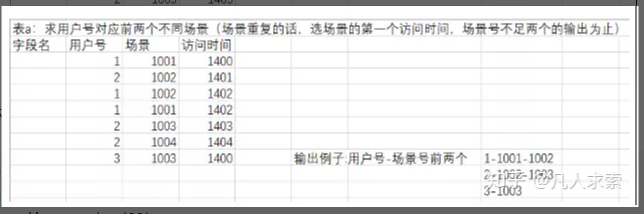
2.下面开始建表、插入数据
create table datafrog_test1 (userid varchar(20), changjing varchar(20), inttime varchar(20) ); insert into datafrog_test1 values (1,1001,1400), (2,1002,1401), (1,1002,1402), (1,1001,1402), (2,1003,1403), (2,1004,1404), (3,1003,1400) (4,1004,1402), (4,1003,1403), (4,1001,1403), (4,1002,1404) (5,1002,1402), (5,1002,1403), (5,1001,1404), (5,1003,1405);
3.mysql解答思路:排序及concat连接
select concat(t.userid,'-',group_concat(t.changjing separator'-')) as result from( select userid,changjing,inttime, if(@tmp=userid,@rank:=@rank+1,@rank:=1) as new_rank, @tmp:=userid as tmp from (select userid,changjing, min(inttime) inttime from datafrog_test1 group by userid,changjing)temp order by userid,inttime )t where t.new_rank<=2 group by t.userid;
4.输出结果:
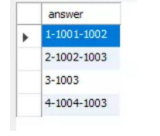
5.注意:
有可能大家的代码会有报错现象,主要是ONLY_FULL_GROUP_BY引起的报错,解决办法是运行上面代码时,运行下这个就好set sql_mode='' 。其实mysql 作为查询还是不错的,但是拿来做分析的话,就是有点乏力了,像排序、中位数等都比较麻烦些的,工作中一般用pandas、sqlserver、oracle、hive、spark这些来做分析。这里可不是说mysql没用,反而是特别有用,也容易上手,是其他的基础。
6.大家来看下hive解法
with tmp as ( select userid, changjing,order_num,changjing1 from (SELECT userid , changjing, row_number() over(partition by userid order by inttime asc) as order_num, lag(changjing,1,'datafrog') OVER(partition by userid order by inttime asc) AS changjing1 FROM datafrog_test1) as a where changjing!=changjing1) , tmp2 as ( select userid,changjing,order_num,changjing1, row_number() over(partition by userid order by order_num ) as changjing_num from tmp ) select concat( userid,'-',concat_ws('-', collect_set(changjing)) ) from tmp2 where changjing_num <3 group by userid
这里主要考察了hive sql 中的with as、row_number() over()、lag() 的用法