前文我们聊了下haproxy的global配置段中的常用参数的说明以及使用,回顾请参考https://www.cnblogs.com/qiuhom-1874/p/12763245.html;今天我们来说说haproxy的代理配置段中比较重要的参数配置的用法;
代理配置段中分三段配置,第一段是defaults配置段,这一段我们在上一篇博客中也说过,主要用于定义一些默认参数配置;第二段是frontend配置段,该段主要用来定义haporxy面向客户端怎样提供服务的;比如监听在那个地址的那个端口啊,调度那个后端服务器组呀等等;第三段就是后端服务器的配置段,通常frontend和backend是联合使用,也就是说frontend必须调用一个已经定义好的backend这样才能够完全的把用户的请求调度到对应服务器或者服务器组上;而对于listen来讲,它更像一个代理的角色,它既可以定义前端对于用户端监听地址信息,同时它也能定义后端server的属性;简单讲listen指令融合了frontend和backend的功能;了解了如何定义前端监听地址以及后端被代理的server的方式后,接下来我们一一来看下代理配置段中的配置;
defaults里的配置
mode:该指令用于指定haporxy的工作类型的;http表示haproxy基于http协议代理后端服务器,这也是默认haproxy的工作类型;如果我们在后端backend或listen中没有配置haporxy的工作类型,默认就会继承defaults里的配置;tcp表示haproxy基于tcp协议代理后端服务器响应客户端请求;
option redispatch :当后端server宕机后,强制把请求定向到其他健康的服务器上;正是因为这个参数,就确保了用户端请求不会被调度到一个宕机的服务器上;
示例:我们把option redispatch 这个配置注释掉,重启haproxy,然后把后端容器给停掉一台,看看haproxy会不会把对应的请求调度到停掉的server上呢?
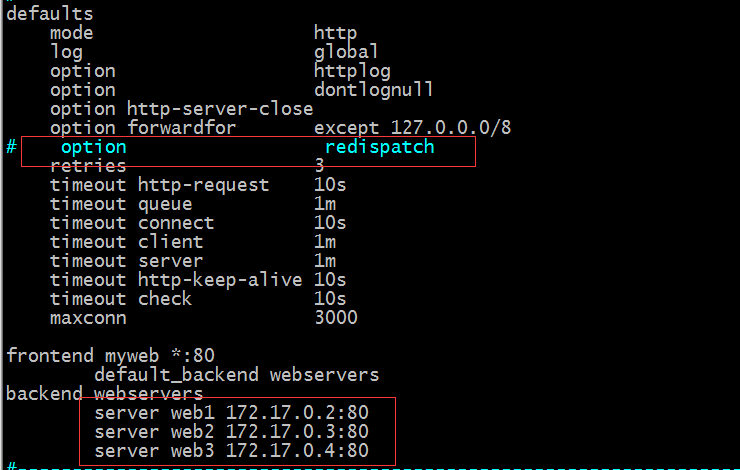
提示:我们只是注释了option redispatch 这段配置;对于后端服务器并没有人为手动的去修改;正常情况下,三台服务器如果都是正常的情况,是能够轮询的方式响应客户端请求的;现在我们把后端服务器停一台看看用户的请求会不会调度到停掉的那台服务器上呢?

提示:现在我们可以看到web2的状态是退出状态,不能够响应客户端的请求的;接下来我们用浏览器访问haproxy对外提服务的IP地址和端口;看看是否把用户请求调度到宕机的主机上

提示:可以看到haproxy还是把用户端请求往宕机的主机上调度;我们把option redispatch 配置打开,然后重启haproxy,在看看会不会把用户请求调度到宕机的主机上

提示:我们打开option redispatch 配置,然后重启haproxy;对于web2现在还是宕机的状态,我们再用浏览器访问,看看这次会不会把用户请求调度到宕机的web2上呢

提示:我们把option redispatch 配置加上后,我们用浏览器访问haproxy的80端口,它不会把用户端请求调度到web2上去,原因就是因为检测web2没有通过,强制把请求调度到下一个服务器上去了;之所以我们看到中间有一段时间要等,是因为haproxy在对web2进行检测;
option abortonclose:当服务器负载很高的时候,自动结束掉当前队列处理比较久的链接;
option http-keep-alive 60:开启会话保持,并设置时长为60s
option forwardfor:开启IP透传;这个参数的意思是把客户端的源ip信息通过X-Forwarded-For首部传给后端server,后端server可通过扑捉haproxy发来的请求报文,把对应X-Forwarded-For首部的值记录下来;通常需要后端服务器更改日志格式,把对应首部的值加入到日志中显示;
示例:配置后端server记录haproxy发来的请求报文中X-Forwarded-For首部的值;

提示:我们在web1上修改了httpd的日志格式,让第一个字段记录X-Forwarded-For首部的值;然后让httpd重读配置文件;接下来我们就可以用浏览器访问haproxy,看看web1是否能够把客户端的源ip记录下来
提示:可以看到当haproxy把我们的请求调度到web1上时,对应web1的日志就会把X-Forwarded-For的值记录下来;这个首部的值就是记录客户端的源ip地址的;这样一来我们后端server上的日志就不再只有haproxy代理的的地址了;
timeout connect 60s:转发客户端请求到后端server的最长连接时间;这个时间是定义代理连接后端服务器的超时时长;
timeout server 600s :转发客户端请求到后端服务端的超时超时时长;这个时间是服务端响应代理的超时时长;
timeout client 600s :与客户端的最长空闲时间;
timeout http-keep-alive 120s:session 会话保持超时时间,范围内会转发到相同的后端服务器;
timeout check 5s:对后端服务器的检测超时时间;
retries 3:定义重试次数;
maxconn 3000:server的最大连接数(通常这个会配置在各server后面,用来指定该server的最大连接数)
以上就是haproxy defaults配置段的常用配置说明和使用;接下来我们来说一下frontend 配置段和backend配置段
frontend配置段里的指令配置
bind:该指令用于指定绑定IP和端口的,通常用于frontend配置段中或listen配置段中;用法是bind [IP]:<PORT>,……
示例:

提示:以上配置表示前端监听80端口和8080端口,这两个端口都可以把用户端请求代理到后端指定的服务器组上进行响应;
测试:重启haproxy 用浏览器访问192.168.0.22:8080端口,看看是否能够响应?

提示:可以看到我们用浏览器访问8080也是能够正常响应的;
除此以外,前端监听端口我们也可以不用bind参数指定 我们直接在frontend 或listen名字后面加要监听的地址和端口即可,如下所示

提示:listen的配置也是支持以上两种的形式去监听端口的;通常不写IP地址表示监听本机所以ip地址对应的端口;
balance:指定后端服务器组内的服务器调度算法;这个指令只能用于listen和backend或者defaults配置段中;
roundrobin:动态轮询;支持权重的运行时调整,支持慢启动,每个后端中最多支持4095个server;什么意思呢?动态调整权重就是说不重启服务的情况下调整权重;慢启动说的是,前端的流量不会一下子全部给打进来,而是一部分一部分的打到后端服务器上;这样可以有效防止流量过大时一下子把后端服务器压垮的情况;后端最多支持4095个server表示在一个backend或listen中使用该算法最多只能定义4095个server;通常对于生产环境这个也是够用了;
static-rr:静态轮询,不支持权重的运行时调整,不支持慢启动;这也是静态算法的缺点;但这种算法对后端server没有限制;
leastconn:最少连接算法;该算法本质上同static-rr没有太多的不同,通常情况下static-rr用于短连接场景中;而leastconn多用于长连接的场景中,如MySQL、LDAP等;
first:根据服务器在列表中的位置,自上而下进行调度;前面服务器的连接数达到上限,新请求才会分配给下一台服务;
source:源地址hash算法;类似LVS中的sh算法;hash类的算法动态与否取决于hash-type的值;如果我们定义hash-type的值为map-based(除权取余法)就表示该算法是静态算法,静态算法就不支持慢启动,动态调整权重;如果hash-type的值是consistent(一致性哈希)就表示该算法是动态算法,支持慢启动,动态权重调整;
uri:对URI的左半部分做hash计算,并由服务器总权重相除以后派发至某挑出的服务器;这里说一下一个完整的rul的格式;<scheme>://[user:password@]<host>:<port>[/path][;params][?query][#frag]其中scheme,host,port这三项是必须有的,其他可有可无;这里说的uri就是指[/path][;params][?query][#frag]这一部分,而uri的左半部份指的是[/path][;params];所以uri算法是对用户请求的资源路径+参数做hash计算;
url_param:对用户请求的uri的<params>部分中的参数的值作hash计算,并由服务器总权重相除以后派发至某挑出的服务器;通常用于追踪用户,以确保来自同一个用户的请求始终发往同一个Backend Server;
hdr(<name>):对于每个http请求,此处由<name>指定的http首部将会被取出做hash计算; 并由服务器总权重相除以后派发至某挑出的服务器;没有有效值的会被轮询调度; 如hdr(Cookie)使用cookie首部做hash,把同一cookie的访问始终调度到某一台后端服务器上;
示例:使用uri算法,并指定使用一致性hash算法
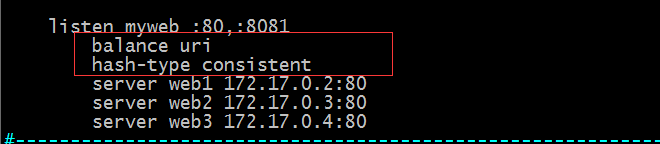
提示:这样配置后,用户访问80端口的某一个uri始终会发往同一台服务器上;不管是那个用户去访问都会被调度到同一台服务器上进行响应
我们在后端服务器上提供一些默认的页面,分别用不同的客户主机去访问相同的rul看看haproxy会怎么调度?
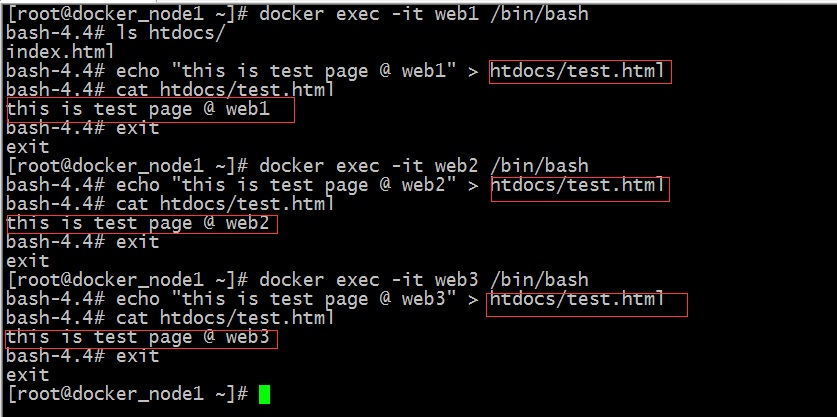
提示:在三个容器内部分别新建了一个test.html的文件,其内容都是不相同的;接下来我们用浏览器访问/test.html看看会怎么调度

提示:可以看到我们不管是用windows上的浏览器访问还是用Linux中的curl访问 都是被调度到web1上去了;其他算法我这里就不过多去测试了,有兴趣的小伙伴可自己动手去试试,看看效果;
default_backend <backend>:设定默认的backend,用于frontend中;
use_backend <backend>:调用对应的backend,用于frontend中;
示例:

提示:以上配置表示用户访问80端口或8081端口,都会被调度到webservs这个后端服务器组上进行响应;
server <name> <address>[:[port]] [param*]:定义后端主机的各服务器及其选项;name表示服务器在haproxy上的内部名称;出现在日志及警告信息中;address表示服务器地址,支持使用主机名;port:端口映射;省略时,表示同bind中绑定的端口;param表示参数;常用的参数有如下几个:
maxconn <maxconn>:当前server的最大并发连接数;
backlog <backlog>:当前server的连接数达到上限后的后援队列长度;
backup:设定当前server为备用服务器;和nginx里的sorry server 是一样的;
cookie <value>:为当前server指定其cookie值,用于实现基于cookie的会话黏性;
disabled:标记为不可用;相当于nginx里的down;
redir <prefix>:将发往此server的所有GET和HEAD类的请求重定向至指定的URL;
weight <weight>:权重,默认为1;
on-error <mode>:后端服务故障时采取的行动策略;策略有如下几种:
fastinter:表示缩短健康状态检测间的时长;
fail-check:表示即健康状态检测失败,也要检测;这是默认策略;
sudden-death:模拟一个致命前的失败的健康检查,一个失败的检查将标记服务器关闭,强制fastinter
mark-down:立即标记服务器不可用,并强制fastinter;
check:对当前server做健康状态检测;
addr :检测时使用的IP地址;
port :针对此端口进行检测;
inter <delay>:连续两次检测之间的时间间隔,默认为2000ms;
rise <count>:连续多少次检测结果为“成功”才标记服务器为可用;默认为2;
fall <count>:连续多少次检测结果为“失败”才标记服务器为不可用;默认为3;
示例:
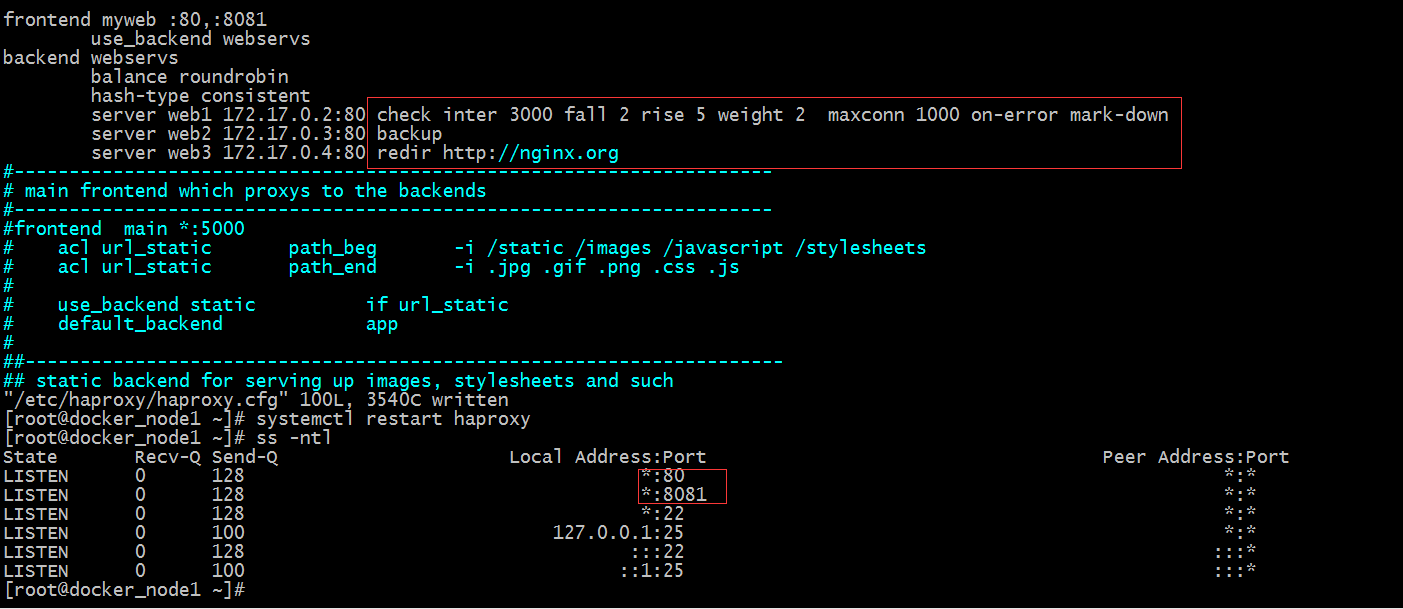
提示:以上配置表示对web1进行健康状态检测 每隔3000毫秒检测一次,检测2次失败就立刻标记为不可用,并强制缩短检测间隔时长;权重为2,意思是该服务器被调度两次,其他服务器调度一次;最大连接为1000;web2配置为backup角色,只有当web1和web3宕机后,web2才被调度;访问web3的请求直接重定向到http://nginx.org上响应;接下来我们如果访问haproxy的80或8081端口,应该是可以访问到web1和web3;如果web1和web3宕机后,web2就会被调度;
测试:在web1和web3都正常的情况下,看看web2是否被调度?
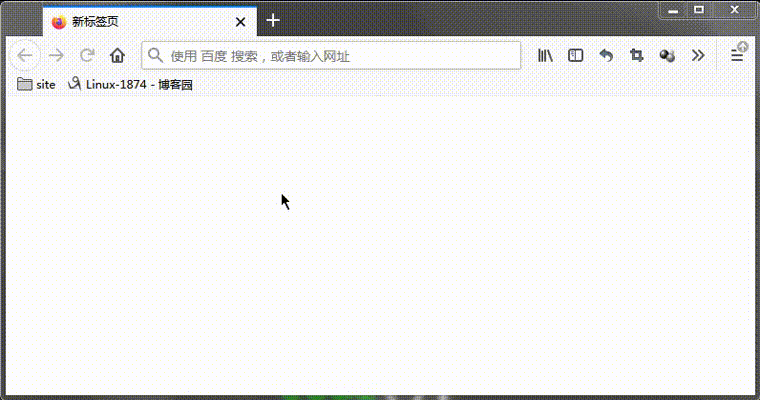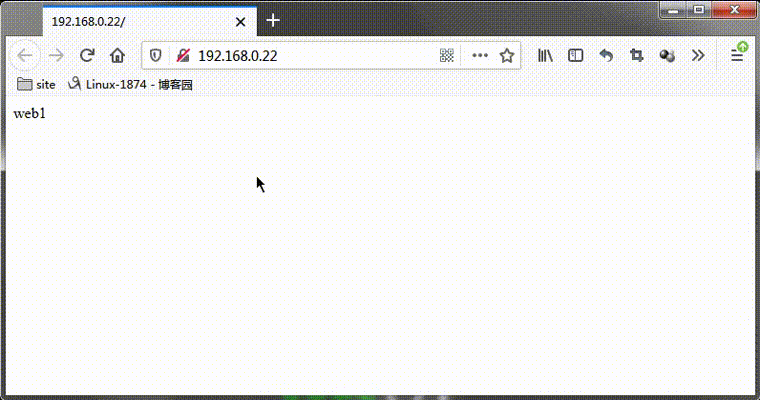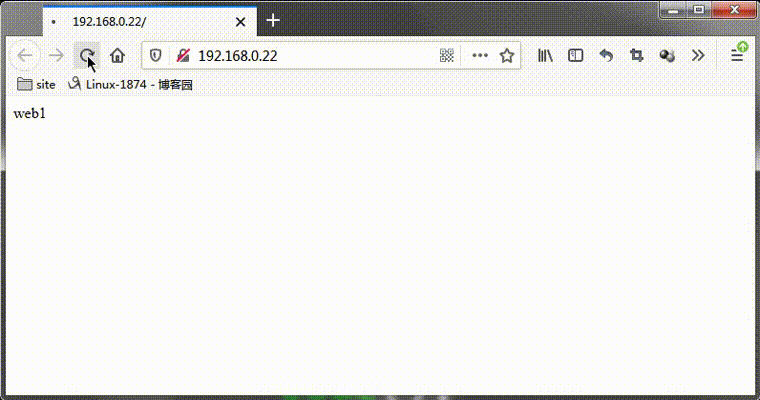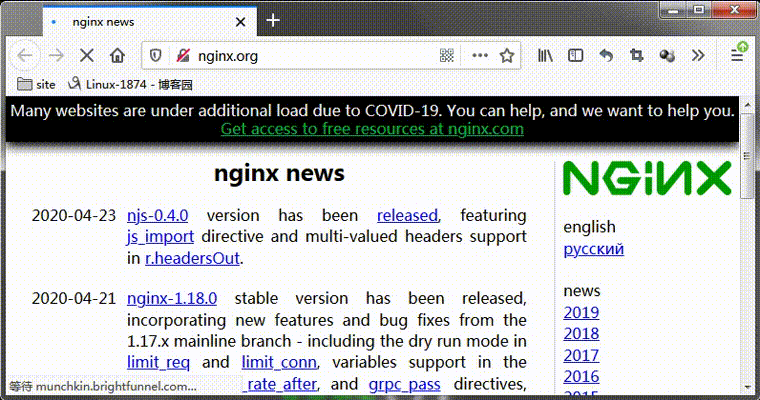
提示:可以看到web2是没有被调度的,web1被调度两次后,直接跳过web2,调度web3去了;
测试:把web1和web3停了,看看web2是否被调度?

提示:我们把web1和web3给停了,用浏览器访问,它还是跳转了;这说明redir不关心所在server是否存活,它都会做跳转,只不过所在server存活的情况下,用户请求偶尔几次会不跳转,但一定会有跳转的情况;这样来说吧,只要有跳转所在server,且没有做健康状态检测,那么不管该组是否有存活server backup都是不能被激活的;要想backup被激活必须让haproxy知道对应后端服务器组里是否有活跃的服务器,如果有,它就不会激活backup,如果没有就会激活;但现在haproxy不知道,原因是web3压根没有做健康状态检测;所以要想激活backup,我们需要在web3上配置一个check即可;如下
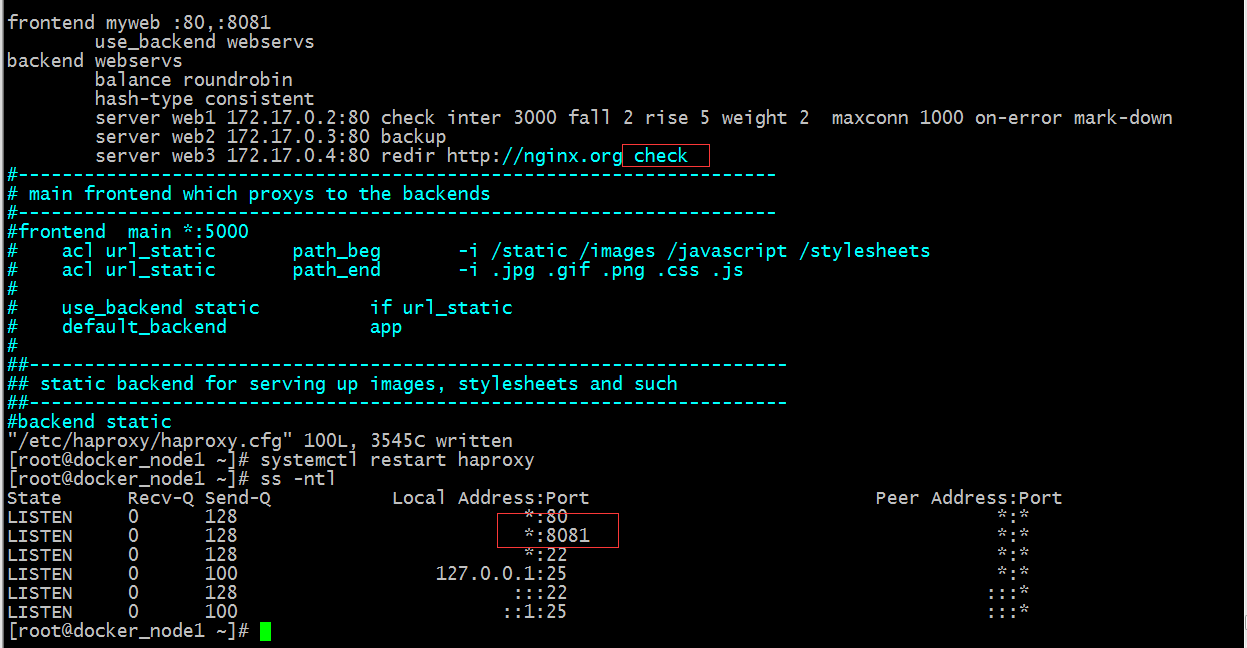
提示:我们在web3上加入健康状态检测后服务能够正常起来;这样配置后,backup服务器就会被激活,如下

现在我们把web3启动起来,看看它是否还会跳转呢?
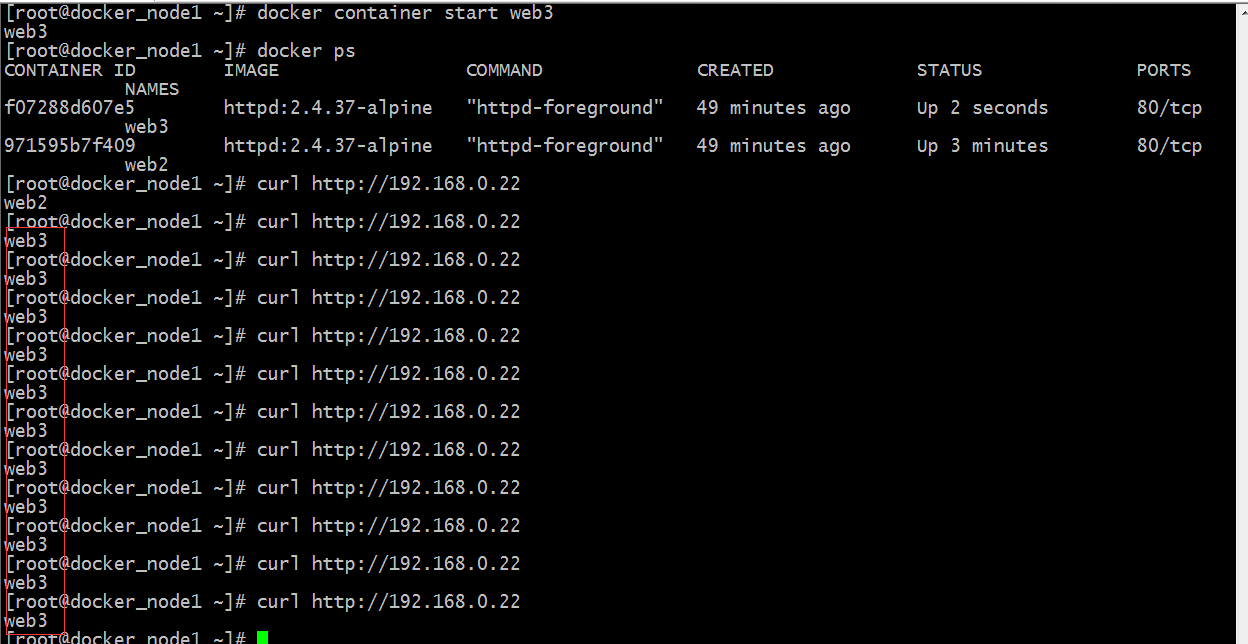
提示:可以看到我们把web3启动起来,对应的跳转就失效了;从上面的结果我这里总结了一条,redir和check建议不要一起用,一起用的话,对应redir就会失效;