pandas数据结构:
series序列:存储一行或一列的数据,以及与此相关索引的集合。
常用操作方法如下:


from pandas import Series; #定义,可以混合定义 x = Series(['a', True, 1], index=['first', 'second', 'third']); x = Series(['a', True, 1]); #访问 x[1]; #根据index访问 x['second']; #不能越界访问 x[3] #不能追加单个元素 x.append('2') #追加一个序列 n = Series(['2']) x.append(n) #需要使用一个变量来承载变化 x = x.append(n) '2' in x #判断值是否存在 '2' in x.values #切片 x[1:3] #定位获取,这个方法经常用于随机抽样 x[[0, 2, 1]] #根据index删除 x.drop(0) x.drop('first') #根据位置删除 x.drop(x.index[3]) #根据值删除 x['2'!=x.values]
DataFrame:存储多行多列的数据集合。
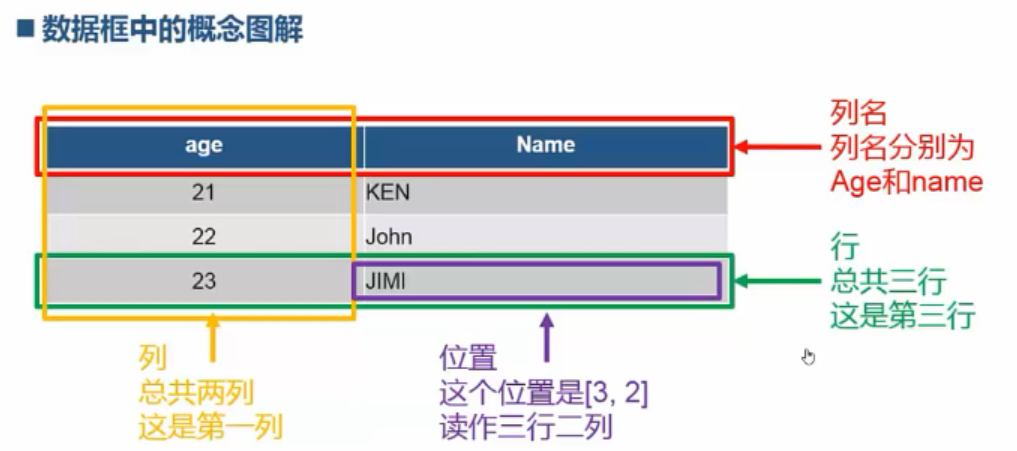
常用操作方法如下:
from pandas import DataFrame; df = DataFrame({ 'age': [21, 22, 23], 'name': ['KEN', 'John', 'JIMI'] }); df = DataFrame(data={ 'age': [21, 22, 23], 'name': ['KEN', 'John', 'JIMI'] }, index=['first', 'second', 'third']); df #按列访问 df['age'] #按行访问 df[1:2] #按行列号访问 df.iloc[0:1, 0:1] #按行索引,列名访问 df.at[0, 'name'] #修改列名 df.columns df.columns=['age2', 'name2'] #修改行索引 df.index df.index = range(1,4) df.index #根据行索引删除 df.drop(1, axis=0) #默认参数axis=0 #根据列名进行删除 df.drop('age2', axis=1) #第二种删除列的方法 del df['age2'] #增加行,注意,这种方法,效率非常低,不应该用于遍历中 df.loc[len(df)] = [24, "KENKEN"]; #增加列 df['newColumn'] = [2, 4, 6, 8];
程序结构:

分别有顺序结构、选择结构、循环结构。
选择结构例子如下:
""" if 判断条件: 执行语句…… else: 执行语句…… """ flag = False name = 'luren' if name == 'python': # 判断变量否为'python' flag = True # 条件成立时设置标志为真 print('welcome boss') # 并输出欢迎信息 else: print(name) # 条件不成立时输出变量名称 num = 5 if num == 3: # 判断num的值 print('boss') elif num == 2: print('user') elif num == 1: print('worker') elif num < 0: # 值小于零时输出 print('error') else: print('roadman') # 条件均不成立时输出
循环结构例子如下:
# -*- coding: utf-8 -*- """ Created on Sat Sep 26 18:55:41 2015 @author: TBKKEN """ #!/usr/bin/python # -*- coding: UTF-8 -*- from pandas import Series; from pandas import DataFrame; for i in range(10): print('现在是: ', i) for i in range(3, 10): print(i) #遍历字符串 for letter in 'Python': print ('现在是 :', letter) #遍历数组 fruits = ['banana', 'apple', 'mango'] for fruit in fruits: print ('现在是 :', fruit) #遍历序列 x = Series(['a', True, 1], index=['first', 'second', 'third']); x[0]; x['second']; x[2]; for v in x: print("x中的值 :", v); for index in x.index: print("x中的索引 :", index); print("x中的值 :", x[index]); print("---------------------") #遍历数据框 df = DataFrame({ 'age': Series([21, 22, 23]), 'name': Series(['KEN', 'John', 'JIMI']) }); #遍历列名 for r in df: print(r); #遍历列 for cName in df: print('df中的列 : ', cName) print('df中的值 : ', df[cName]); print("---------------------") #遍历行,方法一 for rIndex in df.index: print('现在是第 ', rIndex, ' 行') print(df.irow(rIndex)) #遍历行,方法二 for r in df.values: print(r) print(r[0]) print(r[1]) print("---------------------") #遍历行,方法三 for index, row in df.iterrows(): print('第 ', index, ' 行:') print(row) print("---------------------")
向量化计算:
定义:向量化计算是一种特殊的并行计算的方式,它可以在同一时间执行多次操作,通常是对不同的数据执行同样的一个或一批指令,或者说把指令应用于一个数组/向量。




# -*- coding: utf-8 -*- """ Created on Wed Mar 23 10:13:56 2016 @author: TBKKEN """ #生成一个整数的等差序列 #局限,只能用于遍历 r1_10 = range(1, 10, 2) for i in r1_10: print(i) r1_10 = range(0.1, 10, 2) #生成一个小数的等差序列 import numpy numpy.arange(0.1, 0.5, 0.01) r = numpy.arange(0.1, 0.5, 0.01) #向量化计算,四则运算 r + r r - r r * r r / r #长短不一时 r + 1 #函数式的向量化计算 numpy.power(r, 5) #向量化运算,比较运算 r>0.3 #结合过滤进行使用 r[r>0.3] #矩阵运算 numpy.dot(r, r.T) sum(r*r) from pandas import DataFrame df = DataFrame({ 'data1': numpy.random.randn(5), 'data2': numpy.random.randn(5) }) df.apply(lambda x: min(x)) df.apply(lambda x: min(x), axis=1) #判断每个行,值是否都大于0 df.apply(lambda x: numpy.all(x>0), axis=1) #结合过滤 df[df.apply(lambda x: numpy.all(x>0), axis=1)]