当查询被提交时,SQL Server检查过程缓冲中匹配的执行计划,如果没有找到,SQL Server执行查询编译和优化以生成新的执行计划。
如果执行计划存在于缓冲中,它在私有的执行上下文中重用,这节约了CPU的编译和优化周期。
具有不同过滤条件的相同查询提交到SQL Server时,如:
SELECT * FROM Person WHERE Id = 1
当这个查询被提交时,优化器创建一个执行计划并将其存储在过程缓冲中以被将来重用。如果这个查询使用不同的过滤条件,如:WHERE Id = 2重新提交,重用前面提供的过滤条件值所用的现有执行计划是有利的。但是为一个过滤条件值创建的执行计划是否可以重用于另一个过滤条件值,取决于查询提交到SQL Server的方式。
提交到SQL Server的查询分为以下两类:
- 即席的(Ad Hoc);
- 预定义的(Prepared);
一、即席工作负载
查询可以在不隔离变量的情况下提交到SQL Server。这种不明确地将查询可变部分转换成参数而执行的查询被称为即席工作负载(ad hoc workloads)。
执行如下查询:
SELECT * FROM Person WHERE Id = 1
如果查询按原样提交,没有明确地转换变量为参数,则这是一个即席查询。
对于这种情况,除非使用相同的变量,否则不能重用查询计划。
二、预定义工作负载
预定义(Prepared)工作负载明确地参数化查询的可变部分,这样查询计划不与可变部分的值绑定。在SQL Server中,查询可以使用以下3种方法作为预定义工作负载提交:
- 存储过程:允许保存一个能够接受并返回用户提供的参数的SQL语句集合;
- sp_executesql:允许执行一个SQL语句或一个SQL批,可以包含用户提供的参数;
- 准备/执行模式:允许SQL客户请求生成能够在随后不同参数值的查询执行期间重用的查询计划,不在SQL Server中保存SQL语句;
对于前面所示的SQL语句可以明确地使用以下的存储过程参数化:
CREATE PROC InsertPerson1 @Id int AS SELECT * FROM Person WHERE PersonId = @Id
包含在存储过程中的SELECT语句计划将嵌入参数@Id不是变量值。
三、即席工作负载的计划可重用性
当查询作为一个即席的工作负载被提交,SQL Server生成一个执行计划并根据生成这个执行计划的开销来决定是否缓冲该计划。如果生成执行计划的开销非常经济,SQL Server可能根据可用资源不缓冲该计划以保持过程缓冲的大小。SQL Server在查询重新提交时重新生成执行计划,而不用经济的继续查询充满过程缓冲。
对于生成执行计划较高的即席查询,SQL Server在过程缓冲中保存执行计划。即席查询可变部分的值被包含在查询计划中而没有单独地保存在执行上下文中,这意味着,除非使用所看到的完全相同的变量,否则无法重用这个执行计划。
动手写个示例:
DBCC FREEPROCCACHE --清除执行计划缓存 SELECT * FROM PersonHunderThousand WHERE Id = 1 --此句点击执行两次 SELECT * FROM PersonHunderThousand WHERE Id = 2
下面运行如下语句:
SELECT text,refcounts,usecounts,objtype,cacheobjtype FROM sys.dm_exec_cached_plans as p CROSS APPLY sys.dm_exec_sql_text(p.plan_handle)
看到输出结果:

留意到上面的结果:对于两个不同的Id查询条件,SQL Server生成了两个执行计划。而且根据使用次数usecounts看出,Id=1与Id=2的查询计划并不重用。
这种即席查询的执行计划重用效率低下,增加了CPU的负载,因为消耗了附加的CPU周期来重新生成计划。总而言之,即席计划缓冲使用语句级的缓冲并且被限制为精确文本匹配。但是对于以上这种简单查询(只涉及到一个表),SQL Server有个称为"简单参数化"的特性,能够进行隐式地进行查询参数化以增进计划可重用性。但是只限于查询非常简单的情况,如只涉及到一个表。
1、优化即席工作负载
如果服务器主要用来支持即席查询,那么只能得到很低程度的性能改善。有一个服务器选项被称为optimize for ad hoc workloads(优化即席工作负载),为服务器启用这个选项改变引擎处理即席查询的方式。在查询第一次被调用时不生成完整的编译计划,而是创建一个编译计划存根(compiled plan stub)。这个存根没有相关的完整执行计划,节省了生成执行计划的事件和所需要的存储空间。这个选项可以在不重用服务器的情况下使用:
修改这个选项之后,刷新缓冲,然后重新运行查询:
EXEC sp_configure 'show advanced options',1 --要开启这个高级选项,才能开启下面 RECONFIGURE EXEC sp_configure 'optimize for ad hoc workloads',1 --开启即席优化负载 RECONFIGURE --清除执行计划缓存 DBCC FREEPROCCACHE --再次执行这个语句,但是换了个Id为3 SELECT * FROM PersonHunderThousand WHERE Id = 3 SELECT text,refcounts,usecounts,objtype,cacheobjtype,size_in_bytes FROM sys.dm_exec_cached_plans as p CROSS APPLY sys.dm_exec_sql_text(p.plan_handle)
显示结果如下:
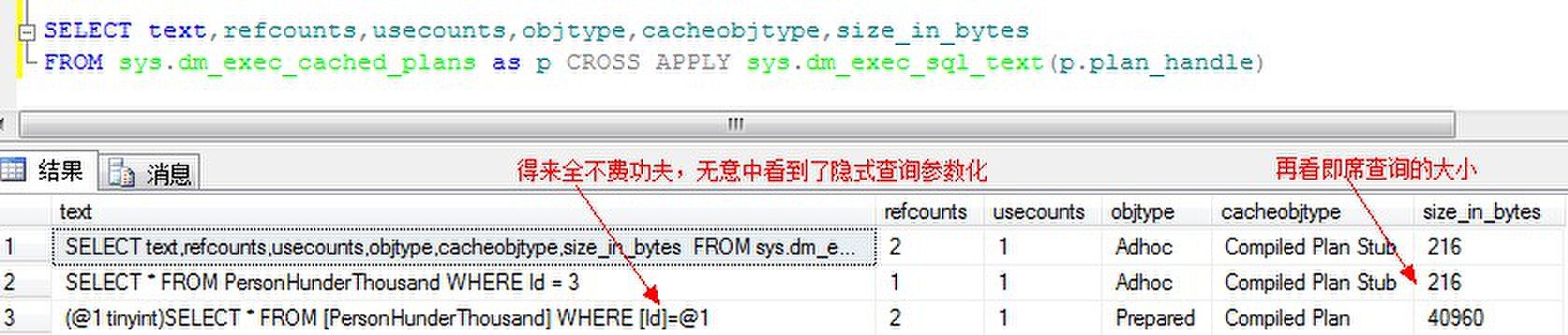
从保存到执行计划缓冲中的大小可以看到非常小,实际上这时存储在缓冲中的对象是一个编译计划的存根,可以为许多查询创建存根而对服务器的影响小于完整的编译计划,但是下次执行即席查询时,创建一个完整的编译计划。
so,还等什么,再次执行:
SELECT * FROM PersonHunderThousand WHERE Id = 3
来看结果:
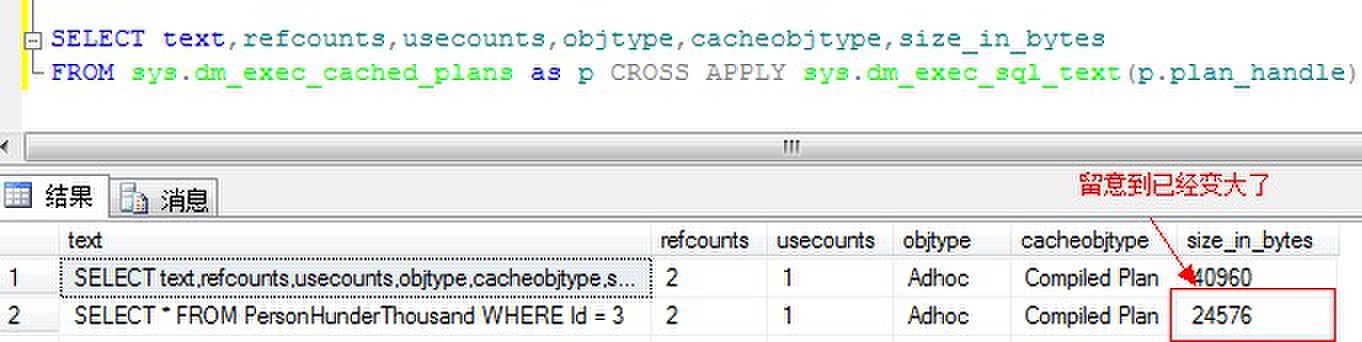
留意到存储进缓冲的到size已经变大了不少,第二次之后之后,这时候存储进去的已经变成了完整的编译计划,执行计划,也创建了一个新的句柄。
这说明了在使用许多即席查询时的节省。
2、简单参数化
提交一个即席查询时,SQL Server分析查询以确定输入文本的哪个部分可能是参数。它查看即席查询的可变部分,以确定是否可以安全地自动参数化它们,并在查询中使用这些参数以使查询计划独立于变量值。这种在没有明确地参数化(使用预定义工作负载技术)时自动转换查询的可变部分的特性被称为简单参数化。
在参数化期间,SQL Server去报如果即席查询转换为一个参数化模板,参数值的修改不会广泛地改变计划的需求。确定简单参数安全之后,SQL Server为一个即席查询创建一个参数化模板并将参数化计划保存在过程缓冲。
参数计划不基于用于查询中的动态值(管你Id=1,Id=2)。因为该计划为参数化模板(Id=x)所生成,它可以在即席查询以可变部分的不同值重新执行时被重用。
示例,按顺序点击一次如下查询:
--清除执行计划缓存 DBCC FREEPROCCACHE --再次执行这个语句,但是换了个Id为3 SELECT * FROM PersonHunderThousand WHERE Id = 4 SELECT text,refcounts,usecounts,objtype,cacheobjtype,size_in_bytes FROM sys.dm_exec_cached_plans as p CROSS APPLY sys.dm_exec_sql_text(p.plan_handle)
再来看看输出:

留意到红框部分,这个是自动生成的,现在看到该自动生成的执行计划的使用数量为1,要注意,这一行的自动参数化的可执行计划的objtype不再是Adhoc(即席的),而是Prepared(预定义的)。
我们来执行如下查询:
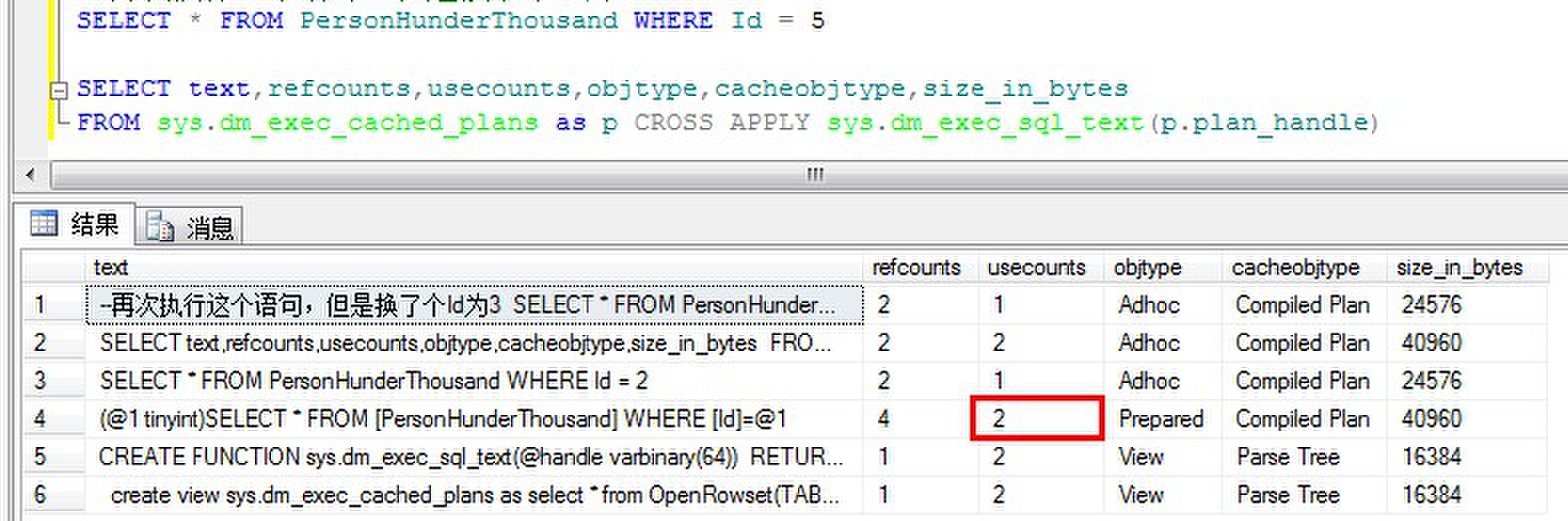
看到,Id虽然不同,但是参数计划的usecounts还是由1变为了2。该参数计划被重用了。但是依然会生成一个新Id的即席计划。当Id与现有所有的即席计划不同时,参数计划会use一次,当Id与现有计划匹配时,参数计划不会使用,匹配的即席计划会use一次。
原来的即席查询尽管不被执行,但是被编译以创建查询简单参数化所需的查询树。根据可用的资源,即席查询的编译计划可能会被保存在计划缓冲中。但是在创建即席查询的可执行计划之前,SQL Server判断自动化参数是安全的,然后自动参数化这个查询以进行进一步处理。
另外,当即席查询可以安全地自动参数化时,SQL Server选择一种可以代替查询原样的文字模板。
如,执行以下查询:
SELECT * FROM PersonHunderThousand WHERE Id BETWEEN 5 AND 15
SQL Server生成的参数计划如下:
![]()
我们看到上面自动生生的参数计划,SQL Server选择了使用>=和<=来代替BETWEEN AND。
这时候,即使使用》= 《=作为查询条件也一样可以重用参数计划。如:
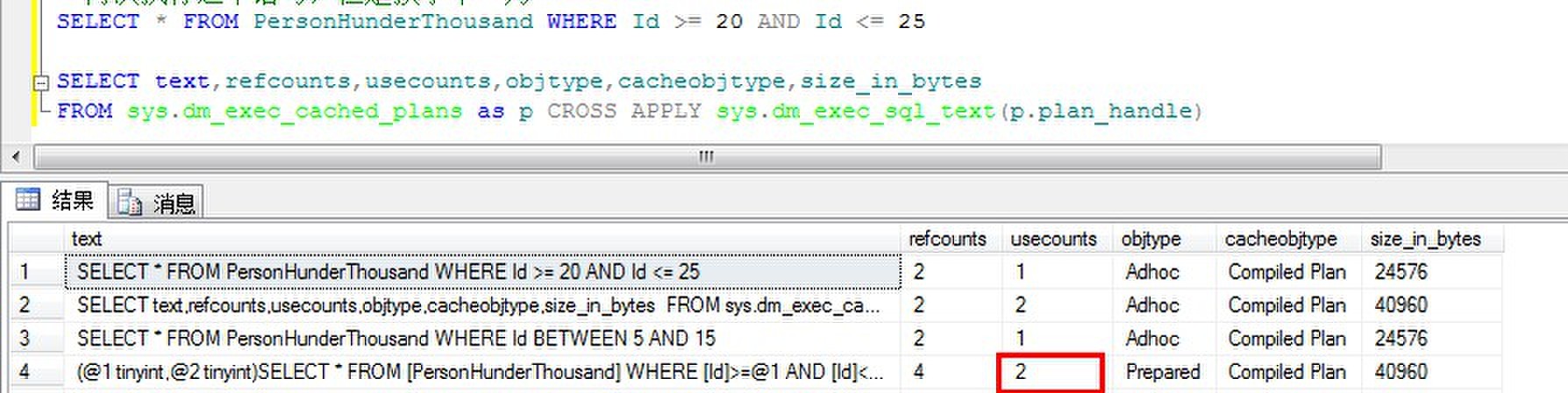
从usecounts可以看到,现有计划被重用了,尽管该查询和前面执行的语法不一样,SQL Server生成的自动参数化计划允许现有计划不仅在查询以不同变量值重新提交时重用,而且可以用于使用相同模板形式的查询。
3、简单参数化的局限
SQL Server在简单参数化中非常保守,因为不好的计划的开销可能远远超过生成一个新的计划的开销。因而,简单参数化被限于相当简单的情况,如只使用一个表的即席查询。有两个或更多表之间连接操作的即席查询不会自动生成参数化计划。
4、强制参数化
如果工作的系统主要由即席查询组成,你可能希望尝试增加接收参数的查询数量。可以修改数据库来尝试在一定的限制之内,强制所有查询像简单参数化中那样被参数化。可以使用ALTER DATABASE修改数据库选项PARAMETERIZATION为FORCED。
方法如下:
ALTER DATABASE DataExample SET PARAMETERIZATION FORCED/SIMPLE --强制所有查询像简单参数化那样参数化/使用简单参数化
测试,我们先执行如下语句(在之前先别执行上面那行语句):
SELECT * FROM PersonHunderThousand as per INNER JOIN Province as pro ON per.PId = pro.Id WHERE per.Name = '干鸥粕' SELECT text,refcounts,usecounts,objtype,cacheobjtype,size_in_bytes FROM sys.dm_exec_cached_plans as p CROSS APPLY sys.dm_exec_sql_text(p.plan_handle)
显示结果如下:

因为上面的查询INNER JOIN了一个表,所以并没有简单参数化缓冲一个参数计划。而是直接缓冲了一个即席计划。
假如我们清空执行计划缓冲,然后强制参数化呢?
ALTER DATABASE DataExample SET PARAMETERIZATION FORCED --强制所有查询像简单参数化那样参数化
再执行以上的语句:
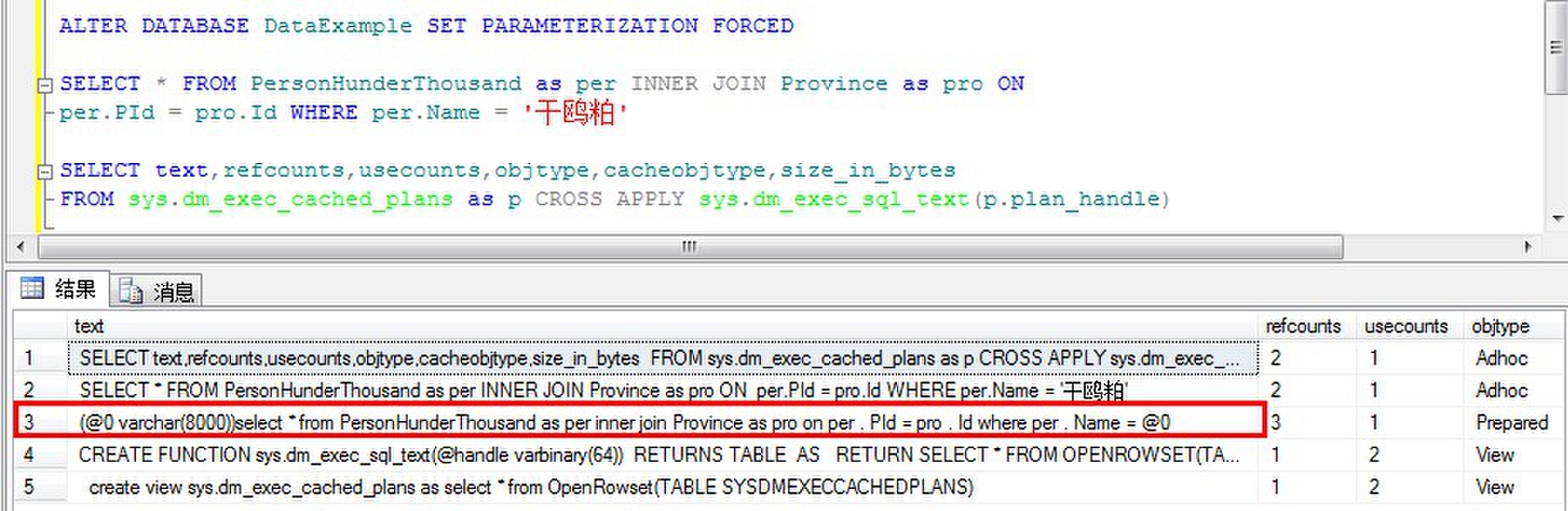
可见,对于原本并不简单参数化的查询,现在也生成了一个参数化计划。
强制参数化可以替代字符串参数'干鸥粕',变量声明长度为8000的VARCHAR,而不是类似查询参数的NCHAR(3),这样可以应用于更多查询。这样可能导致阻止索引使用的隐含数据转换。
强制参数化实际上只对苦于即席查询的大量编译和重编译的情况有帮助,其他负载将不会从使用强制参数化中获益。
四、预定义工作负载的计划可重用性
将查询定义为预定义工作负载允许查询的可变部分明确地参数化。这使SQL Server能生成一个不绑定到查询可变部分的查询计划,使可变部分独立于执行上下文中。
SQL Server支持3中技术来提交预定义工作负载:
- 存储过程;
- sp_executesql;
- 准备/执行(Prepare/execute)模式;
1、存储过程;
使用存储过程是改进计划缓冲效率的标准技术。当存储过程被编译时,为所有过程中的SQL语句生成一个组合的计划。为存储过程生成的执行计划可以在存储过程以不同参数值重新执行时重用。
除了检查sys.dm_exec_cached_plans外,还可以使用Profiler工具跟踪存储过程的执行计划缓冲,下面的事件用于跟踪存储过程的执行计划。
| 事件 | 描述 |
| SP:CacheHit | 缓冲中找到的计划 |
| SP:CacheMiss | 缓冲中没有找到的计划 |
| SP:ExecContextHit | 缓冲中找到的存储过程执行上下文 |
为了使用Profiler跟踪存储过程计划缓冲,可以将这些事件和表9-3所示的其他存储过程事件和数据列一起使用。
| 事件 | 数据列 |
| SP:CacheHit | EventClass |
| SP:CacheMiss | TextData |
| SP:Completed | LoginName |
| SP:ExecContextHit | SPID |
| SP:Starting | StartTime |
| SP:StmtCompleted |
创建一个存储过程如下:
CREATE PROC getPerson @Id INT AS SELECT * FROM PersonTenThousand INNER JOIN Province ON PersonTenThousand.PId = Province.Id WHERE PersonTenThousand.Id = @Id
--并执行一次
EXEC getPerson @Id = 6678
来看sys.dm_exec_cached_plans的输出:

该存储过程创建并缓冲了一个类型为Proc的编译计划。执行的usecounts为1,因为存储过程只执行一次。
我们来看看执行这个存储过程SQL Profiler捕捉到的输出:

从Profiler跟踪输出,可以看到存储过程的计划在缓冲中没有找到。当存储过程第一次执行时,SQL Server查找过程缓冲并且找不到用于gerPerson过程的缓冲条目,导致了一个SP:CacheMiss事件。没有找到缓冲计划时,SQL Server安排编译该存储过程,随后SQL Server生成并保存计划并且继续执行该存储过程。
如果这个存储过程重新执行以检索@Id = 9876:
EXEC getPerson @Id = 9876
现有计划被重用,如sys.dm_exec_cached_plans所示:

可以从Profiler跟踪输出确认执行计划的重用:
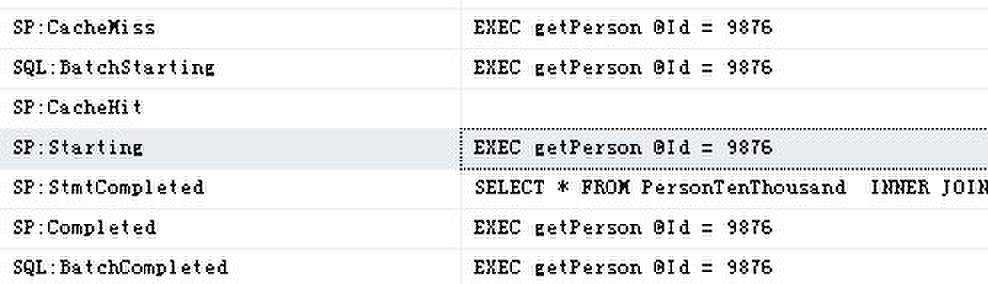
从Profiler跟踪输出可以看到,现有的计划在过程缓冲中找到。在搜索缓冲时,SQL Server找到存储过程p1所用的执行计划并导致一个SP:CacheHit事件。一旦找到现有的执行计划,SQL重用该查询以执行存储过程。
存储过程值得考虑的其他一些方面:
- 存储过程在第一次执行时编译;
- 存储过程有其他性能上的好处,如降低网络流量;
- 存储过程有附加的好处,如数据隔离;
2、存储过程在第一次执行时编译
存储过程的执行计划在第一次执行时生成。存储过程创建时,它只被解析并且保存在数据库中。在存储过程创建期间没有执行任何规范化和优化过程,这使存储过程可以在其访问的对象创建之前创建。
例如,可以创建一个存储过程如下,即使表Person不存在也能创建:
CREATE PROC getPerson @Name nvarchar(50) AS SELECT * FROM Person WHERE Name = @Name
因为该引用对象绑定到查询树(在存储过程执行期间由命令解析器生成)的规范化过程在存储过程创建时没有执行。存储过程将在第一次执行时报告错误(如果执行时仍然没有Person表),因为第一次执行时编译该存储过程。
3、存储过程在性能上的其他好处
除了通过执行计划可重用性改进性能之外,存储过程还提供以下性能上的好处。
- 业务逻辑靠近数据:执行保存在数据库中的数据上的广泛操作的业务逻辑部分应该放在存储过程中,因为SQL Server的引擎对于关系和集合操作来说是极其强大的。
- 降低网络流量:跨越网络的数据库应用程序只发送存储过程的名称和变量值。只有处理过的结果集被返回到应用程序,中间数据部需要在应用程序和数据库之间来回传递。
sp_executesql是一个系统存储过程,它提供了将一个或多个查询作为预定义工作负载提交的机制。它允许查询的可变部分明确地参数化,从而提供和存储过程同样有效的执行计划可重用性。NHibernate生成的SQL语句就是这种。注意,sp_executesql的SQL语句是要求NVARCHAR类型的。
如:
DECLARE @query NVARCHAR(MAX) DECLARE @param NVARCHAR(MAX) SET @query = N'SELECT * FROM PersonTenThousand AS P1 INNER JOIN Province AS P2 ON P1.PId = p2.Id WHERE p1.Id = @Id' SET @param = N'@Id INT' EXEC sp_executesql @query,@param,@Id = 9888
对于SQL语句,传递给sp_executesql存储过程的字符串被声明为NVARCAHR并且带有前缀N。这是因为,sp_executesql使用Unicode字符串作为输入参数。
接下来,看看sys.em_exec_cached_plans的输出:

从第二行中看到,为通过sp_executesql提交的查询参数化部分生成的计划。因为该计划没有绑定到查询的可变部分,所以如果查询以参数的不同值重新提交,现有的执行计划可以被重用。
DECLARE @query NVARCHAR(MAX) DECLARE @param NVARCHAR(MAX) SET @query = N'SELECT * FROM PersonTenThousand AS P1 INNER JOIN Province AS P2 ON P1.PId = p2.Id WHERE p1.Id = @Id' SET @param = N'@Id INT' EXEC sp_executesql @query,@param,@Id = 777
sys.em_exec_cached_plans的输出:

由usecounts看出,这个参数查询计划被重用了。如果这个查询以可变部分的不同值被重新提交许多次,现有的执行计划可以被重用而不用重新生成新的执行计划。
这里要注意,所创建的目标查询语句与通过sp_executesql提交的参数化查询的文本串匹配。因此,如果相同的查询从应用程序的不同部分提交,需确保所有地方都使用相同的文本串。
对于上面的例子,我们将where改成小写再提交:
DECLARE @query NVARCHAR(MAX) DECLARE @param NVARCHAR(MAX) SET @query = N'SELECT * FROM PersonTenThousand AS P1 INNER JOIN Province AS P2 ON P1.PId = p2.Id where p1.Id = @Id' SET @param = N'@Id INT' EXEC sp_executesql @query,@param,@Id = 7777
输出如下:
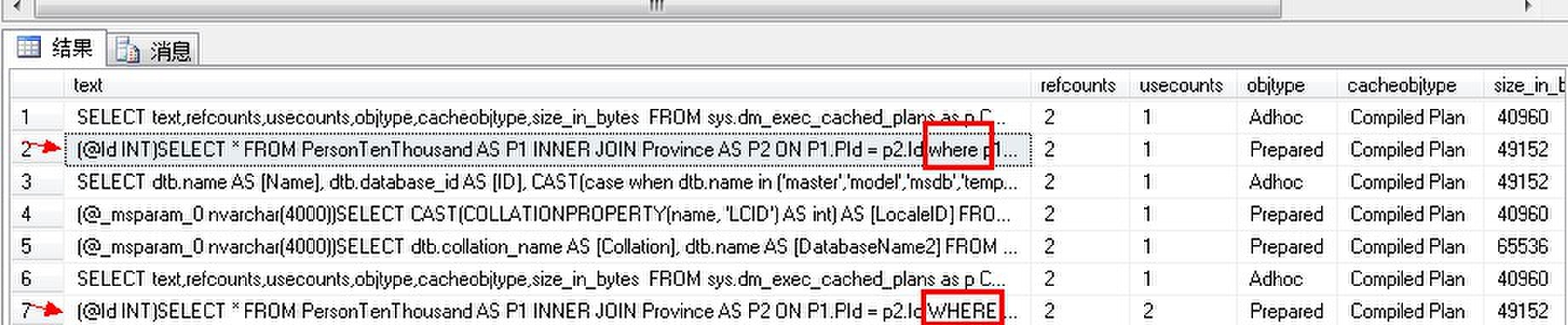
由以上的计划我们可以看到,对于改变了一个单词的查询语句,现有计划不被重用,而是创建一个新的计划。
一般来说,使用sp_executesql明确地参数化查询,使其执行计划在查询以可变部分的不同值重新提交时可重用。这提供了可重用计划在性能上的好处,而没有管理存储过程所需要的持续性对象的开销。这个特性分别由ODBC和OLEDB通过SQLExecDirect和ICommandWithParameters发布。Ado.net可以使用ADO的Command命令和Parameters(参数)提交前述的SELECT语句。如果ADO的Command Prepared属性设置为FALSE并使用ADO Command('SELECT * FROM "Order Details" d, ORDER o WHERE d.OrderId = o.OrderID and d.ProductID=?')和ADO Parameters,ADO.NET将使用sp_executesql发送SELECT语句。
简单的Ado.netDEMO
static void Main(string[] args) { string str = "server=KISSDODOG-PC;database=DataExample;uid=sa;pwd=123"; SqlConnection conn = new SqlConnection(str); SqlCommand cmd = conn.CreateCommand(); cmd.CommandText = "SELECT TOP 1 Name FROM PersonTenThousand WHERE Id = @Id"; //设置操作语句 cmd.Parameters.Add("@Id", SqlDbType.Int); cmd.Parameters["@Id"].Value = 1; string Name = ""; conn.Open(); Name = cmd.ExecuteScalar().ToString(); conn.Close(); Console.WriteLine(Name); Console.ReadKey(); }
SQL Server Profiler监控到的输出如下:
![]()
5、准备/执行(Prepare/execure)模式
ODBC和OLEDB提供一种准备/执行模式来将查询作为一个预定义工作负载提交。和sp_executesql类似,这种模式允许查询的可变部分明确地参数化。准备阶段允许SQL Server为查询生成执行计划,并返回执行计划的一个句柄给应用程序。这个执行计划句柄被执行阶段以不同的参数值执行查询。这种模式只能用于通过ODBC或OLEDB提交查询,且不能用在SQL Server本身内部-存储过程中的查询不能使用这种模式执行。
SQL ServerODBC驱动程序提供SQLPrepare和SQLExecuteAPI以支持准备/执行模式。SQL Server OLEDB Provider通过ICommandPrepare接口发布这种模式。ADO.NET的OLEDB.NET provider表现与此类似。
6、参数嗅探
虽然一个精心定义的工作负载的目标是将被重用的计划放入缓冲中,但是有可能将不希望重用的计划放入缓冲中。当过程第一次被SQL Server调用时,所用的值即被作为生成计划的一部分,如果这些值是数据和统计的代表,那么你将会获得一个有利于存储过程大部分执行的良好计划。但是,如果这些数据有所变形,它将可能严重地影响查询的性能。
(这个示例比较难写,先想想)
有时,对于变换存储过程中的参数,缓冲中的执行计划可能对查询性能是一种伤害,因为对于不同的参数,实际上使用不同的执行计划更好。。如果你确认某个计划有时工作得好,但是有时在变换参数的时候性能不佳,可以用以下方法避免和修复这个问题:
- 可以在执行过程之前对其运行sp_recompile来在执行时强制重新编译计划,或者每当它执行时使用WITH RECOMPILE选项使其重新编译。
- 重新将输入参数赋给本地参数。这种流行的修复方法强制优化器查询所引用数据的统计来对可能使用的值做出好的猜测,这可能也确实减少了需要考虑的值。这种方案的问题在于减少了所考虑的值。过程执行总体情况可能变得更糟糕。
- 可以在创建过程时使用查询提示OPTIMIZE FOR,并且供给它好的参数以生成在大部分查询中工作良好的计划。但是,要理解,一定比例的查询将不能很好地在所提供的参数下工作。
- 可以使用计划向导,这是使查询以某种方式表现而不需修改过程的一个机制。