Keras是基于Tensorflow(以前还可以基于别的底层张量库,现在已并入TF)的高层API库。它帮我们实现了一系列经典的神经网络层(全连接层、卷积层、循环层等),以及简洁的迭代模型的接口,让我们能在模型层面写代码,从而不用仔细考虑模型各层张量之间的数据流动。
但是,当我们有了全新的想法,想要个性化模型层的实现时,仅靠Keras的高层API是不能满足这一要求的。下面记录使用TF与Keras快速搭建神经网络模型。
自定义网络层
实现往Keras的Model类中添加自定义层,有两种方式:
1、定义Lambda层。
2、继承Layer类。
lambda层
Lambda层仅能对输入做固定的变换,并不能定义可以通过反向传播训练的参数(通过Keras的fit训练),因此能实现的东西较少。以下代码实现了Dropout的功能:
from keras import backend as K from keras import layers def my_layer(x): mask = K.random_binomial(K.shape(x),0.5) return x*mask*2 x = layers.Lambda(my_layer)(x)
其中my_layer函数是自定义层要实现的操作,传递参数只能是Lambda层的输入。定义好函数后,直接在layers.Lambda中传入函数对象即可。实际上,这些变换不整合在lambda层中而直接写在外面也是可以的:
from keras import backend as K from keras import layers x = layers.Dense(500,activation='relu')(x) mask = K.random_binomial(K.shape(x),0.5) x = x*mask*2
更新:这样做在Keras最新版本已经不支持了,只支持Lambda层了。
以上实现Dropout只是作举例,你可以以同样的方式实现其它的功能。
继承layer类
如果你想自定义可以训练参数的层,就需要继承实现Keras的抽象类Layer。主要实现以下三个方法:
1、__init__(self, *args, **kwargs):构造函数,在实例化层时调用。此时还没有添加输入,也就是说此时输入规模未知,但可以定义输出规模等与输入无关的变量。类比于Dense层里的units、activations参数。
2、build(self, input_shape):在添加输入时调用(__init__之后),且参数只能传入输入规模input_shape。此时输入规模与输出规模都已知,可以定义训练参数,比如全连接层的权重w和偏执b。
3、call(self, *args, **kwargs):编写层的功能逻辑。
单一输入
当输入张量只有一个时,下面是实现全连接层的例子:
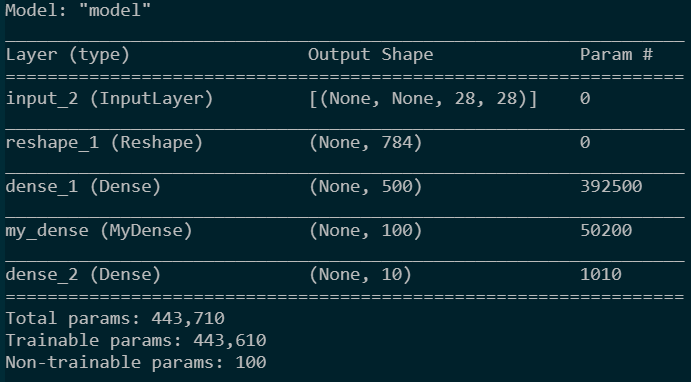
import numpy as np from keras import layers,Model,Input,utils from keras import backend as K import tensorflow as tf class MyDense(layers.Layer): def __init__(self, units=32): #初始化 super(MyDense, self).__init__()#初始化父类 self.units = units #定义输出规模 def build(self, input_shape): #定义训练参数 self.w = K.variable(K.random_normal(shape=[input_shape[-1],self.units])) #训练参数 self.b = tf.Variable(K.random_normal(shape=[self.units]),trainable=True) #训练参数 self.a = tf.Variable(K.random_normal(shape=[self.units]),trainable=False) #非训练参数 def call(self, inputs): #功能实现 return K.dot(inputs, self.w) + self.b #定义模型 input_feature = Input([None,28,28]) x = layers.Reshape(target_shape=[28*28])(input_feature) x = layers.Dense(500,activation='relu')(x) x = MyDense(100)(x) x = layers.Dense(10,activation='softmax')(x) model = Model(input_feature,x) model.summary()
utils.plot_model(model)
模型结构如下:
 |
 |
在build()中,训练参数可以用K.variable或tf.Variable定义。并且,只要是用这两个函数定义并存入self中,就会被keras认定为训练参数,不管是在build还是__init__或是其它函数中定义。但是K.variable没有trainable参数,不能设置为Non-trainable params,所以还是用tf.Variable更好更灵活些。
多源输入
如果输入包括多个张量,需要传入张量列表。实现代码如下:
import numpy as np from keras import layers,Model,Input,utils from keras import backend as K import tensorflow as tf class MyLayer(layers.Layer): def __init__(self, output_dims): super(MyLayer, self).__init__() self.output_dims = output_dims def build(self, input_shape): [dim1,dim2] = self.output_dims self.w1 = tf.Variable(K.random_uniform(shape=[input_shape[0][-1],dim1])) self.b1 = tf.Variable(K.random_uniform(shape=[dim1])) self.w2 = tf.Variable(K.random_uniform(shape=[input_shape[1][-1],dim2])) self.b2 = tf.Variable(K.random_uniform(shape=[dim2])) def call(self, x): [x1, x2] = x y1 = K.dot(x1, self.w1)+self.b1 y2 = K.dot(x2, self.w2)+self.b2 return K.concatenate([y1,y2],axis = -1) #定义模型 input_feature = Input([None,28,28])#输入 x = layers.Reshape(target_shape=[28*28])(input_feature) x1 = layers.Dense(500,activation='relu')(x) x2 = layers.Dense(500,activation='relu')(x) x = MyLayer([100,80])([x1,x2]) x = layers.Dense(10,activation='softmax')(x) model = Model(input_feature,x) model.summary() utils.plot_model(model,show_layer_names=False,show_shapes=True)
模型结构如下:
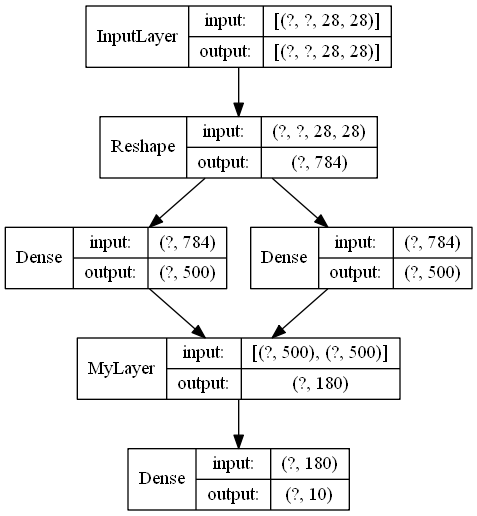
总之,传入张量列表,build传入的input_shape就是各个张量形状的列表。其它都与单一输入类似。
自定义损失函数
下面介绍使用keas的fit函数训练模型时,我们可以使用的自定义模型损失的方式。
根据Keras能添加自定义损失的特性,这里将添加损失的方法分为两类:
1、损失需要根据模型输出与真实标签来计算,也就是只有模型的输出与外部真实标签作为计算损失的参数。
2、损失无需使用外部真实标签,也就是只用模型内部各层的输出作为计算损失的参数。
这两类损失添加的方式并不一样,希望以后Keras能把API再改善一下,这种冗余有时让人摸不着头脑。
第一类损失
这类损失可以通过自定义函数的形式来实现。函数的参数必须是两个:真实标签与模型输出,不能多也不能少,并且顺序不能变。然后你可以在这个函数中定义你想要的关于输出与真实标签之间的损失。然后在model.compile()中将这个函数对象传给loss参数。代码示例如下(参考链接):
def customed_loss(true_label,predict_label): loss = keras.losses.categorical_crossentropy(true_label,predict_label) loss += K.max(predict_label) return loss model.compile(optimizer='rmsprop', loss=customed_loss)
对于多输出模型,loss可以定义多个,然后以列表或字典的形式传入。传列表形式如下:
def customed_loss1(true_label,predict_label): loss = ... return loss def customed_loss2(true_label,predict_label): loss = ... return loss model.compile(optimizer='rmsprop', loss=[customed_loss1,customed_loss2])
其中loss列表中loss的数量和顺序要与模型输出的数量和顺序一致,不能少传或多传。传字典的形式更明确一些,但是要给每个输出定义name属性,具体方法请看:
针对keras模型多输出或多损失方法使用_树莓派-CSDN博客
如果仅仅传入一个loss,不被列表或字典所包含,keras会让所有输出都使用同一个loss函数。
另外,很重要的一点是,不论自定义loss函数传出的是什么形状的张量(keras fit时传入loss的是带有批量维度的张量),经过测试,我发现,keras会对这个张量的所有元素求一个均值以获得这个loss的最终输出标量。
第二类损失
这类损失可以用Model.add_loss(loss)方法实现,loss可以使用Keras后端定义计算图来实现。但是显然,计算图并不能把未来训练用的真实标签传入,所以,add_loss方法只能计算模型内部的“正则化”损失。
add_loss方法可以使用多次,损失就是多次添加的loss之和。使用了add_loss方法后,compile中就可以不用给loss赋值,不给loss赋值的话使用fit()时就不能传入数据的标签,也就是y_train。如果给compile的loss赋值,最终的目标损失就是多次add_loss添加的loss和compile中loss之和。另外,如果要给各项损失加权重的话,直接在定义loss的时候加上即可。代码示例如下:
loss = 100000*K.mean(K.square(somelayer_output))#somelayer_output是定义model时获得的某层输出 model.add_loss(loss) model.compile(optimizer='rmsprop')
以上讲的都是关于层输出的损失,层权重的正则化损失并不这样添加,自定义正则项可以看下面。
keras中添加正则化_Bebr的博客-CSDN博客_keras 正则化
里面介绍了已实现层的自定义正则化,但没有介绍自定义层的自定义正则化,这里先挖个坑,以后要用再研究。
自定义模型
以上介绍的都是基于Keras已实现的方法来定义模型的结构与损失,这种方式要在完全建立好模型之后才能获取模型的输出信息,模型结构一复杂就很不容易查找bug,并且一些复杂的loss并不好定义(比如WGAN-GP的GP)。而Tensorflow2.0更新后默认为eager模式,因此不用建立完整的数据流图就能计算模型的中间结果,很方便。下面是通过重写Keras的Model类来实现自定义模型的代码:
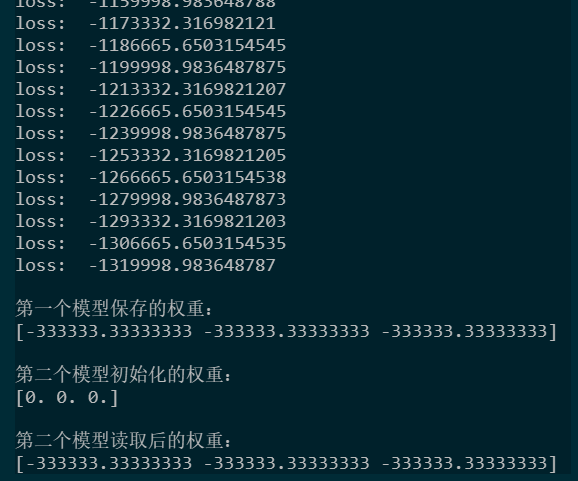
import numpy as np import tensorflow as tf from tensorflow.keras import layers,Model,optimizers '''模型的定义与实例化''' class MyModel(Model): def __init__(self): super().__init__() #必须执行以初始化父类 self.dense1 = layers.Dense(3) self.optimizer = optimizers.SGD(10000) self.build(input_shape=(None,3))#执行build函数来确定输入形状 def call(self,inputs): return self.dense1(inputs) def loss(self,output): return tf.reduce_mean(output) def train(self,inputs): with tf.GradientTape() as tape: output = self.call(inputs) loss = tf.reduce_mean(output) print("loss: "+str(loss.numpy())) grads = tape.gradient(loss,self.trainable_weights) self.optimizer.apply_gradients(zip(grads,self.trainable_weights)) myModel = MyModel() myModel(np.random.random(size = [100,3])) #如果不执行build,Keras会以第一次传入的输入形状为基准来建立模型权重 '''模型训练''' for i in range(100): myModel.train(np.ones([10,3])) '''权重保存''' print(" 第一个模型保存的权重:") print(myModel.weights[1].numpy()) myModel.save_weights("myModel.h5")#保存权重 '''权重读取''' myModel2 = MyModel() myModel2(np.random.random(size = [100,3])) print(" 第二个模型初始化的权重:") print(myModel2.weights[1].numpy()) myModel2.load_weights("myModel.h5")#读取权重 print(" 第二个模型读取后的权重:") print(myModel2.weights[1].numpy())
简单来说就是继承Model类,然后实现其中的__init__()方法和call()方法。其中要注意优化器的输入,要用zip函数将梯度和权重一一配对,即使梯度和权重只有一个,也要先放到列表中,然后用zip进行配对。
__init__():用于定义和保存模型将要应用的层与权重,当然也能定义一些个性化的变量。
call():用于推理与训练时调用,计算输出。
正如代码中注释,实例化模型后要使用父类的build()来确定模型的输入形状,以确定整个模型的所有权重,一般可以直接在__init__()中调用。要注意的是,build()要传入元组,也就是用小括号,用中括号会报错(血的教训!)。当然不调用build()也可以,模型会以第一次传入的输入为基准来建立模型权重。
因为不是直接使用Keras内置的接口定义的模型(比如model = Model(inputs,outputs)),所以不能再使用save()来保存模型。这是因为我们把数据流动直接定义在了call()中,Keras无法得知模型的数据流动走向(它不能直接从call()中获取,我觉得有待升级)。但因为你把层存在了self中,因此可以使用save_weights()来保存层的权重(不保存计算拓扑),然后再用load_weights()读取权重,当然只有结构相同的模型才能读取。
另外,你还可以在模型中自定义loss()和train(),计算损失和更新权重。计算梯度需要将数据的流动放在tf.GradientTape()中,Tensorflow才能知道需要计算梯度的权重有哪些。上面的代码只极其简单地介绍了用法,直接对模型输出的均值进行了梯度下降。
代码输出如下:
用自定义层
与上面给Keras内置接口调用的继承Layer的自定义层不太一样(我感觉是bug),这里虽然同样也是继承自Layer,但定义权重不能用tf.Variable,不然会出现保存的权重无法读取的情况。这里使用add_weights(),代码如下:
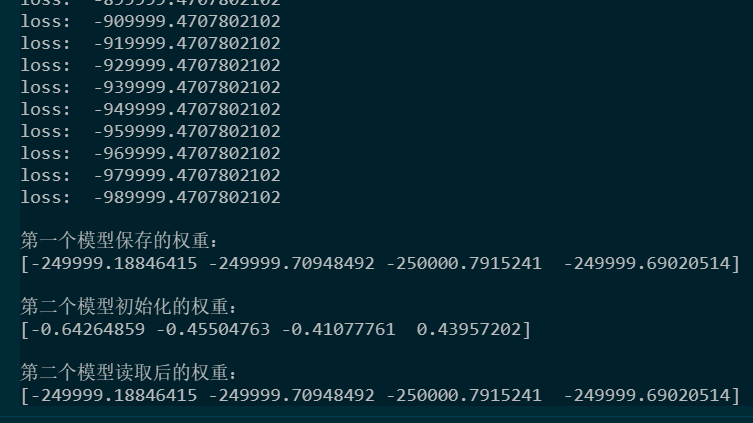
import numpy as np import tensorflow as tf from tensorflow.keras import layers,Model,optimizers class MyDense(layers.Layer): def __init__(self): super().__init__() self.w = self.add_weight(name = 'w', shape = [3, 4]) self.b = self.add_weight(name = 'b', shape = [4]) def call(self, inputs): return tf.matmul(inputs[:,tf.newaxis,:], self.w) + self.b '''模型的定义与实例化''' class MyModel(Model): def __init__(self): super().__init__() #必须执行以初始化父类 self.myDense = MyDense() self.optimizer = optimizers.SGD(10000) self.build(input_shape=(None,3))#执行build函数来确定输入形状 def call(self,inputs): return self.myDense(inputs) def loss(self,output): return tf.reduce_mean(output) def train(self,inputs): with tf.GradientTape() as tape: output = self.call(inputs) loss = tf.reduce_mean(output) print("loss: "+str(loss.numpy())) grads = tape.gradient(loss,self.trainable_weights) self.optimizer.apply_gradients(zip(grads,self.trainable_weights)) myModel = MyModel() myModel(np.random.random(size = [100,3])) #如果不执行build,Keras会以第一次传入的输入形状为基准来建立模型权重 '''模型训练''' for i in range(100): myModel.train(np.ones([10,3])) '''权重保存''' print(" 第一个模型保存的权重:") print(myModel.weights[1].numpy()) myModel.save_weights("myModel.h5")#保存权重 '''权重读取''' myModel2 = MyModel() myModel2(np.random.random(size = [100,3])) print(" 第二个模型初始化的权重:") print(myModel2.weights[1].numpy()) myModel2.load_weights("myModel.h5")#读取权重 print(" 第二个模型读取后的权重:") print(myModel2.weights[1].numpy())
输出如下:
WGAN-GP的Gradient penalty损失定义请参考链接:WGAN-GP loss定义