1.首先安装java,配置java开发环境
下载jdk:http://www.oracle.com/technetwork/java/javase/archive-139210.html选择你想要下载的版本,放入比如/home/java目录。我本机安装的是jdk 1.7
下载完成后解压:tar -zxvf xxxxxx.tar.gz
对/etc/profile文件进行配置: vim /etc/profile ,在文件的末尾添加环境变量(其中/usr/lib/jvm/java-7-oracle为解压文件的目录):
export JAVA_HOME=/usr/lib/jvm/java-7-oracle
export JRE_HOME=${JAVA_HOME}/jre
export PATH=$JAVA_HOME/bin:$PATH:
export CLASSPATH=.:$JAVA_HOME/lib:$JRE_HOME/lib
profile这个文件是每个用户登录时都会运行的环境变量设置,当用户第一次登录时,该文件被执行. 并从/etc/profile.d目录的配置文件中搜集shell的设置。
打开shell,输入java -version,显示:

2.配置ssh
配置ssh之前最好先更新一下软件源:
apt-get update
安装openssh-server:
apt-get install openssh-server
使用ssh进行无密码验证登录:
1.创建ssh-key,采用rsa方式,使用如下命令存储目录使用默认:
ssh-keygen -t rsa -P ""
2.将公钥文件追加到authorized_keys中
cat ~/.ssh/id_rsa.pub >> authorized_keys
检测ssh 服务是否启动:
ps -e | grep ssh
如果显示有ssh字样,则说明已经启动成功,如果没有则手动启动:
/etc/init.d/ssh start
也可以重启ssh server:
/etc/init.d/ssh restart
登录localhost:
ssh localhost
显示错误信息:

错误信息看起来是jdk环境变量设置有问题,也没找到改正方法。不用修改也目前看起来还没有问题。
3.下载hadoop,我下载的是hadoop-2.7.3
wget http://mirrors.hust.edu.cn/apache/hadoop/core/stable/hadoop-2.7.3.tar.gz
4.解压缩文件
tar -xzvf hadoop-2.7.3.tar.gz
5.编辑hadoop配置文件
hadoop的配置文件位于hadoop-2.7.3/etc/hadoop目录中,初始的话,需要修改core-site.xml,mapred-site.xml.template, hdfs-site.xml这三个文件
使用vim编辑这三个配置文件:
core-site.xml
<configuration>
<property>
<name>hadoop.tmp.dir</name>
<value>file:/home/hadoop/hadoop_tmp</value>
<description>Abase for other temporary directories.</description>
</property>
<property>
<name>fs.defaultFS</name>
<value>hdfs://localhost:9000</value>
</property>
</configuration>
其中<value>file:/home/hadoop/hadoop_tmp</value>是你自己设置用于hadoop的tmp目录
mapred-site.xml
<configuration>
<property>
<name>mapred.job.tracker</name>
<value>localhost:9001</value>
</property>
</configuration>
hdfs-site.xml
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/home/hadoop/hadoop_tmp/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/home/hadoop/hadoop_tmp/dfs/data</value>
</property>
</configuration>
最好把dfs.namenode.name.dir和dfs.datanode.data.dir的目录放到core-site.xml中tmp目录下
6.初始化hadoop
cd到hadoop-2.7.3根目录下,
bin/hdfs namenode -format
过程需要进行ssh验证,之前已经登录了,所以初始化过程之间键入y即可。
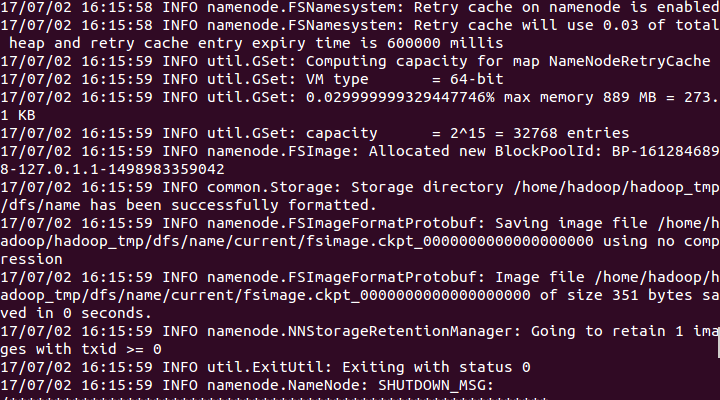
7.开启NameNode和dataNode进程
sbin/start-dfs.sh
报错:JAVA_HOME is not set and could not be found

解决方法:vim打开hadoop-2.7.3/etc/hadoop/hadoop-env.sh,直接讲JAVA_HOME加入hadoop的环境变量

使用jps查看进程信息:

在浏览器中打开http://localhost:50070

hadoop环境搭建完成。