MySQL索引的建立对于MySQL的高效运行是很重要的,索引可以大大提高MySQL的检索速度。
打个比方,如果合理的设计且使用索引的MySQL是一辆兰博基尼的话,那么没有设计和使用索引的MySQL就是一个人力三轮车。
索引分单列索引和组合索引。单列索引,即一个索引只包含单个列,一个表可以有多个单列索引,但这不是组合索引。组合索引,即一个索引包含多个列。
创建索引时,你需要确保该索引是应用在 SQL 查询语句的条件(一般作为 WHERE 子句的条件)。
实际上,索引也是一张表,该表保存了主键与索引字段,并指向实体表的记录。
上面都在说使用索引的好处,但过多的使用索引将会造成滥用。因此索引也会有它的缺点:虽然索引大大提高了查询速度,同时却会降低更新表的速度,如对表进行INSERT、UPDATE和DELETE。因为更新表时,MySQL不仅要保存数据,还要保存一下索引文件。
建立索引会占用磁盘空间的索引文件。
为什么能够提高查询速度?
索引就是通过事先排好序,从而在查找时可以应用二分查找等高效率的算法。
一般的顺序查找,复杂度为O(n),而二分查找复杂度为O(log2n)。当n很大时,二者的效率相差及其悬殊。
举个例子:
表中有一百万条数据,需要在其中寻找一条特定id的数据。如果顺序查找,平均需要查找50万条数据。而用二分法,至多不超过20次就能找到。二者的效率差了2.5万倍!
在一个或者一些字段需要频繁用作查询条件,并且表数据较多的时候,创建索引会明显提高查询速度,因为可由全表扫描改成索引扫描。
(无索引时全表扫描也就是要逐条扫描全部记录,直到找完符合条件的,索引扫描可以直接定位)
不管数据表有无索引,首先在SGA的数据缓冲区中查找所需要的数据,如果数据缓冲区中没有需要的数据时,服务器进程才去读磁盘。
1、无索引,直接去读表数据存放的磁盘块,读到数据缓冲区中再查找需要的数据。
2、有索引,先读入索引表,通过索引表直接找到所需数据的物理地址,并把数据读入数据缓冲区中。
索引有什么副作用吗?
(1)索引是有大量数据的时候才建立的,没有大量数据反而会浪费时间,因为索引是使用二叉树建立.
(2)当一个系统查询比较频繁,而新建,修改等操作比较少时,可以创建索引,这样查询的速度会比以前快很多,同时也带来弊端,就是新建或修改等操作时,比没有索引或没有建立覆盖索引时的要慢。
(3)索引并不是越多越好,太多索引会占用很多的索引表空间,甚至比存储一条记录更多。
对于需要频繁新增记录的表,最好不要创建索引,没有索引的表,执行insert、append都很快,有了索引以后,会多一个维护索引的操作,一些大表可能导致insert 速度非常慢。
例子:
建立索引:(在username列建立索引)
ALTER table tableName ADD INDEX indexName(username)
利用explain分析索引: 参考 :http://www.cnblogs.com/qlqwjy/p/7767479.html
1.没有查询username(不用索引)
EXPLAIN SELECT * FROM USER

2.根据username进行比对:(使用索引)
EXPLAIN SELECT * FROM USER WHERE username='qlq'

索引用法:
普通索引 创建索引 这是最基本的索引,它没有任何限制。它有以下几种创建方式: CREATE INDEX indexName ON mytable(username(length)); 如果是CHAR,VARCHAR类型,length可以小于字段实际长度;如果是BLOB和TEXT类型,必须指定 length。 修改表结构(添加索引) ALTER table tableName ADD INDEX indexName(columnName) 创建表的时候直接指定 CREATE TABLE mytable( ID INT NOT NULL, username VARCHAR(16) NOT NULL, INDEX [indexName] (username(length)) ); 删除索引的语法 DROP INDEX [indexName] ON mytable;
ALTER TABLE `exam5`.`questions` DROP KEY `question_type_index`; 唯一索引 它与前面的普通索引类似,不同的就是:索引列的值必须唯一,但允许有空值。如果是组合索引,则列值的组合必须唯一。它有以下几种创建方式: 创建索引 CREATE UNIQUE INDEX indexName ON mytable(username(length)) 修改表结构 ALTER table mytable ADD UNIQUE [indexName] (username(length)) 创建表的时候直接指定 CREATE TABLE mytable( ID INT NOT NULL, username VARCHAR(16) NOT NULL, UNIQUE [indexName] (username(length)) ); 使用ALTER 命令添加和删除索引 有四种方式来添加数据表的索引: ALTER TABLE tbl_name ADD PRIMARY KEY (column_list): 该语句添加一个主键,这意味着索引值必须是唯一的,且不能为NULL。 ALTER TABLE tbl_name ADD UNIQUE index_name (column_list): 这条语句创建索引的值必须是唯一的(除了NULL外,NULL可能会出现多次)。 ALTER TABLE tbl_name ADD INDEX index_name (column_list): 添加普通索引,索引值可出现多次。 ALTER TABLE tbl_name ADD FULLTEXT index_name (column_list):该语句指定了索引为 FULLTEXT ,用于全文索引。 以下实例为在表中添加索引。 mysql> ALTER TABLE testalter_tbl ADD INDEX (c); 你还可以在 ALTER 命令中使用 DROP 子句来删除索引。尝试以下实例删除索引: mysql> ALTER TABLE testalter_tbl DROP INDEX c; 使用 ALTER 命令添加和删除主键 主键只能作用于一个列上,添加主键索引时,你需要确保该主键默认不为空(NOT NULL)。实例如下: mysql> ALTER TABLE testalter_tbl MODIFY i INT NOT NULL; mysql> ALTER TABLE testalter_tbl ADD PRIMARY KEY (i); 你也可以使用 ALTER 命令删除主键: mysql> ALTER TABLE testalter_tbl DROP PRIMARY KEY; 删除主键时只需指定PRIMARY KEY,但在删除索引时,你必须知道索引名。 显示索引信息 你可以使用 SHOW INDEX 命令来列出表中的相关的索引信息。
mysql查看表索引
mysql> show index from tblname;
mysql> show keys from tblname;
· Table
表的名称。
· Non_unique
如果索引不能包括重复词,则为0。如果可以,则为1。
· Key_name
索引的名称。
· Seq_in_index
索引中的列序列号,从1开始。
· Column_name
列名称。
· Collation
列以什么方式存储在索引中。在MySQL中,有值‘A’(升序)或NULL(无分类)。
· Cardinality
索引中唯一值的数目的估计值。通过运行ANALYZE TABLE或myisamchk -a可以更新。基数根据被存储为整数的统计数据来计数,所以即使对于小型表,该值也没有必要是精确的。基数越大,当进行联合时,MySQL使用该索引的机 会就越大。
· Sub_part
如果列只是被部分地编入索引,则为被编入索引的字符的数目。如果整列被编入索引,则为NULL。
· Packed
指示关键字如何被压缩。如果没有被压缩,则为NULL。
· Null
如果列含有NULL,则含有YES。如果没有,则该列含有NO。
· Index_type
用过的索引方法(BTREE, FULLTEXT, HASH, RTREE)。
· Comment
参考:http://www.jb51.net/article/73372.htm
自己的实践:
1.单列建立索引
表名 questions
结构:
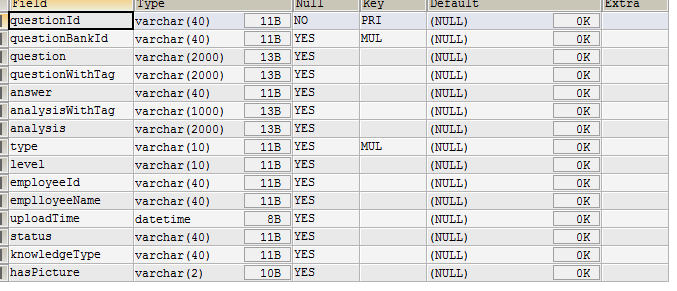
未建立索引
查看一个数据量非常大的试题表,根据试题的类型查:
SELECT * FROM questions WHERE TYPE='单选题'
结果:花费1062ms
/*[15:03:40][1062 ms]*/ SELECT * FROM questions WHERE TYPE='单选题' LIMIT 0, 1000;
用explain解释语句之后:
EXPLAIN SELECT * FROM questions WHERE TYPE='单选题'
结果:可以简单的看到一些参数,扫描了7134行,命中率大概为10%.

建立索引
在type这一列建立索引
ALTER TABLE questions ADD INDEX index_ques_type(TYPE)
再次用explain分析执行语句
EXPLAIN SELECT * FROM questions WHERE TYPE='单选题'
结果: 扫描的行数明显减少,且命中率明显上升

2.建立组合索引
(1)未加索引
SELECT *
FROM questions
WHERE TYPE = '单选题'
AND questionBankId = '40b7fedfbd1c4cc680d93782a033a518'
结果:

explain解释执行
EXPLAIN
SELECT *
FROM questions
WHERE TYPE = '单选题'
AND questionBankId = '40b7fedfbd1c4cc680d93782a033a518'

(2)建立多列索引
ALTER TABLE `exam5`.`questions` ADD INDEX `index_duolie` (`questionBankId`, `type`)
(3) 查询:(速度明显提高)
SELECT * FROM questions WHERE questionBankId = '40b7fedfbd1c4cc680d93782a033a518' AND TYPE = '单选题'

explain解释语句(使用了索引)
EXPLAIN
SELECT *
FROM questions
WHERE
questionBankId = '40b7fedfbd1c4cc680d93782a033a518' AND TYPE = '单选题'

(4)查看索引
SHOW INDEX FROM questions

(5)使用单列索引中的一列
1.只使用questionBankId 这一列看到查询时使用了索引
EXPLAIN SELECT * FROM questions WHERE questionBankId = '40b7fedfbd1c4cc680d93782a033a518'

2.只使用type这一列没有使用索引
EXPLAIN SELECT * FROM questions WHERE TYPE = '单选题'

3 type和questionBankId交换位置使用索引
EXPLAIN SELECT * FROM questions WHERE TYPE = '单选题' AND questionBankId = '40b7fedfbd1c4cc680d93782a033a518'

总结:对于单列索引,使用where条件就可以进行查询
对于多列索引(A,B),如果where中只有A可以起到作用,只有B不会使用索引,A、B都有会使用索引,也就是在有A的条件下才会使用索引。
参考: