1 requests.post( 2 url='', 3 params={'k1':'v1','k2':'v2'}, 4 cookies={}, 5 headers={}, 6 data={}, 7 json={}, 8 ) 9 #data和json都是传送数据,跟请求头需要一直,默认是跟data一组,需要json传送,headers={‘content-type’:'application/json'}
爬虫入门
web 微信
-轮询 定时几秒刷新一次(client不停地发)
-长轮询 hang助请求,无消息,超时断开,客户端以及发请求 (比如web微信qq)
有消息,立即返回 (http协议)
-websocket
爬虫框架scrapy
关于安装
Linux
pip3 install scrapyWindows a. pip3 install wheel python3的依赖库 b. 下载twisted http://www.lfd.uci.edu/~gohlke/pythonlibs/#twisted python3 scrapy的依赖库 c. 进入下载目录,执行 pip3 install Twisted‑17.1.0‑cp35‑cp35m‑win_amd64.whl (注意版本号其中的35就是python3.5需要跟自己的一起,还有就是操作系统) d. pip3 install scrapy e. 下载并安装pywin32:https://sourceforge.net/projects/pywin32/files/3、运行
进入project_name目录,运行命令
scrapy crawl spider_name(爬虫名name) --nolog (不显示日志)
注意scrapy url去重request(dont_filter=True)
爬虫.py前
import sys,os sys.stdout=io.TextIOWrapper(sys.stdout.buffer,encoding='gb18030') #解决编码问题(response.content二进制-responbse.text(字符)不能正常显示)
选择器
Request是一个封装用户请求的类,在回调函数中yield该对象表示继续访问
HtmlXpathSelector用于结构化HTML代码并提供选择器功能 已被弃用(目前用Selector)
hxs = Selector(response) #selector中extract()提取出的是list类型,extract_first()提取出的是unicode类型
link_id_list = hxs.xpath('//a’).extract() #extract()提取,不然是个对象
xpath语法 //a 表示当前文档中的后代a标签 (//开始就是冲整个文档开始, /表示儿子代)
//a[2]当前文档中的所有a标签索引位2的哪一个 同理[@id]表示包换属性id (属性前面必须有@)
//a[@id="i1"] 也可以赋值
BigNode/Node[last()] //取出BigNode路径下最后一个Node节点
Node[not(@class)] //不含class属性的node节点
Node[contains(text(),a)] //文本包含字符串a的node节点
Node[count(span)=2] //包含两个span节点的node节点
Node.xpath('string(.)')//提取出Node节点下除去标签的所有文本
hxs).xpath('//a[re:test(@id, "id+")]/@href').extract() #正则固定格式(匹配a标签下的id是i加数字的,获取他的href属性)
1 import asyncio #python3.3以后引入的异步 3 4 @asyncio.coroutine 5 def fetch_async(host, url='/'): 6 print(host, url) 7 reader, writer = yield from asyncio.open_connection(host, 80) #打开连接 8 9 request_header_content = """GET %s HTTP/1.0 Host: %s ""请求体" % (url, host,) #仿制请求头 10 request_header_content = bytes(request_header_content, encoding='utf-8') 11 12 writer.write(request_header_content) 13 yield from writer.drain() #发送数据 14 text = yield from reader.read() #接受response等,这里是接受reader.read()返回值 15 print(host, url, text) 16 writer.close() 17 18 tasks = [ #添加任务 19 fetch_async('www.cnblogs.com', '/wupeiqi/'), 20 fetch_async('dig.chouti.com', '/pic/show?nid=4073644713430508&lid=10273091') 21 ] 22 23 loop = asyncio.get_event_loop() 24 results = loop.run_until_complete(asyncio.gather(*tasks)) 25 loop.close()


1 import gevent 2 3 import requests 4 from gevent import monkey 5 6 monkey.patch_all() #内部socket装换了gevent.socket,(set blocking = Fale变成非阻塞) 7 8 9 def fetch_async(method, url, req_kwargs): 10 print(method, url, req_kwargs) 11 response = requests.request(method=method, url=url, **req_kwargs) 12 print(response.url, response.content) 13 14 # ##### 发送请求 ##### 15 gevent.joinall([ 16 gevent.spawn(fetch_async, method='get', url='https://www.python.org/', req_kwargs={}), 17 gevent.spawn(fetch_async, method='get', url='https://www.yahoo.com/', req_kwargs={}), 18 gevent.spawn(fetch_async, method='get', url='https://github.com/', req_kwargs={}), 19 ]) 20 21 # ##### 发送请求(协程池控制最大协程数量) ##### 22 # from gevent.pool import Pool 23 # pool = Pool(None) 24 # gevent.joinall([ 25 # pool.spawn(fetch_async, method='get', url='https://www.python.org/', req_kwargs={}), 26 # pool.spawn(fetch_async, method='get', url='https://www.yahoo.com/', req_kwargs={}), 27 # pool.spawn(fetch_async, method='get', url='https://www.github.com/', req_kwargs={}), 28 # ]) 29 30 4.gevent + requests
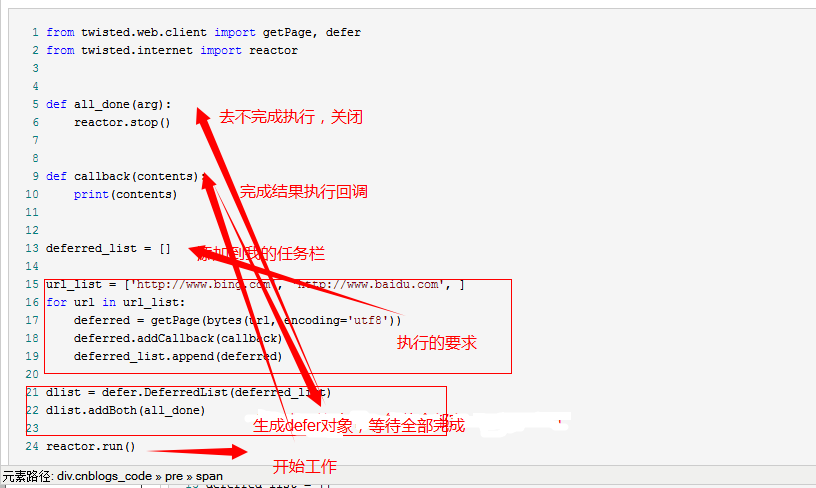
备注 异步非阻塞 优先twisted >gevent+requests>asynio+requests连接地址 http://www.cnblogs.com/wupeiqi/articles/6229292.html
scrapy默认使用 scrapy.dupefilter.RFPDupeFilter 进行去重,相关配置有:
DUPEFILTER_CLASS = 'scrapy.dupefilter.RFPDupeFilter' #可以自定制(DUPEFILTER_CLASS = 'scrapy.自定义的模块') 参考原模块
DUPEFILTER_DEBUG = False #下面两个配合使用,记录日志 JOBDIR = "保存范文记录的日志路径,如:/root/" # 最终路径为 /root/requests.seen