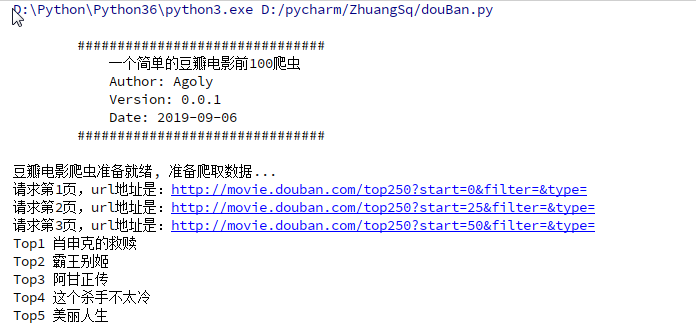
# -*- coding:utf-8 -*- """ 一个简单的Python爬虫, 用于抓取豆瓣电影Top前250的电影的名称 Language: Python3.6 """ import re import urllib.request import urllib.error import time #import urllib2 import ssl ssl._create_default_https_context = ssl._create_unverified_context class DouBanSpider(object): """类的简要说明 本类主要用于抓取豆瓣前100的电影名称 Attributes: page: 用于表示当前所处的抓取页面 cur_url: 用于表示当前争取抓取页面的url datas: 存储处理好的抓取到的电影名称 _top_num: 用于记录当前的top号码 """ def __init__(self): self.page = 1 self.cur_url = "http://movie.douban.com/top250?start={page}&filter=&type=" self.datas = [] self._top_num = 1 print("豆瓣电影爬虫准备就绪, 准备爬取数据...") def get_page(self, cur_page): """ 根据当前页码爬取网页HTML Args: cur_page: 表示当前所抓取的网站页码 Returns: 返回抓取到整个页面的HTML(unicode编码) Raises: URLError:url引发的异常 """ url = self.cur_url time.sleep(3) try: #print(cur_page) page = (cur_page - 1) * 25 #print(page) url = url.format(page=page) headers = { 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.100 Safari/537.36' } request = urllib.request.Request(url, headers=headers) my_page = urllib.request.urlopen(request).read().decode('utf-8') print("请求第{}页,url地址是:{}".format(cur_page,url)) #print(my_page) #urllib.error.URLError #urllib.request.urlopen.URLError except urllib.error.URLError as e: if hasattr(e, "code"): print("The server couldn't fulfill the request.") print("Error code: %s" % e.code) elif hasattr(e, "reason"): print("We failed to reach a server. Please check your url and read the Reason") print("Reason: %s" % e.reason) return my_page def find_title(self, my_page): """ 通过返回的整个网页HTML, 正则匹配前100的电影名称 Args: my_page: 传入页面的HTML文本用于正则匹配 """ temp_data = [] #<span class="title">.*</span> #class="">[s]+<span class="title">(.*?)</span> #<span.*?class="title">(.*?)</span> movie_items = re.findall(r'<span.*?class="title">(.*?)</span>', my_page, re.S) for index, item in enumerate(movie_items): if item.find(" ") == -1: temp_data.append("Top" + str(self._top_num) + " " + item) self._top_num += 1 self.datas.extend(temp_data) def start_spider(self): """ 爬虫入口, 并控制爬虫抓取页面的范围 """ while self.page <= 3: my_page = self.get_page(self.page) self.find_title(my_page) self.page += 1 def main(): print( """ ###################################### 一个简单的豆瓣电影前100爬虫 Author: Agoly Version: Python3.6 Date: 2019-09-06 ###################################### """) my_spider = DouBanSpider() my_spider.start_spider() for item in my_spider.datas: print(item) print("豆瓣爬虫爬取结束...") if __name__ == '__main__': main()