一、何为分布式一致性
C(一致性)A(高可用)P(分区容错性)理论:在满足CP的基础上尽可能提高可用性。
- 一致性(Consistency) : 客户端知道一系列的操作都会同时发生(生效)
- 可用性(Availability) : 每个操作都必须以可预期的响应结束
- 分区容错性(Partition tolerance) : 即使出现单个组件无法可用,操作依然可以完成
何为一致性:一致性问题就是相互独立的节点之间如何达成一项决议的问题。分布式系统中,进行数据库事务提交(commit transaction)、Leader选举、序列号生成等都会遇到一致性问题(多数者理论,法院提案选举)。
一致性又分为弱一致性(最终一致性,即最终结果对了就行)和强一致性。
弱一致性有DNS、Gossip实现。
强一致性可分为两类:
1.主从同步,可参考Mysql主从同步,Master接受写请求,复制日志到slave,Master等待,直到所有从库返回。但是如果一个节点失败,Master就会阻塞,导致整个集群不可用。
2.多数派,每次写都保证写入大于N/2个节点,每次读保证从大于N/2个节点中读。相关算法:Paxos、Raft(multi-paxos)、ZAB(multi-paxos)
什么样的系统才能满足一致性要求:
1.全认同:所有节点都认同一个结果。
2.值合法:结果必须由节点内部提出。
3.可结束:决议过程在一定时间内可结束。
分布式系统面临的问题:
1.消息会出现延时、丢失,节点消息间不能做到同步有序。
2.节点宕机或者出现逻辑问题。
3.网络分化,即将节点分区。
二、2PC-tow phase commit
1.角色划分:
coordinator(协调者):提出提议的节点。
participants/cohorts(参与者):参与决议的节点。
2.两阶段划分:
在阶段一中,协调者发起一个提议,分别询问参与者是否接受。

在阶段二中,协调者根据参与者的反馈,提交或者终止事务。如果参与者全部同意则提交事务,只要有一个参与者不同意就终止事务。
3.存在问题
协调者如果发起提议后宕机,那么参与者会进入阻塞状态,等待参与者回应完成此次决议。此时需要一个协调者备份角色解决此问题,协调者宕机一段时间后,协调者备份接替协调者的工作,通过问询参与者的状态决定阶段2是否提交事务。这也要求协调者/参与者记录历史状态,以备协调者备份对参与者查询。重新恢复状态。
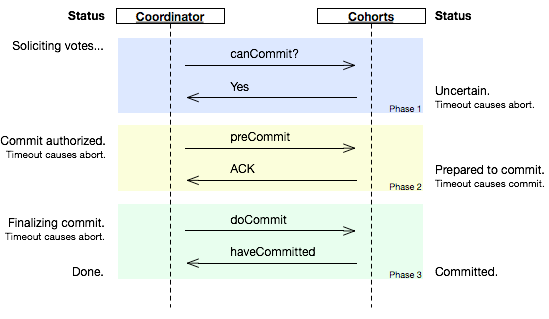
三、3PC-three phase commit
三阶段提交增加了一个准备提交(prepare to commit)阶段解决patticpant宕机问题。
具体过程如下图:
四、Paxos
4.1 Basic Paxos
4.1.1 角色划分
Client:系统外部角色。请求发起者——民众。
Proposer:接受Client请求,向集群提出提议(propose),并在冲突发生时,起到冲突调解的作用。像议员,替民众提出议案。
Acceptor:提议投票和接受者,只有在形成法定人数(一般为多数派)时,提议才会最终被接受。像国会。
Learer:提议接受者,backup-备份,对集群一致性没什么影响。像记录员。
4.1.2 步骤
阶段一
Prepare:proposer提出一个**提议,编号为N,**此N大于这个proposer之前提出的提案编号。请求acceptors的quorum接受。
Promise:如果N大于此acceptor之前接受的任何提案编号则接受(保证当前提案是最新的一个),否则拒绝。
阶段二
Accept:如果达到了多数派(多数派),proposer会发出 accept请求,此请求包含提案编号N,以及提案内容。
Accepted:如果此acceptor在此期间没有收到任何编号大于N的提案(保证处理提案期间没有新的提案),则接受此提案内容,否则忽略。
处理请求的节点 参与投票的三个节点 相当于复制节点
Client Proposer Acceptor Learner Va、Vb、Vc看作三台实例 | | | | | | | X-------->| | | | | | Request //client通过processer向整个分布式系统发出请求 | X--------->|->|->| | | 4.2.1 Prepare(1) // 好的我们同意准备处理请求 | |<---------X--X--X | | 4.2.2 Promise(1,{Va,Vb,Vc}) // 提案最新,接受 | X--------->|->|->| | | 4.2.3 Accept!(1,V) // 达到了多数派,接受请求 // acceptor写入数据 | |<---------X--X--X------>|->| 4.2.4 Accepted(1,V) //此期间没有收到比1大的提案,接受 //Leaner写入 |<---------------------------------X--X Response | | | | | | |
如果一个Acceptor宕机,只要满足多数派则可继续执行。
Client Proposer Acceptor Learner | | | | | | | X-------->| | | | | | Request | X--------->|->|->| | | Prepare(1) | | | | ! | | !! FAIL !! //此时C宕机 | |<---------X--X | | Promise(1,{Va, Vb, null}) | X--------->|->| | | Accept!(1,V) | |<---------X--X--------->|->| Accepted(1,V) |<---------------------------------X--X Response | | | | | |
如果Learner宕机,可继续执行成功。
Client Proposer Acceptor Learner | | | | | | | X-------->| | | | | | Request | X--------->|->|->| | | Prepare(1) | |<---------X--X--X | | Promise(1,{Va,Vb,Vc}) | X--------->|->|->| | | Accept!(1,V) | |<---------X--X--X------>|->| Accepted(1,V) | | | | | | ! !! FAIL !! |<---------------------------------X Response | | | | | |
如果一个Proposser在提出提议后宕机,会选出新的Leader接收Accepor反馈。
Client Proposer Acceptor Learner | | | | | | | X----->| | | | | | Request | X------------>|->|->| | | Prepare(1) | |<------------X--X--X | | Promise(1,{Va, Vb, Vc}) | | | | | | | | | | | | | | !! Leader fails during broadcast !! | X------------>| | | | | Accept!(1,V) | ! | | | | | | | | | | | | !! NEW LEADER !! //换一个新的 | X--------->|->|->| | | Prepare(2) //换一个提案编号,上一个已经用过了 | |<---------X--X--X | | Promise(2,{V, null, null}) | X--------->|->|->| | | Accept!(2,V) | |<---------X--X--X------>|->| Accepted(2,V) |<---------------------------------X--X Response | | | | | | |
4.1.3 存在问题
4.1.3.1 活锁和dueing(决斗)
多个Prosesser提议者都认为自己是领导者,例如Prosesser1发出提议1之后,Prosesser2也发出提议2,此时Prosesser1的提议就会被拒绝,会再次发出提议3,然后Prosesser2的提议2就会被拒绝发出提议4、、、、
Client Leader Acceptor Learner | | | | | | | X----->| | | | | | Request | X------------>|->|->| | | Prepare(1) | |<------------X--X--X | | Promise(1,{null,null,null}) | ! | | | | | !! LEADER FAILS | | | | | | | !! NEW LEADER (knows last number was 1) | X--------->|->|->| | | Prepare(2) | |<---------X--X--X | | Promise(2,{null,null,null}) | | | | | | | | !! OLD LEADER recovers | | | | | | | | !! OLD LEADER tries 2, denied | X------------>|->|->| | | Prepare(2) | |<------------X--X--X | | Nack(2) | | | | | | | | !! OLD LEADER tries 3 | X------------>|->|->| | | Prepare(3) | |<------------X--X--X | | Promise(3,{null,null,null}) | | | | | | | | !! NEW LEADER proposes, denied | | X--------->|->|->| | | Accept!(2,Va) | | |<---------X--X--X | | Nack(3) | | | | | | | | !! NEW LEADER tries 4 | | X--------->|->|->| | | Prepare(4) | | |<---------X--X--X | | Promise(4,{null,null,null}) | | | | | | | | !! OLD LEADER proposes, denied | X------------>|->|->| | | Accept!(3,Vb) | |<------------X--X--X | | Nack(4) | | | | | | | | ... and so on ...
解决办法:如果发生冲突,则Proposer等待一个Random的Timeout(一般几秒)再提交自己的提议。
4.1.3.2 难实现,效率低
Basic Paxos的难度是较为出名的,且不易理解。提交提议、提交提案(日志)内容进行了两轮RTT操作,效率较低。
4.2 Multi Paxos
4.2.1 角色
Leader:唯一的Prosesser,不会有争夺了,所有请求都需经过此Leader。
Client:客户端
Server:服务端
4.2.2 实现过程
Client Proposer Acceptor LearnerLeader | | | | | | | --- First Request --- X-------->| | | | | | Request | X--------->|->|->| | | Prepare(N) N是Leader版本,需要竞选一次,如果后面期间Leader挂了,再选一个 | |<---------X--X--X | | Promise(N,I,{Va,Vb,Vc}) | X--------->|->|->| | | Accept!(N,I,V) | |<---------X--X--X------>|->| Accepted(N,I,V) |<---------------------------------X--X Response | | | | | | |
------------------------------------------------------------------
Client Proposer Acceptor Learner
| | | | | | | --- Following Requests --- 下面请求不用在选Leader
X-------->| | | | | | Request
| X--------->|->|->| | | Accept!(N,I+1,W)
| |<---------X--X--X------>|->| Accepted(N,I+1,W)
|<---------------------------------X--X Response
| | | | | | |
----------------------------进一步简化--------------------------------------
直接由Server内部进行选举leader
Client Servers
X-------->| | | Request
| X->|->| Accept!(N,I+1,W)
| X<>X<>X Accepted(N,I+1)
|<--------X | | Response
| | | |五、Raft
动画显示:http://thesecretlivesofdata.com/raft/ https://raft.github.io/
5.1 角色
Leader:主节点,整个集群只有一个Leader,所有的写请求都通过Leader发送给Follower;在每一个Leader的任期期间,都有唯一表示该任期的Term。
Follower:从节点(服从角色);
Candidate:在Leader消息发送失败或宕机,整集群没有Leader时,此时Follower接收Leader的心跳包失败,则Follwer开始竞选Leader时,它们的身份是Candidate。Candidate只是个中间状态,不会长期存在。
5.2 基本过程
5.2.1 Leader Election_选举☆☆☆☆☆☆
集群启动或Leader的心跳包消息无法发送给Follower时,触发 Leader Election——选主 操作。
每一个节点都有一个随机timeout,当到了timeout时间还没有收到Leader的心跳包的话,那么当前节点就会向其他节点发送一个竞选Leader的请求。如果多数同意(此时其他节点的timeout还没到,例如三个节点tieout分别为 1s, 2s,3s,一号节点1s刷新一次,肯定是他先探测到Leader宕机,因此它第一个竞选Leader,成为第一个候选人),那么当前节点成功竞选为leader,向其他节点发送心跳包。
5.2.2 Log Replication_复制数据 (两阶段提交)☆☆☆☆☆
1、所有的写请求都要经过Leader;
2、Leader将写请求log携带在心跳包中发送给Follower;
3. 节点保存log并未执行,回复Leader;
4、当Leader收到多数派回复的消息后,则先自己提交写操作,同时发送Commit请求给Follower;
5.3 Leader选举Safety保证_安全保障
1、Leader宕机感知:
a、Raft通过TimeOut来保证Follower能正确感知Leader宕机或消息丢失的事件,并触发Follower竞选Leader;
b、Leader需要给Follower发送心跳包(heartbeats),数据也是携带在心跳包中发送给Follower的;
2、选主平票情况--两个节点Timeout同时到期,都是第一候选者
Leader Election时平票情况下,则两个Candidates会产生一个随机的Timewait,继续发送下一个竞选消息。
3、脑裂(大小集群)情况:看动画演示
五个节点集群,分成了3+2,每个集群都有一个Leader,造成了整个集群有两个Leader。当对两个Leader进行写操作时:
小集群(2节点)由于没有得到多数派的回复(只收到一个),写操作失败;
大集群会发生重新选主的过程,且新Leader拥有自己新的Term(任期),写操作成功;
当小集群回到大集群时,由于小集群的Term小于新集群的Term,则同步新集群的信息。
5.3 一致性 = 客户端 + 一致性算法
Client Request操作的三个可能结果:成功、失败、unknown(Timeout)
5.3.1理解unknown(Timeout)
场景:Client写请求,Leader向Follower同步日志,此时集群中有3个节点失败,2个节点存活,结果是? 假设节点为:S1、S2、S3、S4、S5(Leader)
假设S5和S4存活,Client发起 第N次写请求 为 操作I 时,由于Leader没有得到多数派的回复,操作I只被发送到了S4中,此时Leader即会返回Client unknown,因为Leader不知道后面会不会成功将该条日志写入多数派中。
结果1:假设Leader在返回客户端后,宕机的Follower:S1、S2、S3恢复正常,Leader再次发送 第N次写请求——操作I,且得到了多数派的回复,则提交日志,写操作最终结果为成功;
结果2:假设Leader在返回客户端后,此时S5和S4宕机,且S1、S2、S3恢复正常,此时S1、S2、S3触发选主操作,且集群恢复可用,如果此时Client发起
第N+1次请求 为 操作I+1 ,且Client操作成功后 S5、S4恢复正常,则保存在S5、S4中的 操作I 会被删除,S5、S4同步最新的
操作I+1 到本地。则 第N次写请求—操作I 失败;
总结:一致性需要客户端和共识算法(Consensus)来共同保证。
六、ZAB - Zookeeper atomic broadcast protocol
ZAB是Zookeeper内部用到的一致性协议。基本与Raft相同。 在一些名词的叫法上有些区别:如ZAB将某一个leader的周期(任期)称为epoch,而Raft则称为Term。实现上也有些许不同:Raft保证日志连续性,心跳方向为Leader至Follower。ZAB则相反。