一、什么是分库分表
分表
比如你单表都几千万数据了,你确定你能扛住么?绝对不行,单表数据量太大,会极大影响你的 sql 执行的性能,到了后面你的 sql 可能就跑的很慢了。一般来说,就以我的经验来看,单表到几百万的时候,性能就会相对差一些了,你就得分表了。
分表是啥意思?就是把一个表的数据放到多个表中,然后查询的时候你就查一个表。比如按照用户 id 来分表,将一个用户的数据就放在一个表中。然后操作的时候你对一个用户就操作那个表就好了。这样可以控制每个表的数据量在可控的范围内,比如每个表就固定在 200 万以内。
分库
分库是啥意思?就是你一个库一般我们经验而言,最多支撑到并发 2000,一定要扩容了,而且一个健康的单库并发值你最好保持在每秒 1000 左右,不要太大。那么你可以将一个库的数据拆分到多个库中,访问的时候就访问一个库好了。
| # | 分库分表前 | 分库分表后 |
|---|---|---|
| 并发支撑情况 | MySQL 单机部署,扛不住高并发 | MySQL从单机到多机,能承受的并发增加了多倍 |
| 磁盘使用情况 | MySQL 单机磁盘容量几乎撑满 | 拆分为多个库,数据库服务器磁盘使用率大大降低 |
| SQL 执行性能 | 单表数据量太大,SQL 越跑越慢 | 单表数据量减少,SQL 执行效率明显提升 |
二、分库分表方法
1. 垂直拆分
垂直拆分的意思,就是把一个有很多字段的表给拆分成多个表,或者是多个库上去。每个库表的结构都不一样,每个库表都包含部分字段。一般来说,会将较少的访问频率很高的字段放到一个表里去,然后将较多的访问频率很低的字段放到另外一个表里去。因为数据库是有缓存的,你访问频率高的行字段越少,就可以在缓存里缓存更多的行,性能就越好。这个一般在表层面做的较多一些。
2. 水平拆分
水平拆分的意思,就是把一个表的数据给弄到多个库的多个表里去,但是每个库的表结构都一样,只不过每个库表放的数据是不同的,所有库表的数据加起来就是全部数据。水平拆分的意义,就是将数据均匀放更多的库里,然后用多个库来扛更高的并发,还有就是用多个库的存储容量来进行扩容。
三、怎么从单表单库转移到分表分库
1. 停机迁移方案
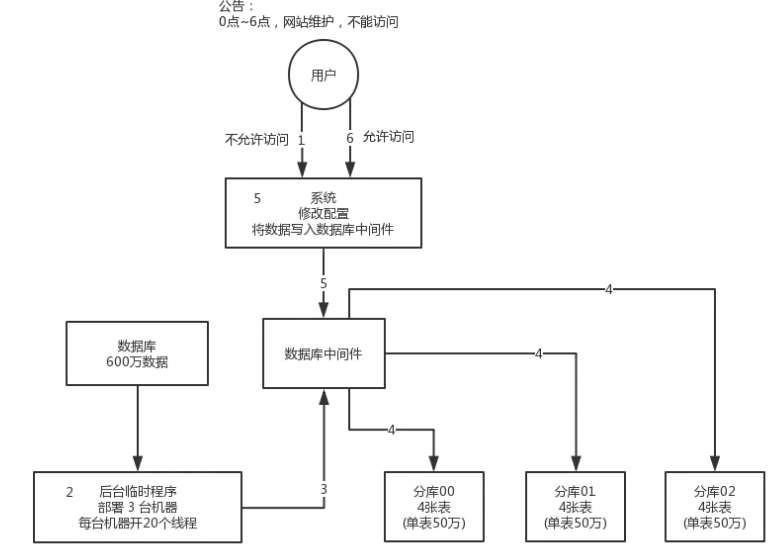
我先给你说一个最 low 的方案,就是很简单,大家伙儿凌晨 12 点开始运维,网站或者 app 挂个公告,说 0 点到早上 6 点进行运维,无法访问。接着到 0 点停机,系统停掉,没有流量写入了,此时老的单库单表数据库静止了。然后你之前得写好一个导数的一次性工具,此时直接跑起来,然后将单库单表的数据哗哗哗读出来,写到分库分表里面去。
导数完了之后,就 ok 了,修改系统的数据库连接配置啥的,包括可能代码和 SQL 也许有修改,那你就用最新的代码,然后直接启动连到新的分库分表上去。验证一下,ok了,完美,大家伸个懒腰,看看看凌晨 4 点钟的北京夜景,打个滴滴回家吧。但是这个方案比较 low,谁都能干,我们来看看高大上一点的方案。
2.双写迁移方案
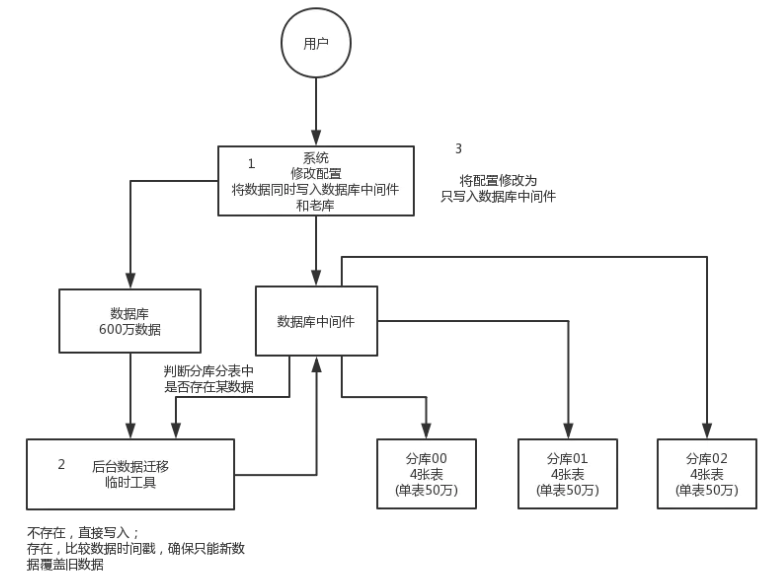
这个是我们常用的一种迁移方案。简单来说,就是在线上系统里面,之前所有写库的地方,增删改操作,除了对老库增删改,都加上对新库的增删改,这就是所谓的双写,同时写俩库,老库和新库。然后系统部署之后,新库数据差太远,用之前说的导数工具,跑起来读老库数据写新库,写的时候要根据 gmt_modified 这类字段判断这条数据最后修改的时间,除非是读出来的数据在新库里没有,或者是比新库的数据新才会写。简单来说,就是不允许用老数据覆盖新数据。导完一轮之后,有可能数据还是存在不一致,那么就程序自动做一轮校验,比对新老库每个表的每条数据,接着如果有不一样的,就针对那些不一样的,从老库读数据再次写。反复循环,直到两个库每个表的数据都完全一致为止。接着当数据完全一致了,就 ok 了,基于仅仅使用分库分表的最新代码,重新部署一次,不就仅仅基于分库分表在操作了么,还没有几个小时的停机时间,很稳。所以现在基本玩儿数据迁移之类的,都是这么干的。
四、如何设一可动态扩容/缩容的分库分表方案
对于分库分表来说,主要是面对以下问题:
- 选择一个数据库中间件,调研、学习、测试;
- 设计你的分库分表的一个方案,你要分成多少个库,每个库分成多少个表,比如 3 个库,每个库 4 个表;
- 基于选择好的数据库中间件,以及在测试环境建立好的分库分表的环境,然后测试一下能否正常进行分库分表的读写;
- 完成单库单表到分库分表的迁移,双写方案;
- 线上系统开始基于分库分表对外提供服务;
- 扩容了,扩容成 6 个库,每个库需要 12 个表,你怎么来增加更多库和表呢?
这个是你必须面对的一个事儿,就是你已经弄好分库分表方案了,然后一堆库和表都建好了,基于分库分表中间件的代码开发啥的都好了,测试都 ok 了,数据能均匀分布到各个库和各个表里去,而且接着你还通过双写的方案咔嚓一下上了系统,已经直接基于分库分表方案在搞了。那么现在问题来了,你现在这些库和表又支撑不住了,要继续扩容咋办?这个可能就是说你的每个库的容量又快满了,或者是你的表数据量又太大了,也可能是你每个库的写并发太高了,你得继续扩容。
1. 停机扩容 不推荐
2. 优化方案
一开始上来就是 32 个库,每个库 32 个表,那么总共是 1024 张表。
我可以告诉各位同学,这个分法,第一,基本上国内的互联网肯定都是够用了,第二,无论是并发支撑还是数据量支撑都没问题。
每个库正常承载的写入并发量是 1000,那么 32 个库就可以承载32 * 1000 = 32000 的写并发,如果每个库承载 1500 的写并发,32 * 1500 = 48000 的写并发,接近 5万/s 的写入并发,前面再加一个MQ,削峰,每秒写入 MQ 8 万条数据,每秒消费 5 万条数据。
有些除非是国内排名非常靠前的这些公司,他们的最核心的系统的数据库,可能会出现几百台数据库的这么一个规模,128个库,256个库,512个库。
1024 张表,假设每个表放 500 万数据,在 MySQL 里可以放 50 亿条数据。
每秒的 5 万写并发,总共 50 亿条数据,对于国内大部分的互联网公司来说,其实一般来说都够了。
谈分库分表的扩容,第一次分库分表,就一次性给他分个够,32 个库,1024 张表,可能对大部分的中小型互联网公司来说,已经可以支撑好几年了。
一个实践是利用 32 * 32 来分库分表,即分为 32 个库,每个库里一个表分为 32 张表。一共就是 1024 张表。根据某个 id 先根据 32 取模路由到库,再根据 32 取模路由到库里的表。
| orderId | id % 32 (库) | id / 32 % 32 (表) |
|---|---|---|
| 259 | 3 | 8 |
| 1189 | 5 | 5 |
| 352 | 0 | 11 |
| 4593 | 17 | 15 |
刚开始的时候,这个库可能就是逻辑库,建在一个数据库上的,就是一个mysql服务器可能建了 n 个库,比如 32 个库。后面如果要拆分,就是不断在库和 mysql 服务器之间做迁移就可以了。然后系统配合改一下配置即可。
比如说最多可以扩展到32个数据库服务器,每个数据库服务器是一个库。如果还是不够?最多可以扩展到 1024 个数据库服务器,每个数据库服务器上面一个库一个表。因为最多是1024个表。
这么搞,是不用自己写代码做数据迁移的,都交给 dba 来搞好了,但是 dba 确实是需要做一些库表迁移的工作,但是总比你自己写代码,然后抽数据导数据来的效率高得多吧。
哪怕是要减少库的数量,也很简单,其实说白了就是按倍数缩容就可以了,然后修改一下路由规则。
这里对步骤做一个总结:
- 设定好几台数据库服务器,每台服务器上几个库,每个库多少个表,推荐是 32库 * 32表,对于大部分公司来说,可能几年都够了。
- 路由的规则,orderId 模 32 = 库,orderId / 32 模 32 = 表
- 扩容的时候,申请增加更多的数据库服务器,装好 mysql,呈倍数扩容,4 台服务器,扩到 8 台服务器,再到 16 台服务器。
- 由 dba 负责将原先数据库服务器的库,迁移到新的数据库服务器上去,库迁移是有一些便捷的工具的。
- 我们这边就是修改一下配置,调整迁移的库所在数据库服务器的地址。
- 重新发布系统,上线,原先的路由规则变都不用变,直接可以基于 n 倍的数据库服务器的资源,继续进行线上系统的提供服务。