一,字符串和列表的转换
1.str中的 join 方法: 把列表转换成字符串
# 将列表转换成字符串. 每个元素之间用_连接
s = '**'.join(['李启政',' 郑强' , '孙福来']) print(s) #s = ["李启政"**"郑强"**"孙福来"]
ss = "李启政**郑强**孙福来" ss.split("**") print(ss)
字符串转化成列表: split()
把列表转化成字符串: join()
s = "_",join('马化腾') print(s) # s = ('马_化_藤')
join (可迭代对象)
2.列表和字典在循环的过程中不能直接删除,与要把要删除的内容记录在新列表中,然后循环新列表,删除字典或者列表.
lst = ["紫云", "大云", "玉溪", "紫钻","a","b"]
lst.clear()
new_lst = [] # 准备要删除的信息
for el in lst: # 有一个变量来记录当前循环的位置
new_lst.append(el)
# 循环新列表, 删除老列表
for el in new_lst:
lst.remove(el)
#
# # 删除的时候, 发现. 剩余了一些内容. 原因是内部的索引在改变.
# # 需要把要删除的内容记录下来. 然后循环这个记录. 删除原来的列表
#
# print(lst)
# print(new_lst)
** 列表 清空及删除
例 : lst = ["张国荣", '张铁林', '张国立', "张曼玉", "汪峰"]
(1)删除姓张的
zhangs = [] for el in lst: if el.startswith("张"): zhangs.append(el) for el in zhangs: lst.remove(el) print(lst)
(2)记录姓张的
zhangs = [] for el in lst: if el.startswith("张"): zhangs.append(el) for el in zhangs: lst.remove(el) print(zhangs)
** 字典 清空及删除
例 : dic = {"提莫":"冯提莫", "发姐":"陈一发儿", "55开":"卢本伟"}
dic = {"提莫":"冯提莫", "发姐":"陈一发儿", "55开":"卢本伟"}
lst = []
for k in dic:
lst.append(k)
for el in lst:
dic.pop(el)
print(dic)
综上,列表和字典都不能在循环的时候进行删除,字典在循环的时候不能改变大小长度.
3.fromkeys()
(1)返回新字典,对原字典没有影响
(2)后面的value,是多个key共享的一个value.
例: dic = {"apple":"苹果", "banana":"香蕉"}
dic = {"apple":"苹果", "banana":"香蕉"}
# 返回新字典. 和原来的没关系
ret = dic.fromkeys("orange", "橘子") # 直接用字典去访问fromkeys不会对字典产生影响
ret = dict.fromkeys("abc",["哈哈","呵呵", "吼吼"]) # fromkeys直接使用类名进行访问
print(ret)
a = ["哈哈","呵呵", "吼吼"]
ret = dict.fromkeys("abc", a) # fromkeys直接使用类名进行访问
a.append("嘻嘻")
print(ret)
二.set集合
特点: 无序,不重复,元素必须可哈希(不可变).
作用: 去重复
本身是可变类型,有增删改查操作.
frozenset()冻结的集合, 不可改变,可哈希的.
set 去重复
例: s = {"周杰伦", "的老婆","叫昆凌", (1,2,3), "周杰伦"}
s = {"周杰伦", "的老婆","叫昆凌", (1,2,3), "周杰伦"}
s = set(s)
print(s) # s = {"周杰伦", "的老婆","叫昆凌", (1,2,3)}
set 把列表转换成集合. 进行去重复 ,再把集合转换回列表.
例: lst = [11,5,4,1,2,5,4,1,25,2,1,4,5,5]
lst = [11,5,4,1,2,5,4,1,25,2,1,4,5,5] s = set(lst) # 把列表转换成集合. 进行去重复 lst = list(s) # 把集合转换回列表. print(lst) #lst = [1,2,4,5,11,25]
集合本身是可变的数据类型, 不可哈希, 有增删改查操作,
例: s = {"刘嘉玲", '关之琳', "王祖贤"}
s = {"刘嘉玲", '关之琳', "王祖贤"}
s.update("麻花藤") # 迭代更新
print(s) #{'麻', '藤', '刘嘉玲', '关之琳', '花', '王祖贤'}
集合中的元素必须是可哈希的 .不重复的. 可以去重.
集合的增删改查
1,增: add : 重复的内容不会被添加到set集合中 和 update : 迭代更新
s = {"刘嘉玲", '关之琳', "王祖贤"}
s.add("郑裕玲")
print(s)
s.add("郑裕玲") # 重复的内容不会被添加到set集合中
print(s)
s = {"刘嘉玲", '关之琳', "王祖贤"}
s.update("麻花藤") # 迭代更新
print(s)
s.update(["张曼玉", "李若彤","李若彤"])
print(s)
2.删: pop() : 随机删除(随机弹出一个) remove() :直接删除元素 clear():清空set集合.需要注意的是set集合如果是空的. 打印出来是set() 因为要和 dict区分的.
s = {"刘嘉玲", '关之琳', "王祖贤","张曼玉", "李若彤"}
item = s.pop() # 随机弹出一个.
print(s)
print(item)
s.remove("关之琳") # 直接删除元素
# s.remove("马虎疼") # 不存在这个元素. 删除会报错
print(s)
s.clear() # 清空set集合.需要注意的是set集合如果是空的. 打印出来是set() 因为要和
dict区分的.
print(s) # set()
3.改:set集合中的数据没有索引. 也没有办法去定位一个元素. 所以没有办法进⾏直接修改. 我们可以采取先删除后添加的方式来完成修改操作
s = {"刘嘉玲", '关之琳', "王祖贤","张曼玉", "李若彤"}
# 把刘嘉玲改成赵本山
s.remove("刘嘉玲")
s.add("赵本山")
print(s)
4.查: set是一个可迭代对象. 所以可以进行for循环
for el in s: print(el)
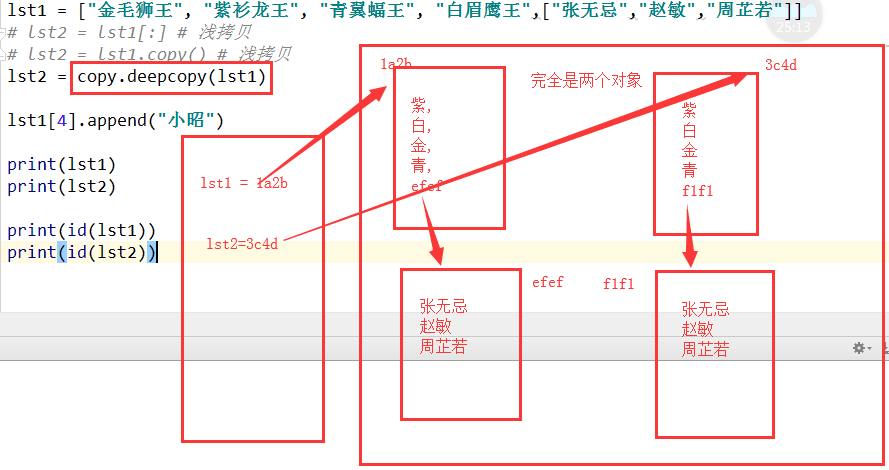
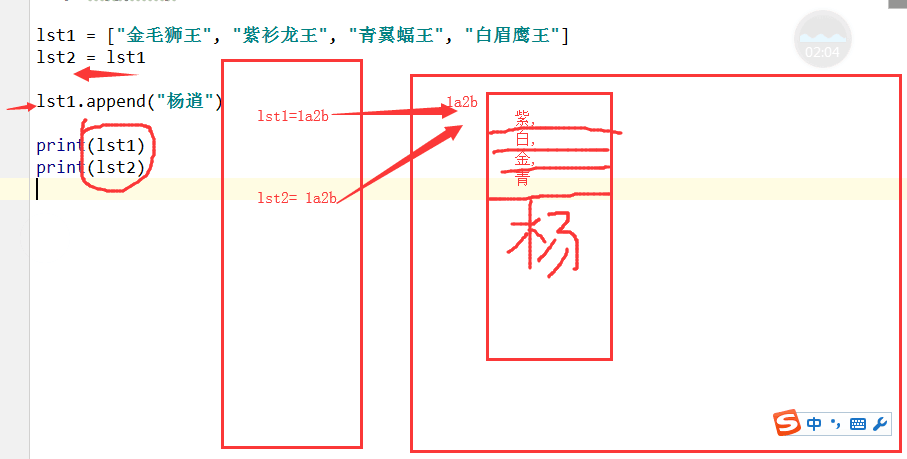
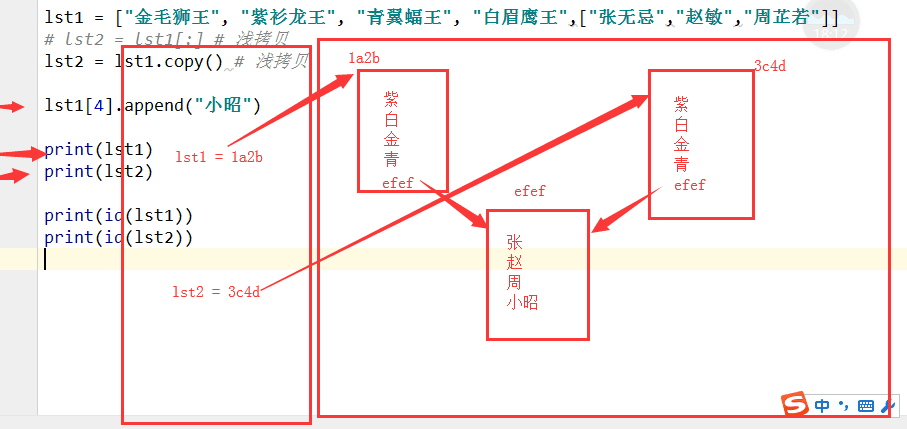
三.深浅拷贝(难点)
1. 赋值,没有创建新对象,共用一个对象
2.浅拷贝,拷贝第一层内容, [ : ]或 copy( )
3.深拷贝,拷贝所有内容,包括内部的所有.
例: lst1 = ["金毛狮王", "紫衫龙王", "青翼蝠王", "白眉鹰王",["张无忌","赵敏","周芷若"]]
浅拷贝
lst1 = ["金毛狮王", "紫衫龙王", "青翼蝠王", "白眉鹰王",["张无忌","赵敏","周芷若"]] lst2 = lst1[:] # 浅拷贝 lst2 = lst1.copy() # 浅拷贝 lst1[4].append("小昭") print(lst1) print(lst2) print(id(lst1[4])) print(id(lst2[4]))
#['金毛狮王', '紫衫龙王', '青翼蝠王', '白眉鹰王', ['张无忌', '赵敏', '周芷若', '小昭']]
['金毛狮王', '紫衫龙王', '青翼蝠王', '白眉鹰王', ['张无忌', '赵敏', '周芷若', '小昭']]
地址一样 40206664
40206664
深拷贝
lst1 = ["金毛狮王", "紫衫龙王", "青翼蝠王", "白眉鹰王",["张无忌","赵敏","周芷若"]] lst1[4].append("小昭")
lst2 = copy.deepcopy(lst1) # 深拷贝
print(lst1) print(lst2) print(id(lst1[4])) print(id(lst2[4]))
#['金毛狮王', '紫衫龙王', '青翼蝠王', '白眉鹰王', ['张无忌', '赵敏', '周芷若', '小昭']]
['金毛狮王', '紫衫龙王', '青翼蝠王', '白眉鹰王', ['张无忌', '赵敏', '周芷若', '小昭']]
地址不同 42238280
42239688